

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about two techniques for solving search problems in AI: Graph Search (GS) and Tree-Like Search (TLS) strategies.
Search problems are those in which an AI agent aims to find the optimal sequence of actions that lead the agent from its start state to one of the goal states. All the possible states an agent can be in, along with the links that show which action transforms one state to another, constitute a state graph.
A state can be anything, depending on the problem: a point on a 2D map, the order in which to assemble the pieces of a product, an arrangement of the chess pieces on the board, and so on.
Search algorithms differ by the order in which they visit (reach) the states in the state graph following the edges between them. For some algorithms, that order creates a tree superimposed over the state graph and whose root is the start state. We call that tree a search tree and will consider only the algorithms that grow it.
But, how do we grow a search tree in those algorithms? Whenever we reach a state, we create a node we mark with that state. Later, we insert the node into the tree as a child of the node from whose state we reached it.
We see the differences between the states in the state graph and nodes in the search tree. Each state appears in the graph only once. But, it may appear in the tree multiple times. That’s because, in the general case, there may be more than one path from the start state to any other state in the graph. So, different search-tree nodes marked with the same state represent different paths from the start to that state.
There lies the difference between the tree-like and the graph search strategies. The latter avoids repeating the states in the search tree.
To see how the graph search strategy does that, we should first differentiate between reaching and expanding a state. We reach a state when we identify a path from the start state to it. But, we say that we expanded it if we had followed all its outward edges and reached all its children.
So, we can also think of a search as a sequence of expansions, and we first have to reach a state before expanding it. Therefore, we have to keep track of the reached but unexpanded states because we can expand only them. We call the set of such states the frontier. But, we have to be careful. Since there may be multiple paths to any state in general, we can reach a state more than once. Each time we do that, we get a new candidate node for the tree.
For those reasons, we conclude that a search strategy has two components:
GS has one rule regarding the frontier:
Don’t add a node if its state has already been expanded or a node pointing to the same state is already in the frontier.
All the algorithms that conform to it belong to the class of graph-search methods. The generic pseudocode of GS is:
algorithm GenericGraphSearch(start_state, goal_test, state_graph, choose_one, phi):
// INPUT
// start_state = the initial state
// goal_test = the function to test if a state is a goal state
// state_graph = the graph of states and transitions
// choose_one = the function to choose and remove a node for expansion
// phi = the algorithm-specific conditions for adding a node to the frontier
// OUTPUT
// Returns a path to a goal state if one is reachable from the start state.
// Otherwise, returns failure.
frontier <- initialize the frontier to contain only the start node
reached <- make a lookup table that will contain states
while frontier is not empty:
// choose and remove a node from frontier
u <- choose_one(frontier)
if u passes goal_test:
return u
for v in expand(u):
if (v.state not in reached) and phi(v):
Insert v.state into reached
Add v to frontier
return failureWe should note that there may be no algorithm-specific conditions for adding a node to  . In that case,
. In that case,  is a function that always returns
is a function that always returns  .
.
From Algorithm 1, we see that we need a special data structure for nodes. Since a node represents a path to its state, it has to include at least the pointer to the state’s predecessor on the path in question. So, a node should be an object with the following attributes:
In addition, we’d benefit from including these pieces of information as well:
The way we implement  depends on the algorithm “subclassing” the generic form of GS. In UCS, is a min-priority queue, but in DFS, it’s a LIFO queue. The implementation of should be compatible with
depends on the algorithm “subclassing” the generic form of GS. In UCS, is a min-priority queue, but in DFS, it’s a LIFO queue. The implementation of should be compatible with  .
.
There’s also more than one way to implement  . We can use a set or a key-value structure with states as keys and the corresponding nodes as values. Whatever we choose,
. We can use a set or a key-value structure with states as keys and the corresponding nodes as values. Whatever we choose,  should support fast look-ups and inserts (and deletions and updates in the cases like UCS).
should support fast look-ups and inserts (and deletions and updates in the cases like UCS).
We can also change the point at which we apply the goal test. Here, we do it after choosing a frontier node for expansion. That’s compatible with UCS. But, we can also test the nodes before adding them to the frontier. The latter approach wouldn’t work in UCS but will in DFS and BFS. Anyhow, the point at which we conduct the goal test doesn’t determine if an algorithm is of type GS or TLS. So, we can move the test to the inner for-loop of Algorithm 1 and still have the generic GS.
We introduced the GS and TLS strategies with the search trees they superimpose over the state graphs. However, there’s no reference to the tree in the generic form of GS. Why?
That’s because the search tree is implicit. We implicitly grow the tree each time we expand a node as we consider it has thus become the tree’s new leaf. So, the search tree in GS is made of the nodes that are present in but not in .
We get the generic pseudocode of TLS by removing all the references to from the generic GS algorithm:
algorithm GenericTreeLikeSearch():
// INPUT
// The same as in the generic Graph Search
// OUTPUT
// Returns a path to a goal state, if one is reachable from the start state.
// Otherwise, returns failure.
frontier <- initialize the frontier
while frontier is not empty:
// choose and remove a node from frontier
u <- choose-one(frontier)
if u passes goal_test:
return u
for v in expand(u):
if phi(v):
add v to frontier
return failureAll our remarks regarding the function and the implementation details of for GS also hold for TLS. The same goes for the implicitness of the search tree.
Because TLS doesn’t check for repeated states, it may expand the same state multiple times. That can increase the running time and even lead to infinite loops if the state graph contains cycles.
In this section, we’ll show how to implement the GS and TLS versions of DFS. We’ll also show those two versions of the same algorithm behave differently in practice. As the example, we’ll use the following graph:
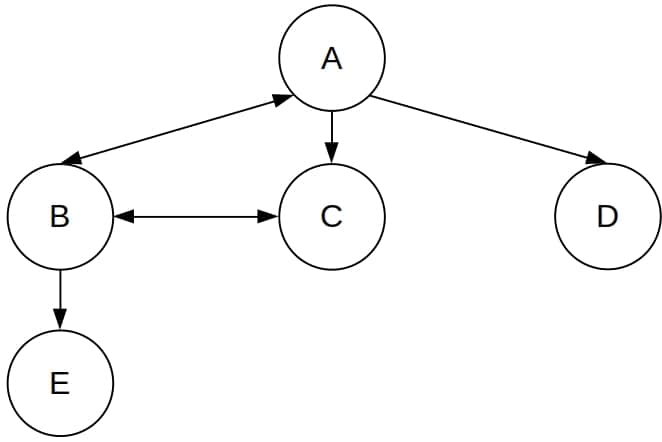
In it,  is the start state, but no state is a goal.
is the start state, but no state is a goal.
The idea behind Depth-First Search is to expand the node whose state we’ve reached the most recently. So, we use a LIFO queue as the frontier. We increase the depth of the search tree as much as we can until there are no more nodes to add or we reach a goal state.
In DFS, we usually run the goal test after reaching a state and not after choosing a node from the frontier. That way, we make the algorithm more efficient, but it isn’t incorrect to test the nodes after selecting them for expansion.
Here’s the pseudocode of TLS DFS:
algorithm TLSDFS(start, goalTest, state_graph):
// INPUT
// start = the start state
// goal_test = the function to test if the current state is the goal
// state_graph = the state graph representing all possible states and transitions
// OUTPUT
// Returns a path to a goal state if one is reachable from the start state.
// Otherwise, returns failure.
s <- make the start node that contains the start state
if goal_test(s):
return s
frontier <- initialize a LIFO queue containing only s
while frontier is not empty:
u <- pop the node most recently added to frontier
for v in expand(u):
if goalTest(v):
return v
Add v to frontier
return failureLet’s suppose that  returns the nodes in alphabetical order. This is how TLS DFS would handle our example:
returns the nodes in alphabetical order. This is how TLS DFS would handle our example:
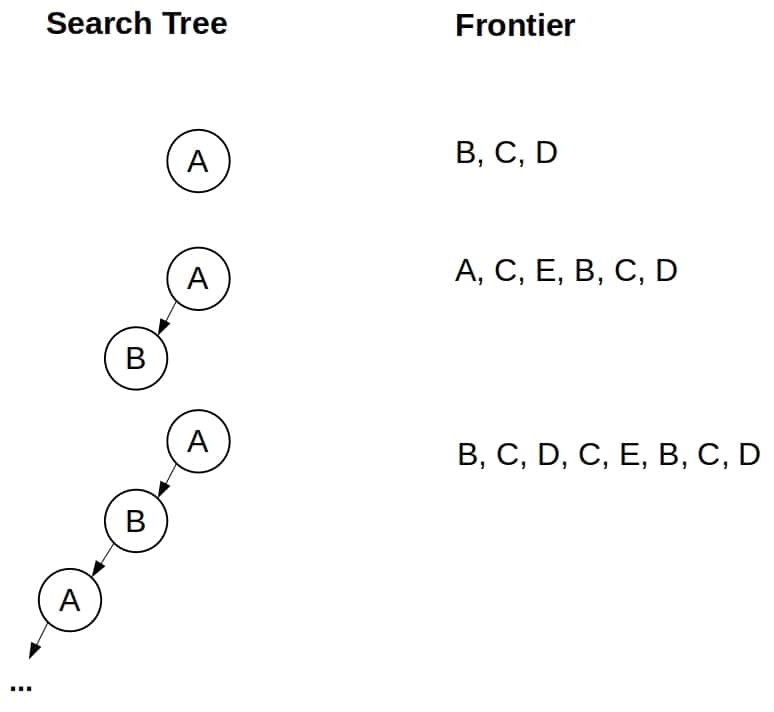
As we see, TLS DFS gets stuck in a loop and runs indefinitely even though the state graph is finite and small.
We can get a GS DFS if we memorize all the states we’ve reached and test for repetitions:
algorithm GSDFS(start_state, goal_test, state_graph):
// INPUT
// start_state = the initial state
// goal_test = the function that checks if a state is a goal
// state_graph = the graph representation of the state space
// OUTPUT
// Returns a path to a goal state, if one is reachable from the start state
// Otherwise, reurns failure.
s <- make the start node that contains the start state
if goal_test(s):
return s
frontier <- initialize a LIFO queue containing only s.state
reached <- make a set {s}
while frontier is not empty:
u <- pop the node most recently added to frontier
for v in expand(u):
if goal_test(v):
return v
if v.state not in reached:
add v to frontier
return failureAs we see, GS DFS avoids getting stuck in the loop:
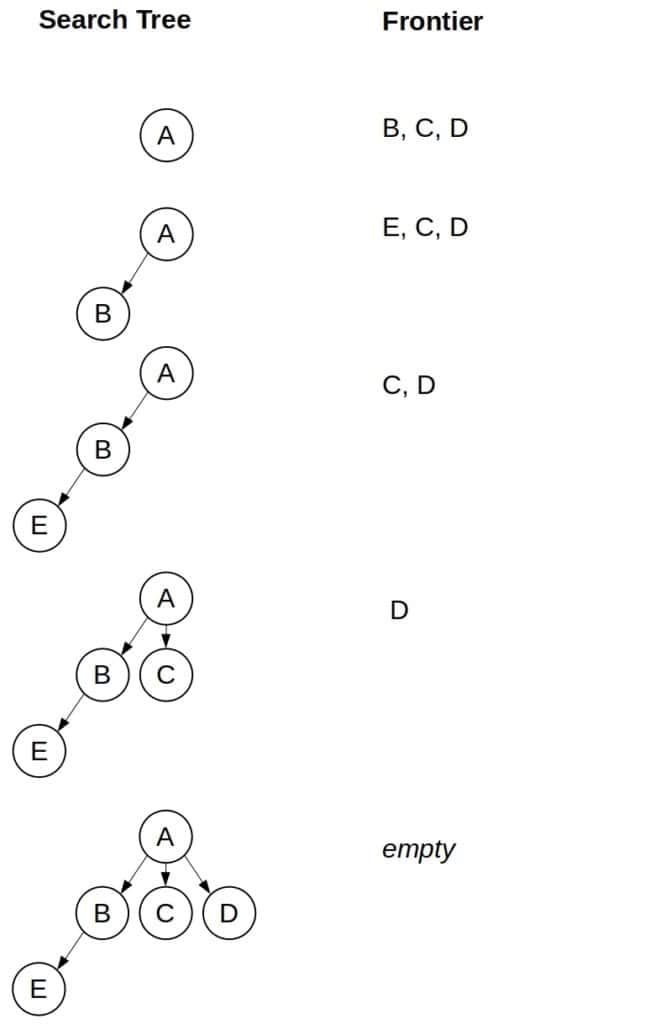
Which strategy is better? It may seem that GS is always superior to TLS because it can’t get stuck in the loop as TLS can. However, the answer isn’t as straightforward as it may seem. GS can have large memory requirements since it has to memorize every single state it reaches.
Further, if the state graph is indeed a tree, so it doesn’t contain cycles, we should go with a TLS algorithm instead of GS. The latter would take unnecessary memory. Since can only grow, it may even become too big for RAM, taking a toll on the execution time due to trashing.
However, we can find a compromise between GS and TLS. In general, a loop is a special case of a redundant path. If the path represented by the node  is longer or more costly than the one represented by node
is longer or more costly than the one represented by node  , we call the former path redundant. Provided that all actions have a non-negative cost, all the loops are redundant.
, we call the former path redundant. Provided that all actions have a non-negative cost, all the loops are redundant.
The compromise would consist in checking only for loops and not for other types of redundant paths. The only thing we need to add to TLS to get a loop-resistant algorithm is a check if  is somewhere on the path represented by in the inner for-loop.
is somewhere on the path represented by in the inner for-loop.
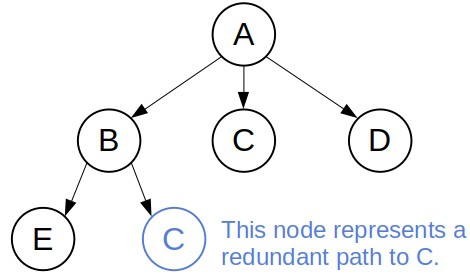
For example, the loop-resistant DFS would avoid the cycle that TLS DFS gets stuck in but would still expand  two times:
two times:
In this article, we presented the Graph-Search and Tree-Like Search strategies. Even though the former avoids the loops, it is more memory-demanding than the latter. Which approach is appropriate depends on the search problem at hand.