

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
1. Introduction
In this tutorial, we’ll explore concurrency in reactive programs written with Spring WebFlux.
We’ll begin by discussing concurrency in relation to reactive programming. Then we’ll learn how Spring WebFlux offers concurrency abstractions over different reactive server libraries.
2. The Motivation for Reactive Programming
A typical web application comprises several complex, interacting parts. Many of these interactions are blocking in nature, such as those involving a database call to fetch or update data. Several others, however, are independent and can be performed concurrently, possibly in parallel.
For instance, two user requests to a web server can be handled by different threads. On a multi-core platform, this has an obvious benefit in terms of the overall response time. Hence, this model of concurrency is known as the thread-per-request model:
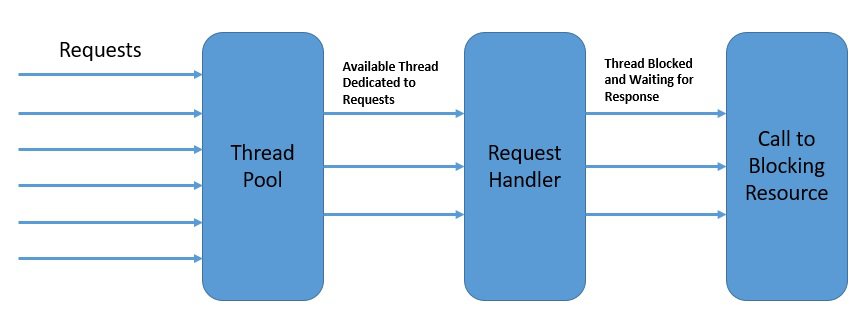
In the diagram above, each thread handles a single request at a time.
While thread-based concurrency solves a part of the problem for us, it does nothing to address the fact that most of our interactions within a single thread are still blocking. Moreover, the native threads we use to achieve concurrency in Java come at a significant cost in terms of context switches.
Meanwhile, as web applications face more and more requests, the thread-per-request model starts to fall short of expectations.
Consequently, we need a concurrency model that can help us handle increasingly more requests with a relatively fewer number of threads. This is one of the primary motivations for adopting reactive programing.
3. Concurrency in Reactive Programming
Reactive programming helps us structure the program in terms of data flows and the propagation of change through them. In a completely non-blocking environment, this can enable us to achieve higher concurrency with better resource utilization.
However, is reactive programming a complete departure from thread-based concurrency? While this is a strong statement to make, reactive programming certainly has a very different approach to the usage of threads to achieve concurrency. So the fundamental difference that reactive programming brings on is asynchronicity.
In other words, the program flow transforms from a sequence of synchronous operations, into an asynchronous stream of events.
For instance, under the reactive model, a read call to the database doesn’t block the calling thread while data is fetched. The call immediately returns a publisher that others can subscribe to. The subscriber can process the event after it occurs and may even further generate events itself:
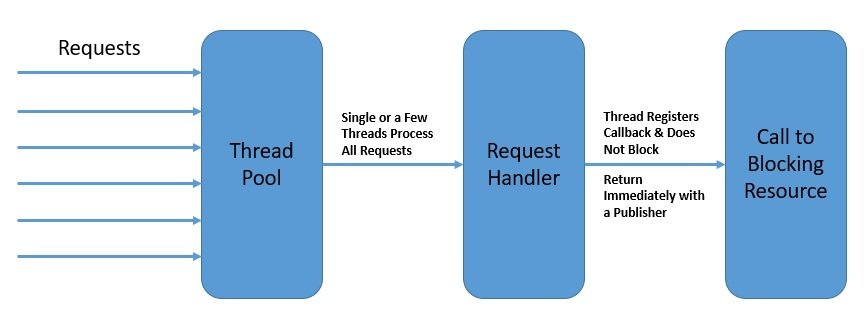
Above all, reactive programming doesn’t emphasize which thread events should be generated and consumed. Rather, the emphasis is on structuring the program as an asynchronous event stream.
The publisher and subscriber here don’t need to be part of the same thread. This helps us to achieve better utilization of the available threads, and therefore, higher overall concurrency.
4. Event Loop
There are several programming models that describe a reactive approach to concurrency.
In this section, we’ll examine a few of them to understand how reactive programming achieves higher concurrency with fewer threads.
One such reactive asynchronous programming model for servers is the event loop model:
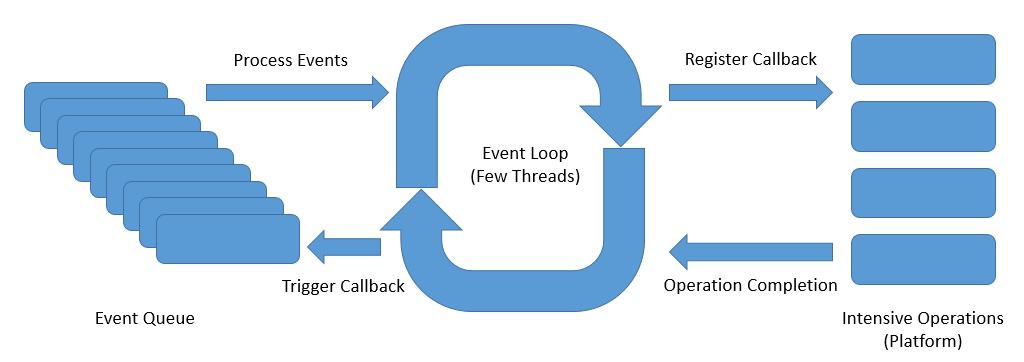
Above is an abstract design of an event loop that presents the ideas of reactive asynchronous programming:
- The event loop runs continuously in a single thread, although we can have as many event loops as the number of available cores.
- The event loop processes the events from an event queue sequentially and returns immediately after registering the callback with the platform.
- The platform can trigger the completion of an operation, like a database call or an external service invocation.
- The event loop can trigger the callback on the operation completion notification and send back the result to the original caller.
The event loop model is implemented in a number of platforms, including Node.js, Netty, and Ngnix. They offer much better scalability than traditional platforms, like Apache HTTP Server, Tomcat, or JBoss.
5. Reactive Programming With Spring WebFlux
Now we have enough insight into reactive programming and its concurrency model to explore the subject in Spring WebFlux.
WebFlux is Spring‘s reactive-stack web framework, which was added in version 5.0.
Let’s explore the server-side stack of Spring WebFlux to understand how it complements the traditional web stack in Spring:
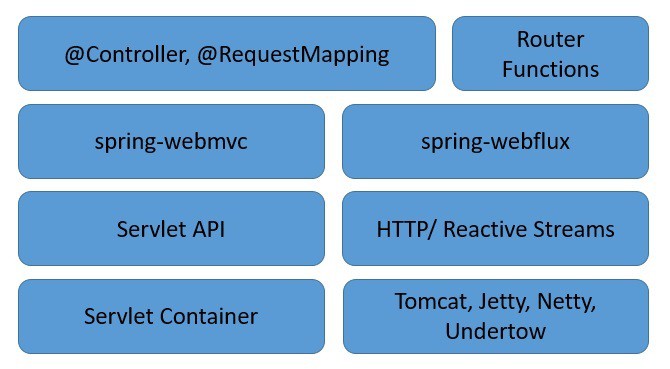
As we can see, Spring WebFlux sits parallel to the traditional web framework in Spring, and doesn’t necessarily replace it.
There are a few important points to note here:
- Spring WebFlux extends the traditional annotation-based programming model with functional routing.
- Moreover, it adapts the underlying HTTP runtimes to the Reactive Streams API, making the runtimes interoperable.
- It’s able to support a wide variety of reactive runtimes, including Servlet 3.1+ containers like Tomcat, Reactor, Netty, or Undertow.
- Lastly, it includes WebClient, a reactive and non-blocking client for HTTP requests offering functional and fluent APIs.
6. Threading Model in Supported Runtimes
As we discussed earlier, reactive programs tend to work with just a few threads and make the most of them. However, the number and nature of threads depends upon the actual Reactive Stream API runtime that we choose.
To clarify, Spring WebFlux can adapt to different runtimes through a common API provided by HttpHandler. This API is a simple contract with just one method that provides an abstraction over different server APIs, like Reactor Netty, Servlet 3.1 API, or Undertow APIs.
Let’s examine the threading model implemented in a few of them.
While Netty is the default server in a WebFlux application, it’s just a matter of declaring the right dependency to switch to any other supported server:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-reactor-netty</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</dependency>While it’s possible to observe the threads created in a Java Virtual Machine in a number of ways, it’s quite easy to just pull them from the Thread class itself:
Thread.getAllStackTraces()
.keySet()
.stream()
.collect(Collectors.toList());6.1. Reactor Netty
As we said, Reactor Netty is the default embedded server in the Spring Boot WebFlux starter. Let’s see the threads that Netty creates by default. To begin, we won’t add any other dependencies or use WebClient. So if we start a Spring WebFlux application created using its SpringBoot starter, we can expect to see some default threads it creates:
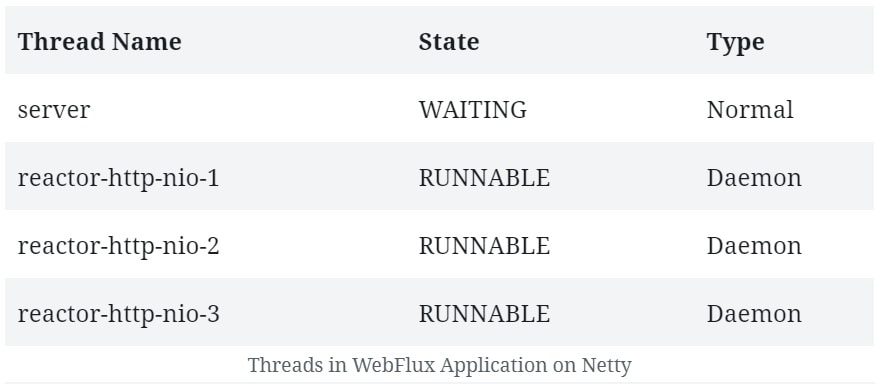
Note that, apart from a normal thread for the server, Netty spawns a bunch of worker threads for request processing. These are typically available CPU cores. This is the output on a quad-core machine. We’d also see a bunch of housekeeping threads typical to a JVM environment, but they aren’t important here.
Netty uses the event loop model to provide highly scalable concurrency in a reactive asynchronous manner. Let’s see how Netty implements an event loop levering Java NIO to provide this scalability:
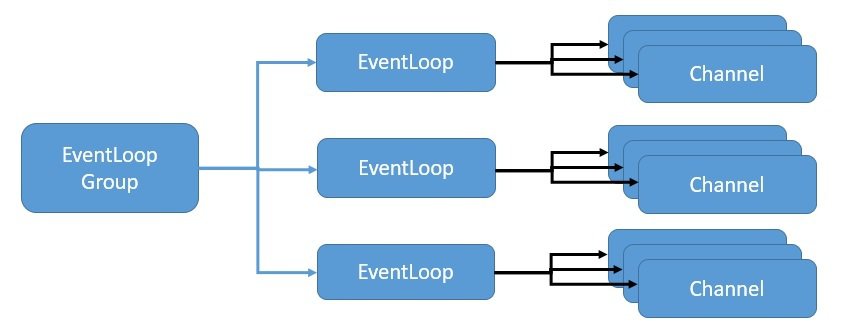
Here, EventLoopGroup manages one or more EventLoop, which must be continuously running. Therefore, it isn’t recommended to create more EventLoops than the number of available cores.
The EventLoopGroup further assigns an EventLoop to each newly created Channel. Thus, for the lifetime of a Channel, all operations are executed by the same thread.
6.2. Apache Tomcat
Spring WebFlux is also supported on a traditional Servlet Container, like Apache Tomcat.
WebFlux relies on the Servlet 3.1 API with non-blocking I/O. While it uses Servlet API behind a low-level adapter, Servlet API isn’t available for direct usage.
Let’s see what kind of threads we expect in a WebFlux application running on Tomcat:
The number and type of threads which we can see here are quite different from what we observed earlier.
To begin with, Tomcat starts with more worker threads, which defaults to ten. Of course, we’ll also see some housekeeping threads typical to the JVM, and the Catalina container, which we can ignore for this discussion.
We need to understand the architecture of Tomcat with Java NIO to correlate it with the threads we see above.
Tomcat 5 and onward supports NIO in its Connector component, which is primarily responsible for receiving the requests.
The other Tomcat component is the Container component, which is responsible for the container management functions.
The point of interest for us here is the threading model that the Connector component implements to support NIO. It’s comprised of Acceptor, Poller, and Worker as part of the NioEndpoint module:
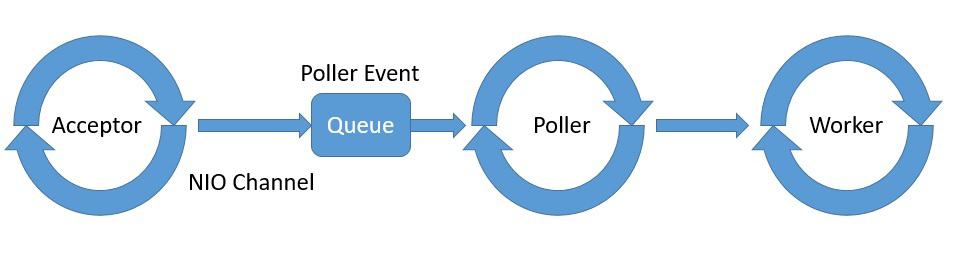
Tomcat spawns one or more threads for Acceptor, Poller, and Worker, typically with a thread pool dedicated to Worker.
While a detailed discussion on Tomcat architecture is beyond the scope of this article, we should now have enough insight to understand the threads we saw earlier.
7. Threading Model in WebClient
WebClient is the reactive HTTP client that’s part of Spring WebFlux. We can use it anytime we require REST-based communication, which enables us to create applications that are end-to-end reactive.
As we’ve seen before, reactive applications work with just a few threads, so there’s no margin for any part of the application to block a thread. Therefore, WebClient plays a vital role in helping us realize the potential of WebFlux.
7.1. Using WebClient
Using WebClient is quite simple as well. We don’t need to include any specific dependencies, as it’s part of Spring WebFlux.
Let’s create a simple REST endpoint that returns a Mono:
@GetMapping("/index")
public Mono<String> getIndex() {
return Mono.just("Hello World!");
}Then we’ll use WebClient to call this REST endpoint and consume the data reactively:
WebClient.create("http://localhost:8080/index").get()
.retrieve()
.bodyToMono(String.class)
.doOnNext(s -> printThreads());Here we’re also printing the threads that are created using the method we discussed earlier.
7.2. Understanding the Threading Model
So, how does the threading model work in the case of WebClient?
Well, not surprisingly, WebClient also implements concurrency using the event loop model. Of course, it relies on the underlying runtime to provide the necessary infrastructure.
If we’re running WebClient on the Reactor Netty, it shares the event loop that Netty uses for the server. Therefore, in this case, we may not notice much difference in the threads that are created.
However, WebClient is also supported on a Servlet 3.1+ container, like Jetty, but the way it works there is different.
If we compare the threads that are created on a WebFlux application running Jetty with and without WebClient, we’ll notice a few additional threads.
Here, WebClient has to create its event loop. So we can see the fixed number of processing threads that this event loop creates:
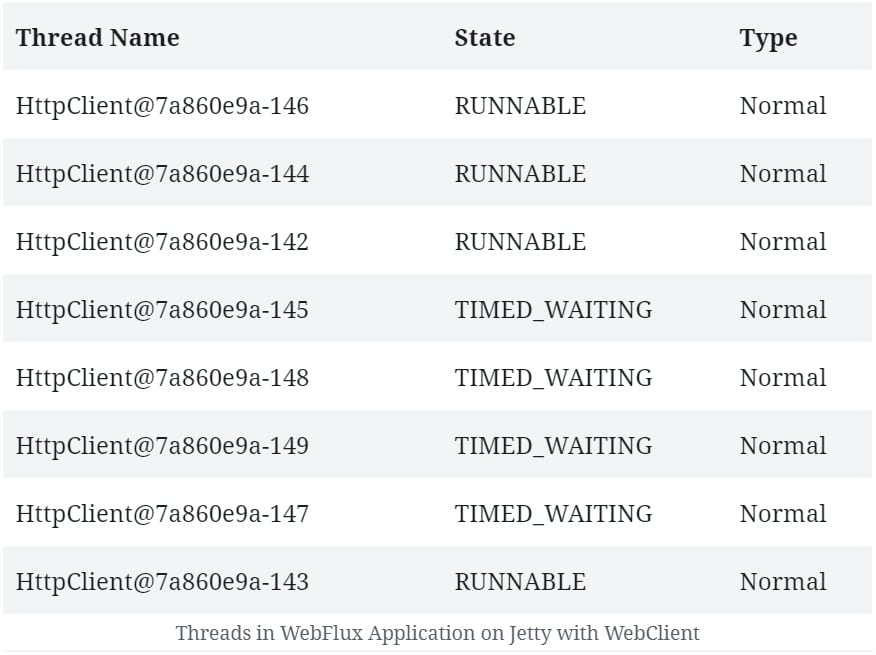
In some cases, having a separate thread pool for client and server can provide better performance. While it’s not the default behavior with Netty, it’s always possible to declare a dedicated thread pool for WebClient if needed.
We’ll see how this is possible in a later section.
8. Threading Model in Data Access Libraries
As we saw earlier, even a simple application usually consists of several parts that need to be connected.
Typical examples of these parts include databases and message brokers. The existing libraries to connect with many of them are still blocking, but that’s quickly changing.
There are several databases now that offer reactive libraries for connectivity. Many of these libraries are available within Spring Data, while we can use others directly as well.
The threading model these libraries use is of particular interest to us.
8.1. Spring Data MongoDB
Spring Data MongoDB provides reactive repository support for MongoDB built on top of the MongoDB Reactive Streams driver. Most notably, this driver fully implements the Reactive Streams API to provide asynchronous stream processing with non-blocking back-pressure.
Setting up support for the reactive repository for MongoDB in a Spring Boot application is as simple as adding a dependency:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb-reactive</artifactId>
</dependency>This will allow us to create a repository, and use it to perform some basic operations on MongoDB in a non-blocking manner:
public interface PersonRepository extends ReactiveMongoRepository<Person, ObjectId> {
}
.....
personRepository.findAll().doOnComplete(this::printThreads);So what kind of threads can we expect to see when we run this application on the Netty server?
Well, not surprisingly, we won’t see much difference, as a Spring Data reactive repository makes use of the same event loop that’s available for the server.
8.2. Reactor Kafka
Spring is still in the process of building full-fledged support for reactive Kafka. However, we do have options available outside Spring.
Reactor Kafka is a reactive API for Kafka based on Reactor. Reactor Kafka enables messages to be published and consumed using functional APIs, also with non-blocking back-pressure.
First, we need to add the required dependency in our application to start using Reactor Kafka:
<dependency>
<groupId>io.projectreactor.kafka</groupId>
<artifactId>reactor-kafka</artifactId>
<version>1.3.10</version>
</dependency>This should enable us to produce messages to Kafka in a non-blocking manner:
// producerProps: Map of Standard Kafka Producer Configurations
SenderOptions<Integer, String> senderOptions = SenderOptions.create(producerProps);
KafkaSender<Integer, String> sender = KafkaSender.create(senderOptions);
Flux<SenderRecord<Integer, String, Integer>> outboundFlux = Flux
.range(1, 10)
.map(i -> SenderRecord.create(new ProducerRecord<>("reactive-test", i, "Message_" + i), i));
sender.send(outboundFlux).subscribe();Similarly, we should be able to consume messages from Kafka, also in a non-blocking manner:
// consumerProps: Map of Standard Kafka Consumer Configurations
ReceiverOptions<Integer, String> receiverOptions = ReceiverOptions.create(consumerProps);
receiverOptions.subscription(Collections.singleton("reactive-test"));
KafkaReceiver<Integer, String> receiver = KafkaReceiver.create(receiverOptions);
Flux<ReceiverRecord<Integer, String>> inboundFlux = receiver.receive();
inboundFlux.doOnComplete(this::printThreads)This is pretty simple and self-explanatory.
We’re subscribing to a topic reactive-test in Kafka, and getting a Flux of messages.
The interesting thing for us is the threads that get created:
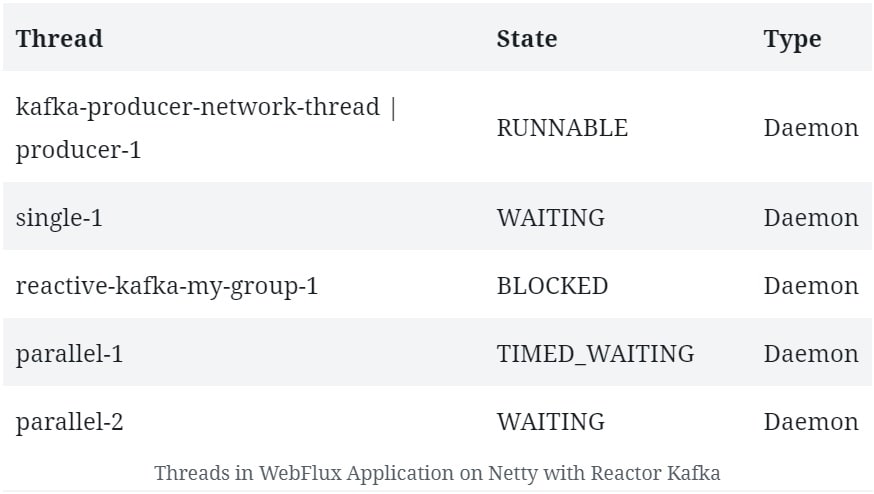
We can see a few threads that aren’t typical to the Netty server.
This indicates that Reactor Kafka manages its own thread pool, with a few worker threads that participate in Kafka message processing exclusively. Of course, we’ll see a bunch of other threads related to Netty and the JVM that we can ignore.
Kafka producers use a separate network thread for sending requests to the broker. Furthermore, they deliver responses to the application on a single-threaded pooled scheduler.
Kafka consumer, on the other hand, has one thread per consumer group that blocks to listen for incoming messages. The incoming messages are then scheduled for processing on a different thread pool.
9. Scheduling Options in WebFlux
So far, we’ve seen that reactive programming really shines in a completely non-blocking environment with just a few threads. But this also means that, if there is indeed a part that is blocking, it will result in far worse performance. This is because a blocking operation can freeze the event loop entirely.
So, how do we handle long-running processes or blocking operations in reactive programming?
Honestly, the best option would be to just avoid them. However, this may not always be possible, and we may need a dedicated scheduling strategy for those parts of our application.
Spring WebFlux offers a mechanism to switch processing to a different thread pool in between a data flow chain. This can provide us with precise control over the scheduling strategy that we want for certain tasks. Of course, WebFlux is able to offer this based on the thread pool abstractions, known as schedulers, available in the underlying reactive libraries.
9.1. Reactor
In Reactor, the Scheduler class defines the execution model, as well as where the execution takes place.
The Schedulers class provides a number of execution contexts, like immediate, single, elastic, and parallel. These provide different types of thread pools, which can be useful for different jobs. Moreover, we can always create our own Scheduler with a preexisting ExecutorService.
While Schedulers give us several execution contexts, Reactor also provides us with different ways to switch the execution context. These are the methods publishOn and subscribeOn.
We can use publishOn with a Scheduler anywhere in the chain, with that Scheduler affecting all the subsequent operators.
While we can also use subscribeOn with a Scheduler anywhere in the chain, it will only affect the context of the source of emission.
If we recall, WebClient on Netty shares the same event loop created for the server as a default behavior. However, we may have valid reasons to create a dedicated thread pool for WebClient.
Let’s see how we can achieve this in Reactor, which is the default reactive library in WebFlux:
Scheduler scheduler = Schedulers.newBoundedElastic(5, 10, "MyThreadGroup");
WebClient.create("http://localhost:8080/index").get()
.retrieve()
.bodyToMono(String.class)
.publishOn(scheduler)
.doOnNext(s -> printThreads());Earlier, we didn’t observe any difference in the threads created on Netty with or without WebClient. However, if we now run the code above, we’ll observe a few new threads being created:
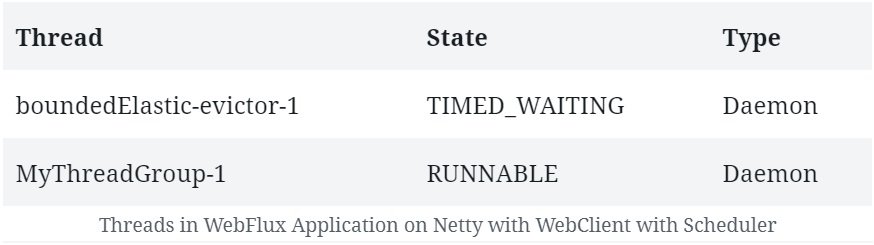
Here we can see the threads created as part of our bounded elastic thread pool. This is where responses from the WebClient are published once subscribed.
This leaves the main thread pool for handling the server requests.
9.2. RxJava
The default behavior in RxJava isn’t very different than that of the Reactor.
The Observable, and the chain of operators we apply on it, do their work and notify the observers on the same thread where the subscription was invoked. Also, RxJava, like Reactor, offers ways to introduce prefixed or custom scheduling strategies into the chain.
RxJava also features a class Schedulers, which offers a number of execution models for the Observable chain. These include new thread, immediate, trampoline, io, computation, and test. Of course, it also allows us to define a Scheduler from a Java Executor.
Moreover, RxJava also offers two extension methods to achieve this, subscribeOn and observeOn.
The subscribeOn method changes the default behavior by specifying a different Scheduler on which Observable should operate. The observeOn method, on the other hand, specifies a different Scheduler that the Observable can use to send notifications to the observers.
As we discussed before, Spring WebFlux uses Reactor as its reactive library by default. But since it’s fully compatible with Reactive Streams API, it’s possible to switch to another Reactive Streams implementation, like RxJava (for RxJava 1.x with its Reactive Streams adapter).
We need to explicitly add the dependency:
<dependency>
<groupId>io.reactivex.rxjava2</groupId>
<artifactId>rxjava</artifactId>
<version>2.2.21</version>
</dependency>Then we can start to use RxJava types, like Observable, in our application, along with RxJava specific Schedulers:
io.reactivex.Observable
.fromIterable(Arrays.asList("Tom", "Sawyer"))
.map(s -> s.toUpperCase())
.observeOn(io.reactivex.schedulers.Schedulers.trampoline())
.doOnComplete(this::printThreads);As a result, if we run this application, apart from the regular Netty and JVM related threads, we should see a few threads related to our RxJava Scheduler:
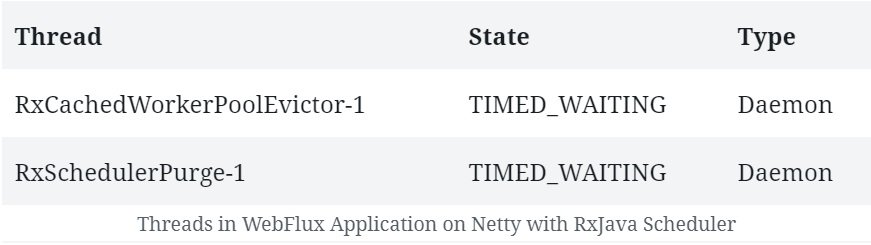
10. Conclusion
In this article, we explored the premise of reactive programming from the context of concurrency. We observed the difference in the concurrency model in traditional and reactive programming. This allowed us to examine the concurrency model in Spring WebFlux, and its take on the threading model to achieve it.
Then we explored the threading model in WebFlux in combination with different HTTP runtime and reactive libraries. We also learned how the threading model differs when we use WebClient versus a data access library.
Finally, we touched upon the options for controlling the scheduling strategy in our reactive program within WebFlux.


















