

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
1. Introduction
In this tutorial, we’ll learn the basics of creating reactive systems in Java using Spring, as well as other tools and frameworks.
In the process, we’ll discuss how reactive programming is just a driver towards creating a reactive system. This will help us understand the rationale for creating reactive systems and the different specifications, libraries, and standards it has inspired along the way.
2. What Are Reactive Systems?
Over the last few decades, the technology landscape has seen several disruptions that have led to a complete transformation in the way we see value in technology. The computing world before the Internet could never have imagined the ways and means it would change things.
With the reach of the Internet to the masses, and the ever-evolving experience it promises, application architects need to be on their toes to meet the demands.
Fundamentally, this means that we can never again design an application the way we used to. A highly responsive application is no longer a luxury, but a necessity.
That, too, is in the face of random failures and unpredictable load. The need of the hour isn’t just to get the correct result, but to get it fast! It’s quite important to drive the amazing user experiences we promise to deliver.
This is what creates the need for an architectural style that can give us Reactive Systems.
2.1. Reactive Manifesto
Back in the year 2013, a team of developers, lead by Jonas Boner, came together to define a set of core principles in a document known as the Reactive Manifesto. This is what laid the foundation for an architecture style to create Reactive Systems. Since then, this manifesto has gathered a lot of interest from the developer community.
Basically, this document prescribes the recipe for a reactive system to be flexible, loosely-coupled, and scalable. This makes such systems easy to develop, tolerant of failures, and most importantly, highly responsive, the underpinning elements for incredible user experiences.
So what is this secret recipe? Well, it’s hardly any secret. The manifesto defines the fundamental characteristics or principles of a reactive system:
- Responsive: A reactive system should provide a rapid and consistent response time, and thus a consistent quality of service.
- Resilient: A reactive system should remain responsive in case of random failures through replication and isolation.
- Elastic: Such a system should remain responsive under unpredictable workloads through cost-effective scalability.
- Message-Driven: It should rely on asynchronous message passing between system components.
These principles sound simple and sensible, but aren’t always easier to implement in complex enterprise architecture. In this article, we’ll develop a sample system in Java with these principles in mind.
3. What Is Reactive Programming?
Before we proceed, it’s important to understand the difference between reactive programming and reactive systems. We use both of these terms quite often, and easily misunderstand one for the other. As we’ve seen earlier, reactive systems are a result of a specific architectural style.
In contrast, reactive programming is a programming paradigm where the focus is on developing asynchronous and non-blocking components. The core of reactive programming is a data stream that we can observe and react to, and even apply back pressure to as well. This leads to non-blocking execution, and better scalability with fewer threads of execution.
Now, this doesn’t mean that reactive systems and reactive programming are mutually exclusive. In fact, reactive programming is an important step towards realizing a reactive system, but it’s not everything.
3.1. Reactive Streams
Reactive Streams is a community initiative that started back in 2013 to provide a standard for asynchronous stream processing with non-blocking backpressure. The objective was to define a set of interfaces, methods, and protocols that can describe the necessary operations and entities.
Since then, several implementations in multiple programming languages have emerged that conform to the reactive streams specification. These include Akka Streams, Ratpack, and Vert.x to name a few.
3.2. Reactive Libraries for Java
One of the initial objectives behind reactive streams was to eventually be included as an official Java standard library. As a result, the reactive streams specification is semantically equivalent to the Java Flow library introduced in Java 9.
Apart from that, there are a few popular choices to implement reactive programming in Java:
- Reactive Extensions: Popularly known as ReactiveX, they provide API for asynchronous programming with observable streams. These are available for multiple programming languages and platforms, including Java, where it’s known as RxJava.
- Project Reactor: This is another reactive library, ground-up based on the reactive streams specification, targeted towards building non-applications on the JVM. It also happens to be the foundation of the reactive stack in the Spring ecosystem.
4. A Simple Application
For the purpose of this tutorial, we’ll develop a simple application based on microservices architecture with a minimal frontend. The application architecture should have enough elements to create a reactive system.
For our application, we’ll adopt end-to-end reactive programming, as well as other patterns and tools to accomplish the fundamental characteristics of a reactive system.
4.1. Architecture
We’ll begin by defining a simple application architecture that doesn’t necessarily exhibit the characteristics of reactive systems. From there, we’ll make the necessary changes to achieve these characteristics one by one.
So first, let’s begin by defining a simple architecture:
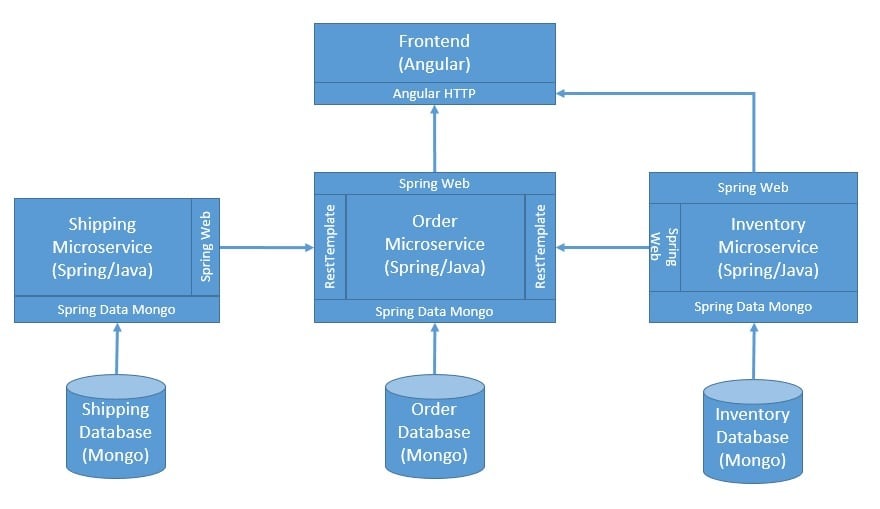
This is quite a simple architecture that has a bunch of microservices to facilitate a commerce use-case where we can place an order. It also has a front-end for user experience, and all communication happens as REST over HTTP. Moreover, every microservice manages their data in individual databases, a practice known as database-per-service.
We’ll go ahead and create this simple application in the following sub-sections. This will be our base to understand the fallacies of this architecture, as well as the ways and means to adopt principles and practices so that we can transform this into a reactive system.
4.2. Inventory Microservice
Inventory microservice will be responsible for managing a list of products and their current stock. It will also allow altering the stock as orders are processed. We’ll use Spring Boot with MongoDB to develop this service.
We’ll begin by defining a controller to expose some endpoints:
@GetMapping
public List<Product> getAllProducts() {
return productService.getProducts();
}
@PostMapping
public Order processOrder(@RequestBody Order order) {
return productService.handleOrder(order);
}
@DeleteMapping
public Order revertOrder(@RequestBody Order order) {
return productService.revertOrder(order);
}We’ll also define a service to encapsulate our business logic:
@Transactional
public Order handleOrder(Order order) {
order.getLineItems()
.forEach(l -> {
Product> p = productRepository.findById(l.getProductId())
.orElseThrow(() -> new RuntimeException("Could not find the product: " + l.getProductId()));
if (p.getStock() >= l.getQuantity()) {
p.setStock(p.getStock() - l.getQuantity());
productRepository.save(p);
} else {
throw new RuntimeException("Product is out of stock: " + l.getProductId());
}
});
return order.setOrderStatus(OrderStatus.SUCCESS);
}
@Transactional
public Order revertOrder(Order order) {
order.getLineItems()
.forEach(l -> {
Product p = productRepository.findById(l.getProductId())
.orElseThrow(() -> new RuntimeException("Could not find the product: " + l.getProductId()));
p.setStock(p.getStock() + l.getQuantity());
productRepository.save(p);
});
return order.setOrderStatus(OrderStatus.SUCCESS);
}Note that we’re persisting the entities within a transaction, which ensures that no inconsistent state results in case of exceptions.
Apart from these, we’ll also have to define the domain entities, the repository interface, and a bunch of configuration classes necessary for everything to work properly.
But since these are mostly boilerplate, we’ll avoid going through them, and they can be referred to in the GitHub repository provided in the last section of this article.
4.3. Shipping Microservice
The shipping microservice won’t be very different either. This will be responsible for checking if a shipment can be generated for the order, and then create one if possible.
As before, we’ll define a controller to expose just a single endpoint:
@PostMapping
public Order process(@RequestBody Order order) {
return shippingService.handleOrder(order);
}And again, we’ll define a service to encapsulate the business logic related to order shipment:
public Order handleOrder(Order order) {
LocalDate shippingDate = null;
if (LocalTime.now().isAfter(LocalTime.parse("10:00"))
&& LocalTime.now().isBefore(LocalTime.parse("18:00"))) {
shippingDate = LocalDate.now().plusDays(1);
} else {
throw new RuntimeException("The current time is off the limits to place order.");
}
shipmentRepository.save(new Shipment()
.setAddress(order.getShippingAddress())
.setShippingDate(shippingDate));
return order.setShippingDate(shippingDate)
.setOrderStatus(OrderStatus.SUCCESS);
}Our simple shipping service is just checking the valid time window to place orders. As before, we’ll avoid discussing the rest of the boilerplate code.
4.4. Order Microservice
Finally, we’ll define an order microservice which will be responsible for creating a new order apart from other things. Interestingly, it’ll also play as an orchestrator service where it will communicate with the inventory service and the shipping service for the order.
Let’s define our controller with the required endpoints:
@PostMapping
public Order create(@RequestBody Order order) {
Order processedOrder = orderService.createOrder(order);
if (OrderStatus.FAILURE.equals(processedOrder.getOrderStatus())) {
throw new RuntimeException("Order processing failed, please try again later.");
}
return processedOrder;
}
@GetMapping
public List<Order> getAll() {
return orderService.getOrders();
}And also a service to encapsulate the business logic related to orders:
public Order createOrder(Order order) {
boolean success = true;
Order savedOrder = orderRepository.save(order);
Order inventoryResponse = null;
try {
inventoryResponse = restTemplate.postForObject(
inventoryServiceUrl, order, Order.class);
} catch (Exception ex) {
success = false;
}
Order shippingResponse = null;
try {
shippingResponse = restTemplate.postForObject(
shippingServiceUrl, order, Order.class);
} catch (Exception ex) {
success = false;
HttpEntity<Order> deleteRequest = new HttpEntity<>(order);
ResponseEntity<Order> deleteResponse = restTemplate.exchange(
inventoryServiceUrl, HttpMethod.DELETE, deleteRequest, Order.class);
}
if (success) {
savedOrder.setOrderStatus(OrderStatus.SUCCESS);
savedOrder.setShippingDate(shippingResponse.getShippingDate());
} else {
savedOrder.setOrderStatus(OrderStatus.FAILURE);
}
return orderRepository.save(savedOrder);
}
public List<Order> getOrders() {
return orderRepository.findAll();
}The handling of orders where we’re orchestrating calls to inventory and shipping services is far from ideal. Distributed transactions with multiple microservices is a complex topic in itself, and beyond the scope of this article.
However, we’ll see later in this article how a reactive system can avoid the need for distributed transactions to a certain extent.
As before, we won’t go through the rest of the boilerplate code; however, this can be referenced in the GitHub repo.
4.5. Front-end
We’ll also add a user interface to make the discussion complete. The user interface will be based on Angular and will be a simple single-page application.
We’ll need to create a simple component in Angular to handle create and fetch orders. Of specific importance is the part where we call our API to create the order:
createOrder() {
let headers = new HttpHeaders({'Content-Type': 'application/json'});
let options = {headers: headers}
this.http.post('http://localhost:8080/api/orders', this.form.value, options)
.subscribe(
(response) => {
this.response = response
},
(error) => {
this.error = error
}
)
}The above code snippet expects order data to be captured in a form, and available within the scope of the component. Angular offers fantastic support for creating simple to complex forms using reactive and template-driven forms.
Also important is the part where we get previously created orders:
getOrders() {
this.previousOrders = this.http.get(''http://localhost:8080/api/orders'')
}Please note that the Angular HTTP module is asynchronous in nature, and thus returns RxJS Observables. We can handle the response in our view by passing them through an async pipe:
<div class="container" *ngIf="previousOrders !== null">
<h2>Your orders placed so far:</h2>
<ul>
<li *ngFor="let order of previousOrders | async">
<p>Order ID: {{ order.id }}, Order Status: {{order.orderStatus}}, Order Message: {{order.responseMessage}}</p>
</li>
</ul>
</div>Of course, Angular will require templates, styles, and configurations to work, but these can be referred to in the GitHub repository. Please note that we have bundled everything in a single component here, which is ideally not something we should do.
But, for this article, those concerns aren’t in scope.
4.6. Deploying the Application
Now that we’ve created all the individual parts of the application, how should we go about deploying them? We can always do this manually, but we should be mindful that it can soon become tedious.
For this article, we’ll use Docker Compose to build and deploy our application on a Docker Machine. This will require us to add a standard Dockerfile in each service, and create a Docker Compose file for the entire application. Before you run docker-compose up, make sure all the modules are build. To build a module use this command: mvn clean package spring-boot:repackage. In the docker-compose we will have all the dependent services to run the entire project like kafka and mongodb.
Let’s see how this docker-compose.yml file looks:
version: '3'
services:
frontend:
build: ./frontend
ports:
- "80:80"
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- 22181:2181
kafka:
image: confluentinc/cp-kafka:latest
container_name: kafka-broker
depends_on:
- zookeeper
ports:
- 29092:29092
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
mongodb:
container_name: mongo-db
image: mongo:6.0
volumes:
- ~/mongo:/data/db
ports:
- "27017:27017"
healthcheck:
test: exit 0
order-service:
build: ./order-service
ports:
- "8080:8080"
depends_on:
mongodb:
condition: service_healthy
inventory-service:
build: ./inventory-service
ports:
- "8081:8081"
depends_on:
mongodb:
condition: service_healthy
shipping-service:
build: ./shipping-service
ports:
- "8082:8082"
depends_on:
mongodb:
condition: service_healthyThis is a fairly standard definition of services in Docker Compose, and doesn’t require any special attention.
4.7. Problems With This Architecture
Now that we have a simple application in place with multiple services interacting with each other, we can discuss the problems in this architecture. These are what we’ll try to address in the following sections, and eventually we’ll get to the state where we’ll have transformed our application into a reactive system.
While this application is far from a production-grade software, and there are several issues, we’ll focus on the issues that pertain to the motivations for reactive systems:
- Failure in either inventory service or shipping service can have a cascading effect.
- The calls to external systems and database are all blocking in nature.
- The deployment can’t handle failures and fluctuating loads automatically.
5. Reactive Programming
Blocking calls in any program often result in critical resources just waiting for things to happen. These include database calls, calls to web services, and file system calls. If we can free up threads of execution from this waiting, and provide a mechanism to circle back once results are available, it’ll yield much better resource utilization.
This is what adopting the reactive programming paradigm does for us. While it’s possible to switch over to a reactive library for many of these calls, it may not be possible for everything. For us, fortunately, Spring makes it much easier to use reactive programming with MongoDB and REST APIs:
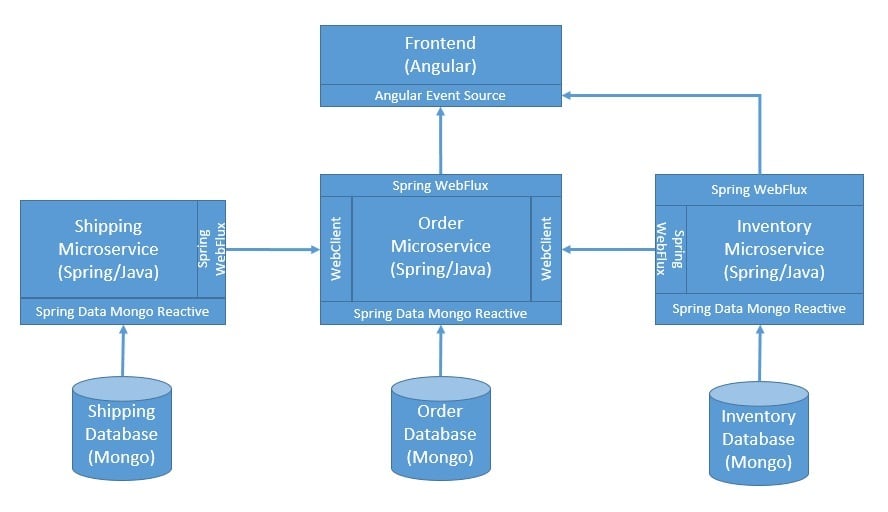
Spring Data Mongo has support for reactive access through the MongoDB Reactive Streams Java Driver. It provides ReactiveMongoTemplate and ReactiveMongoRepository, both of which have extensive mapping functionality.
Spring WebFlux provides the reactive-stack web framework for Spring, enabling non-blocking code and Reactive Streams backpressure. It leverages the Reactor as its reactive library. Further, it provides WebClient for performing HTTP requests with Reactive Streams backpressure. It uses Reactor Netty as the HTTP client library.
5.1. Inventory Service
We’ll begin by changing our endpoints to emit reactive publishers:
@GetMapping
public Flux<Product> getAllProducts() {
return productService.getProducts();
}@PostMapping
public Mono<Order> processOrder(@RequestBody Order order) {
return productService.handleOrder(order);
}
@DeleteMapping
public Mono<Order> revertOrder(@RequestBody Order order) {
return productService.revertOrder(order);
}Obviously, we’ll have to make necessary changes to the service as well:
@Transactional
public Mono<Order> handleOrder(Order order) {
return Flux.fromIterable(order.getLineItems())
.flatMap(l -> productRepository.findById(l.getProductId()))
.flatMap(p -> {
int q = order.getLineItems().stream()
.filter(l -> l.getProductId().equals(p.getId()))
.findAny().get()
.getQuantity();
if (p.getStock() >= q) {
p.setStock(p.getStock() - q);
return productRepository.save(p);
} else {
return Mono.error(new RuntimeException("Product is out of stock: " + p.getId()));
}
})
.then(Mono.just(order.setOrderStatus("SUCCESS")));
}
@Transactional
public Mono<Order> revertOrder(Order order) {
return Flux.fromIterable(order.getLineItems())
.flatMap(l -> productRepository.findById(l.getProductId()))
.flatMap(p -> {
int q = order.getLineItems().stream()
.filter(l -> l.getProductId().equals(p.getId()))
.findAny().get()
.getQuantity();
p.setStock(p.getStock() + q);
return productRepository.save(p);
})
.then(Mono.just(order.setOrderStatus("SUCCESS")));
}5.2. Shipping Service
Similarly, we’ll change the endpoint of our shipping service:
@PostMapping
public Mono<Order> process(@RequestBody Order order) {
return shippingService.handleOrder(order);
}And we’ll also make the corresponding changes in the service to leverage reactive programming:
public Mono<Order> handleOrder(Order order) {
return Mono.just(order)
.flatMap(o -> {
LocalDate shippingDate = null;
if (LocalTime.now().isAfter(LocalTime.parse("10:00"))
&& LocalTime.now().isBefore(LocalTime.parse("18:00"))) {
shippingDate = LocalDate.now().plusDays(1);
} else {
return Mono.error(new RuntimeException("The current time is off the limits to place order."));
}
return shipmentRepository.save(new Shipment()
.setAddress(order.getShippingAddress())
.setShippingDate(shippingDate));
})
.map(s -> order.setShippingDate(s.getShippingDate())
.setOrderStatus(OrderStatus.SUCCESS));
}5.3. Order Service
We’ll have to make similar changes in the endpoints of the order service:
@PostMapping
public Mono<Order> create(@RequestBody Order order) {
return orderService.createOrder(order)
.flatMap(o -> {
if (OrderStatus.FAILURE.equals(o.getOrderStatus())) {
return Mono.error(new RuntimeException("Order processing failed, please try again later. " + o.getResponseMessage()));
} else {
return Mono.just(o);
}
});
}
@GetMapping
public Flux<Order> getAll() {
return orderService.getOrders();
}The changes to service will be more involved, as we’ll have to make use of Spring WebClient to invoke the inventory and shipping reactive endpoints:
public Mono<Order> createOrder(Order order) {
return Mono.just(order)
.flatMap(orderRepository::save)
.flatMap(o -> {
return webClient.method(HttpMethod.POST)
.uri(inventoryServiceUrl)
.body(BodyInserters.fromValue(o))
.exchange();
})
.onErrorResume(err -> {
return Mono.just(order.setOrderStatus(OrderStatus.FAILURE)
.setResponseMessage(err.getMessage()));
})
.flatMap(o -> {
if (!OrderStatus.FAILURE.equals(o.getOrderStatus())) {
return webClient.method(HttpMethod.POST)
.uri(shippingServiceUrl)
.body(BodyInserters.fromValue(o))
.exchange();
} else {
return Mono.just(o);
}
})
.onErrorResume(err -> {
return webClient.method(HttpMethod.POST)
.uri(inventoryServiceUrl)
.body(BodyInserters.fromValue(order))
.retrieve()
.bodyToMono(Order.class)
.map(o -> o.setOrderStatus(OrderStatus.FAILURE)
.setResponseMessage(err.getMessage()));
})
.map(o -> {
if (!OrderStatus.FAILURE.equals(o.getOrderStatus())) {
return order.setShippingDate(o.getShippingDate())
.setOrderStatus(OrderStatus.SUCCESS);
} else {
return order.setOrderStatus(OrderStatus.FAILURE)
.setResponseMessage(o.getResponseMessage());
}
})
.flatMap(orderRepository::save);
}
public Flux<Order> getOrders() {
return orderRepository.findAll();
}This kind of orchestration with reactive APIs is no easy exercise, and often error-prone, as well as hard to debug. We’ll see how this can be simplified in the next section.
5.4. Front-end
Now that our APIs are capable of streaming events as they occur, it’s quite natural that we should be able to leverage that in our front-end as well. Fortunately, Angular supports EventSource, the interface for Server-Sent Events.
Let’s see how can we pull and process all our previous orders as a stream of events:
getOrderStream() {
return Observable.create((observer) => {
let eventSource = new EventSource('http://localhost:8080/api/orders')
eventSource.onmessage = (event) => {
let json = JSON.parse(event.data)
this.orders.push(json)
this._zone.run(() => {
observer.next(this.orders)
})
}
eventSource.onerror = (error) => {
if(eventSource.readyState === 0) {
eventSource.close()
this._zone.run(() => {
observer.complete()
})
} else {
this._zone.run(() => {
observer.error('EventSource error: ' + error)
})
}
}
})
}6. Message-Driven Architecture
The first problem we’re going to address is related to service-to-service communication. Right now, these communications are synchronous, which presents several problems. These include cascading failures, complex orchestration, and distributed transactions to name a few.
An obvious way to solve this problem is to make these communications asynchronous. A message broker for facilitating all service-to-service communication can do the trick for us. We’ll use Kafka as our message broker and Spring for Kafka to produce and consume messages:
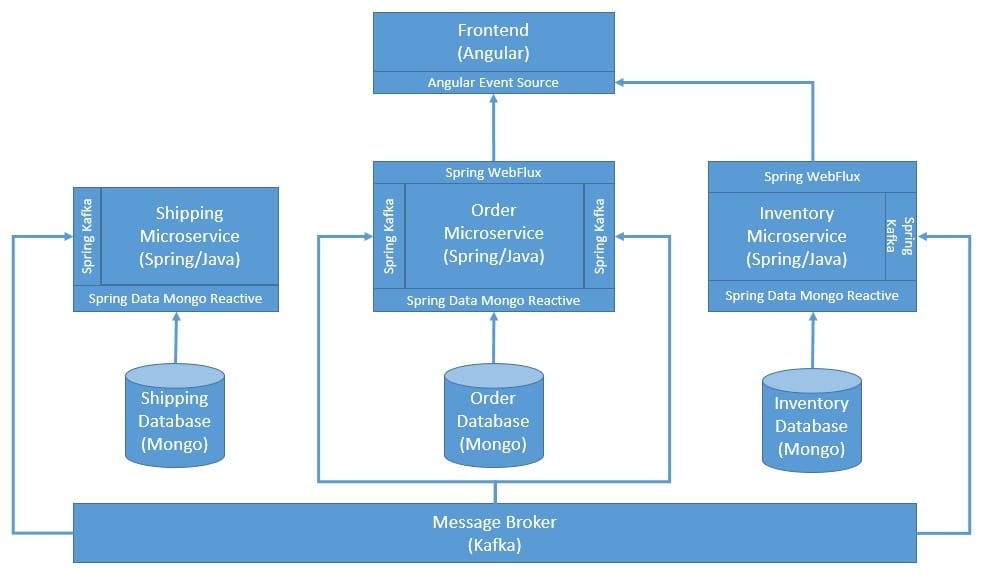
We’ll use a single topic to produce and consume order messages with different order statuses for services to react.
Let’s see how each service needs to change.
6.1. Inventory Service
Let’s begin by defining the message producer for our inventory service:
@Autowired
private KafkaTemplate<String, Order> kafkaTemplate;
public void sendMessage(Order order) {
this.kafkaTemplate.send("orders", order);
}Next, we’ll have to define a message consumer for inventory service to react to different messages on the topic:
@KafkaListener(topics = "orders", groupId = "inventory")
public void consume(Order order) throws IOException {
if (OrderStatus.RESERVE_INVENTORY.equals(order.getOrderStatus())) {
productService.handleOrder(order)
.doOnSuccess(o -> {
orderProducer.sendMessage(order.setOrderStatus(OrderStatus.INVENTORY_SUCCESS));
})
.doOnError(e -> {
orderProducer.sendMessage(order.setOrderStatus(OrderStatus.INVENTORY_FAILURE)
.setResponseMessage(e.getMessage()));
}).subscribe();
} else if (OrderStatus.REVERT_INVENTORY.equals(order.getOrderStatus())) {
productService.revertOrder(order)
.doOnSuccess(o -> {
orderProducer.sendMessage(order.setOrderStatus(OrderStatus.INVENTORY_REVERT_SUCCESS));
})
.doOnError(e -> {
orderProducer.sendMessage(order.setOrderStatus(OrderStatus.INVENTORY_REVERT_FAILURE)
.setResponseMessage(e.getMessage()));
}).subscribe();
}
}This also means that we can safely drop some of the redundant endpoints from our controller now. These changes are sufficient to achieve asynchronous communication in our application.
6.2. Shipping Service
The changes in shipping service are relatively similar to what we did earlier with the inventory service. The message producer is the same, and the message consumer is specific to shipping logic:
@KafkaListener(topics = "orders", groupId = "shipping")
public void consume(Order order) throws IOException {
if (OrderStatus.PREPARE_SHIPPING.equals(order.getOrderStatus())) {
shippingService.handleOrder(order)
.doOnSuccess(o -> {
orderProducer.sendMessage(order.setOrderStatus(OrderStatus.SHIPPING_SUCCESS)
.setShippingDate(o.getShippingDate()));
})
.doOnError(e -> {
orderProducer.sendMessage(order.setOrderStatus(OrderStatus.SHIPPING_FAILURE)
.setResponseMessage(e.getMessage()));
}).subscribe();
}
}We can safely drop all the endpoints in our controller now, as we no longer need them.
6.3. Order Service
The changes in order service will be a little more involved, as this is where we were doing all the orchestration earlier.
Nevertheless, the message producer remains unchanged, and message consumer takes on order service-specific logic:
@KafkaListener(topics = "orders", groupId = "orders")
public void consume(Order order) throws IOException {
if (OrderStatus.INITIATION_SUCCESS.equals(order.getOrderStatus())) {
orderRepository.findById(order.getId())
.map(o -> {
orderProducer.sendMessage(o.setOrderStatus(OrderStatus.RESERVE_INVENTORY));
return o.setOrderStatus(order.getOrderStatus())
.setResponseMessage(order.getResponseMessage());
})
.flatMap(orderRepository::save)
.subscribe();
} else if ("INVENTORY-SUCCESS".equals(order.getOrderStatus())) {
orderRepository.findById(order.getId())
.map(o -> {
orderProducer.sendMessage(o.setOrderStatus(OrderStatus.PREPARE_SHIPPING));
return o.setOrderStatus(order.getOrderStatus())
.setResponseMessage(order.getResponseMessage());
})
.flatMap(orderRepository::save)
.subscribe();
} else if ("SHIPPING-FAILURE".equals(order.getOrderStatus())) {
orderRepository.findById(order.getId())
.map(o -> {
orderProducer.sendMessage(o.setOrderStatus(OrderStatus.REVERT_INVENTORY));
return o.setOrderStatus(order.getOrderStatus())
.setResponseMessage(order.getResponseMessage());
})
.flatMap(orderRepository::save)
.subscribe();
} else {
orderRepository.findById(order.getId())
.map(o -> {
return o.setOrderStatus(order.getOrderStatus())
.setResponseMessage(order.getResponseMessage());
})
.flatMap(orderRepository::save)
.subscribe();
}
}The consumer here is merely reacting to order messages with different order statuses. This is what gives us the choreography between different services.
Finally, our order service will also have to change to support this choreography:
public Mono<Order> createOrder(Order order) {
return Mono.just(order)
.flatMap(orderRepository::save)
.map(o -> {
orderProducer.sendMessage(o.setOrderStatus(OrderStatus.INITIATION_SUCCESS));
return o;
})
.onErrorResume(err -> {
return Mono.just(order.setOrderStatus(OrderStatus.FAILURE)
.setResponseMessage(err.getMessage()));
})
.flatMap(orderRepository::save);
}Note that this is far simpler than the service we had to write with reactive endpoints in the last section. Asynchronous choreography often results in far simpler code, although it does come at the cost of eventual consistency and complex debugging and monitoring. As we may guess, our front-end will no longer get the final status of the order immediately.
7. Container Orchestration Service
The last piece of the puzzle that we want to solve is related to deployment.
What we want in the application is ample redundancy, and a tendency to scale up or down depending upon the need automatically.
We’ve already achieved containerization of services through Docker, and are managing dependencies between them through Docker Compose. While these are fantastic tools in their own right, they don’t help us to achieve what we want.
Therefore, we need a container orchestration service that can take care of redundancy and scalability in our application. While there are several options, one of the popular ones is Kubernetes. Kubernetes provides us with a cloud vendor-agnostic way to achieve highly scalable deployments of containerized workloads.
Kubernetes wraps containers like Docker into Pods, which are the smallest unit of deployment. Further, we can use Deployment to describe the desired state declaratively.
Deployment creates ReplicaSets, which internally is responsible for bringing up the pods. We can describe a minimum number of identical pods that should be running at any point in time. This provides redundancy, and thus high availability.
Let’s see how can we define a Kubernetes deployment for our applications:
apiVersion: apps/v1
kind: Deployment
metadata:
name: inventory-deployment
spec:
replicas: 3
selector:
matchLabels:
name: inventory-deployment
template:
metadata:
labels:
name: inventory-deployment
spec:
containers:
- name: inventory
image: inventory-service-async:latest
ports:
- containerPort: 8081
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: shipping-deployment
spec:
replicas: 3
selector:
matchLabels:
name: shipping-deployment
template:
metadata:
labels:
name: shipping-deployment
spec:
containers:
- name: shipping
image: shipping-service-async:latest
ports:
- containerPort: 8082
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-deployment
spec:
replicas: 3
selector:
matchLabels:
name: order-deployment
template:
metadata:
labels:
name: order-deployment
spec:
containers:
- name: order
image: order-service-async:latest
ports:
- containerPort: 8080Here we’re declaring our deployment to maintain three identical replicas of pods at any time. While this is a good way to add redundancy, it may not be sufficient for varying loads. Kubernetes provides another resource known as the Horizontal Pod Autoscaler, which can scale the number of pods in a deployment based on observed metrics, like CPU utilization.
Please note that we have just covered the scalability aspects of the application hosted on a Kubernetes cluster. This doesn’t necessarily imply that the underlying cluster itself is scalable. Creating a high availability Kubernetes cluster is a non-trivial task and beyond the scope of this article.
8. Resulting Reactive System
Now that we’ve made several improvements in our architecture, it’s perhaps time to evaluate this against the definition of a Reactive System. We’ll keep the evaluation against the four characteristics of a Reactive Systems we discussed earlier:
- Responsive: The adoption of the reactive programming paradigm should help us achieve end-to-end non-blocking, and hence, a responsive application.
- Resilient: Kubernetes deployment with ReplicaSet of the desired number of pods should provide resilience against random failures.
- Elastic: Kubernetes cluster and resources should provide us the necessary support to be elastic in the face of unpredictable loads.
- Message-Driven: Having all service-to-service communication handled asynchronously through a Kafka broker should help us here.
While this looks quite promising, it’s far from over. To be honest, the quest for a truly reactive system should be a continuous exercise of improvements. We can never preempt all that can fail in a highly complex infrastructure where our application is just a small part.
A reactive system will demand reliability from every part that makes the whole. Right from the physical network to infrastructure services like DNS, they all should fall in line to help us achieve the end goal.
Often, it may not be possible for us to manage and provide the necessary guarantees for all of these parts. This is where a managed cloud infrastructure helps alleviate our pain. We can choose from a host of services, like IaaS (Infeastrure-as-a-Service), BaaS (Backend-as-a-Service), and PaaS (Platform-as-a-Service) to delegate the responsibilities to external parties. This leaves us with the responsibility of our application as far as possible.
9. Conclusion
In this article, we went through the basics of reactive systems and how it compares with reactive programming. We created a simple application with multiple microservices, and highlighted the problems we intended to solve with a reactive system.
Then we introduced reactive programming, message-based architecture, and container orchestration service in the architecture to realize a reactive system.
Finally, we discussed the resulting architecture, and how it remains a journey towards the reactive system. This article doesn’t introduce us to all the tools, frameworks, or patterns which can help us create a reactive system, but it introduces us to the journey.

















