Message Delivery Semantics in Streaming Platforms
Last updated: May 23, 2025


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In this tutorial, we’ll discuss message delivery semantics in streaming platforms.
First, we’ll quickly look at events flow through the main components of the streaming platforms. Next, we’ll discuss the common reasons for data loss and duplication in such platforms. Then, we’ll focus on the three major delivery semantics available.
We’ll discuss how we can achieve these semantics in streaming platforms, as well as how they deal with data loss and duplication issues.
In each of the delivery semantics, we’ll very briefly touch upon the ways to obtain the delivery guarantees in Apache Kafka.
2. Basics of Streaming Platform
Simply put, streaming platforms like Apache Kafka and Apache ActiveMQ process events in a real-time or near real-time manner from one or multiple sources (also called producers) and pass them onto one or multiple destinations (also called consumers) for further processing, transformations, analysis, or storage.
Producers and consumers are decoupled via brokers, and this enables scalability.
Some use cases of streaming applications can be a high volume of user activity tracking in an eCommerce site, financial transactions and fraud detection in a real-time manner, autonomous mobile devices that require real-time processing, etc.
There are two important considerations in the message delivery platforms:
- accuracy
- latency
Oftentimes, in distributed, real-time systems, we need to make trade-offs between latency and accuracy depending on what’s more important for the system.
This is where we need to understand the delivery guarantees offered by a streaming platform out of the box or implement the desired one using message metadata and platform configurations.
Next, let’s briefly look at the issues of data loss and duplication in streaming platforms which will then lead us to discuss delivery semantics to manage these issues
3. Possible Data Loss and Duplication Scenarios
In order to understand the data loss and/or duplications in the streaming platforms, let’s quickly step back and have a look at the high-level flow of events in a streaming platform:
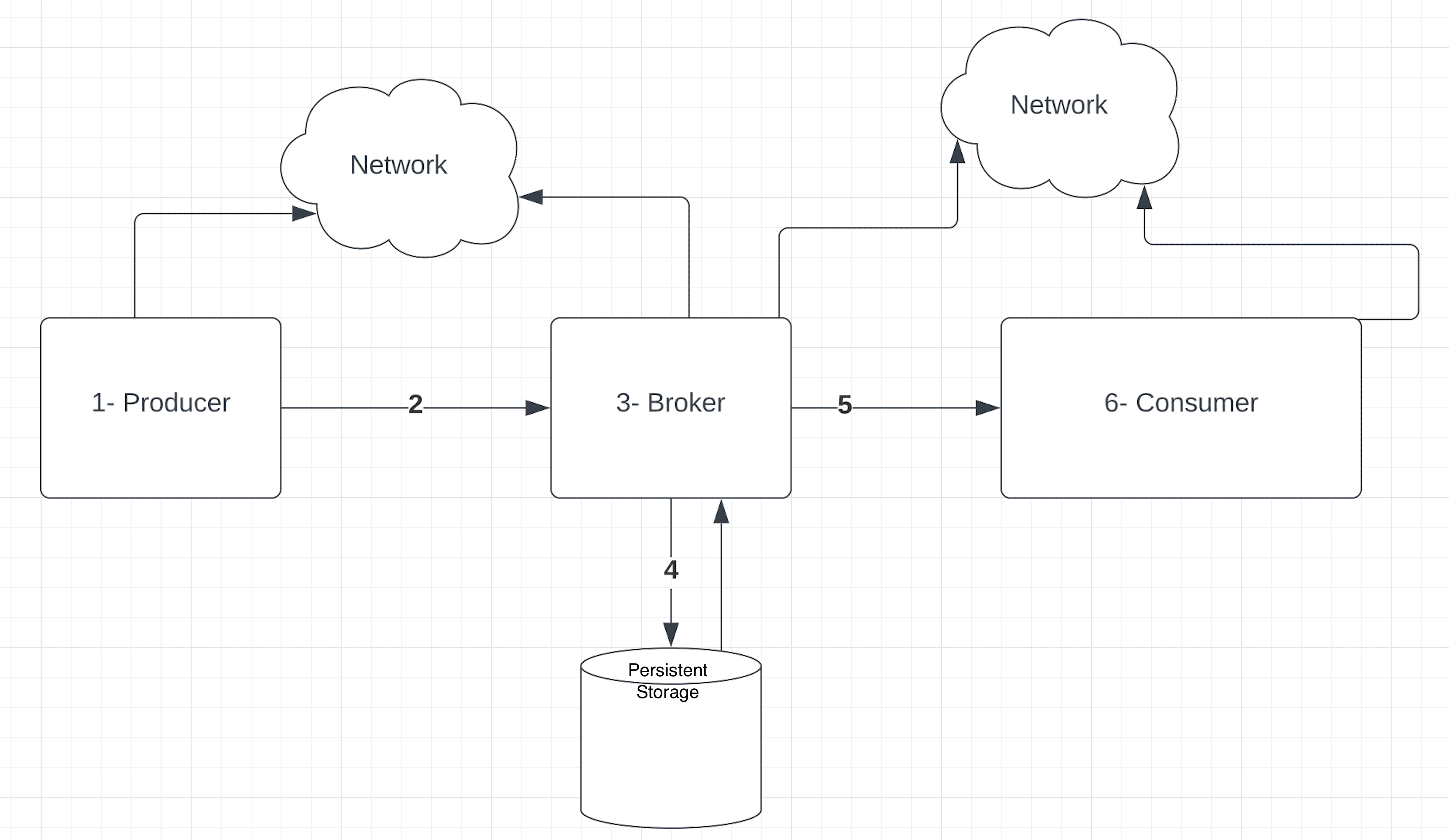
Here, we can see that there can be potentially multiple points of failure along the flow from a producer to the consumer.
Oftentimes, this results in issues like data loss, lags, and duplication of messages.
Let’s focus on each component of the diagram above and see what could go wrong and its possible consequences on the streaming system.
3.1. Producer Failures
Produces failures can lead to some issues:
- After a message is generated by the producer, it may fail before sending it over the network. This may cause data loss.
- The producer may fail while waiting to receive an acknowledgment from the broker. When the producer recovers, it tries to resend the message assuming missing acknowledgment from the broker. This may cause data duplication at the broker.
3.2. Network Issues Between Producer and Broker
There can be a network failure between the producer and broker:
- The producer may send a message which never gets to the broker due to network issues.
- There can also be a scenario where the broker receives the message and sends the acknowledgment, but the producer never receives the acknowledgment due to network issues.
In both these cases, the producer will resend the message, which results in data duplication at the broker.
3.3. Broker Failures
Similarly, broker failures can also cause data duplication:
- A broker may fail after committing the message to persistent storage and before sending the acknowledgment to the producer. This can cause the resending of data from producers leading to data duplication.
- A broker may be tracking the messages consumers have read so far. The broker may fail before committing this information. This can cause consumers to read the same message multiple times leading to data duplication.
3.4. Message Persistence Issue
There may be a failure during writing data to the disk from the in-memory state leading to data loss.
3.5. Network Issues Between the Consumer and the Broker
There can be network failure between the broker and the consumer:
- The consumer may never receive the message despite the broker sending the message and recording that it sent the message.
- Similarly, a consumer may send the acknowledgment after receiving the message, but the acknowledgment may never get to the broker.
In both cases, the broker may resend the message leading to data duplication
3.6. Consumer Failures
- The consumer may fail before processing the message.
- The consumer may fail before recording in persistence storage that it processed the message.
- The consumer may also fail after recording that it processed the message but before sending the acknowledgment.
This may lead to the consumer requesting the same message from the broker again, causing data duplication.
Next, let’s look at the delivery semantics available in streaming platforms to deal with these issues to cater to individual system requirements.
4. Delivery Semantics
Delivery semantics define how streaming platforms guarantee the delivery of events from source to destination in our streaming applications.
There are three different delivery semantics available:
- at-most-once
- at-least-once
- exactly-once
4.1. At-Most-Once Delivery
In this approach, the consumer saves the position of the last received event first and then processes it.
Simply put, if the event processing fails in the middle, upon consumer restart, it cannot go back to read the old event.
Consequently, there’s no guarantee of successful event processing across all received events.
At-most semantics are ideal for situations where some data loss is not an issue and accuracy is not mandatory.
Considering the example of Apache Kafka, which uses offsets for messages, the sequence of the At-Most-Once guarantee would be:
- persist offsets
- persist results
In order to enable At-Most-Once semantics in Kafka, we’ll need to set “enable.auto.commit” to “true” at the consumer.
If there’s a failure and the consumer restarts, it will look at the last persisted offset. Since the offsets are persisted prior to actual event processing, we cannot establish whether every event received by the consumer was successfully processed or not. In this case, the consumer might end up missing some events.
Let’s visualize this semantic:
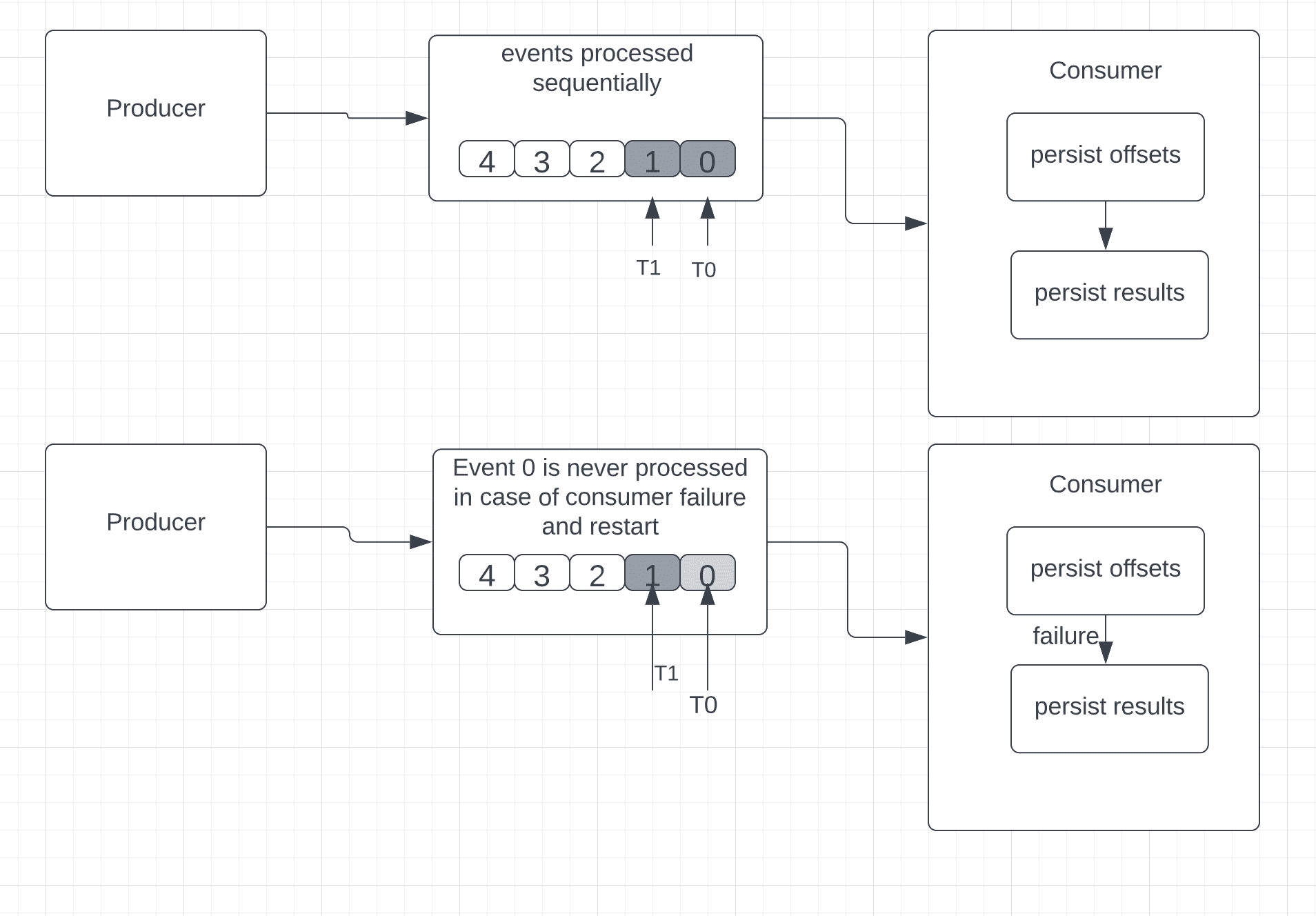
4.2. At-Least-Once Delivery
In this approach, the consumer processes the received event, persists the results somewhere, and then finally saves the position of the last received event.
Unlike at-most-once, here, in case of failure, the consumer can read and reprocess the old events.
In some scenarios, this can lead to data duplication. Let’s consider the example where the consumer fails after processing and saving an event but before saving the last known event position (also known as the offset).
The consumer would restart and read from the offset. Here, the consumer reprocesses the events more than once because even though the message was successfully processed before the failure, the position of the last received event was not saved successfully:
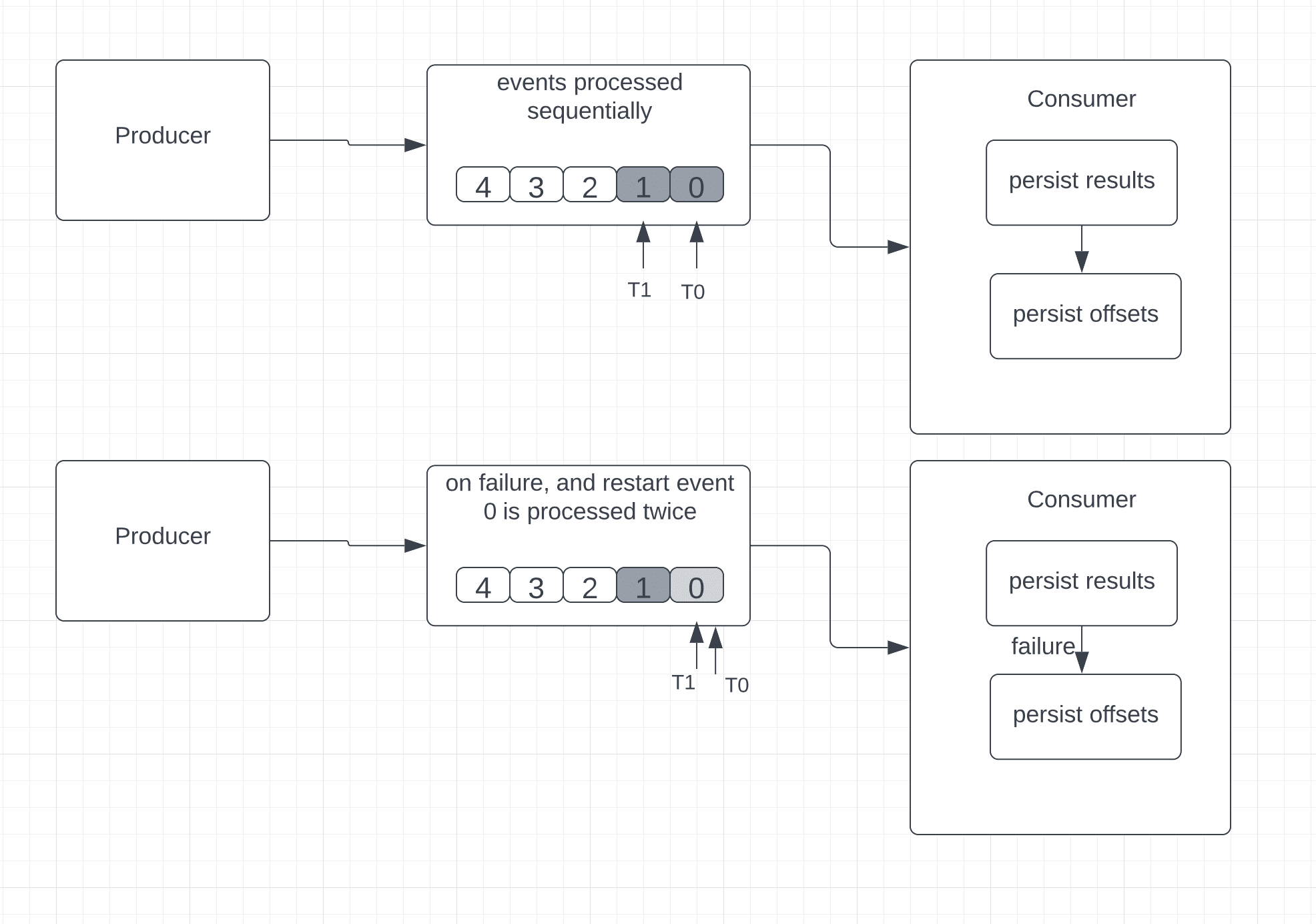
This approach is ideal for any application that updates a ticker or gauge to show a current value. However, use cases that require accuracy in the aggregations, like sums and counters, are not ideal for at-least-once processing, mainly because duplicate events lead to incorrect results.
Consequently, in this delivery semantic, no data is lost, but there can be situations where the same event is reprocessed.
In order to avoid processing the same event multiple times, we can use idempotent consumers.
Essentially an idempotent consumer can consume a message multiple times but only processes it once.
The combination of the following approaches enables idempotent consumers in at-least-once delivery:
- The producer assigns a unique messageId to each message.
- The consumer maintains a record of all processed messages in a database.
- When a new message arrives, the consumer checks it against the existing messageIds in the persistent storage table.
- In case there’s a match, the consumer updates the offset without re-consuming, sends the acknowledgment back, and effectively marks the message as consumed.
- When the event is not already present, a database transaction is started, and a new messageId is inserted. Next, this new message is processed based on whatever business logic is required. On completion of message processing, the transaction’s finally committed
In Kafka, to ensure at-least-once semantics, the producer must wait for the acknowledgment from the broker.
The producer resends the message if it doesn’t receive any acknowledgment from the broker.
Additionally, as the producer writes messages to the broker in batches, if that write fails and the producer retries, messages within the batch may be written more than once in Kafka.
However, to avoid duplication, Kafka introduced the feature of the idempotent producer.
Essentially, in order to enable at-least-once semantics in Kafka, we’ll need to:
- set the property “ack” to value “1” on the producer side
- set “enable.auto.commit” property to value “false” on the consumer side.
- set “enable.idempotence” property to value “true“
- attach the sequence number and producer id to each message from the producer
Kafka Broker can identify the message duplication on a topic using the sequence number and producer id.
4.3. Exactly-Once Delivery
This delivery guarantee is similar to at-least-once semantics. First, the event received is processed, and then the results are stored somewhere. In case of failure and restart, the consumer can reread and reprocess the old events. However, unlike at-least-once processing, any duplicate events are dropped and not processed, resulting in exactly-once processing.
This is ideal for any application in which accuracy is important, such as applications involving aggregations such as accurate counters or anything else that needs an event processed only once and without loss.
The sequence proceeds as follows:
- persist results
- persist offsets
Let’s see what happens when a consumer fails after processing the events but without saving the offsets in the diagram below:
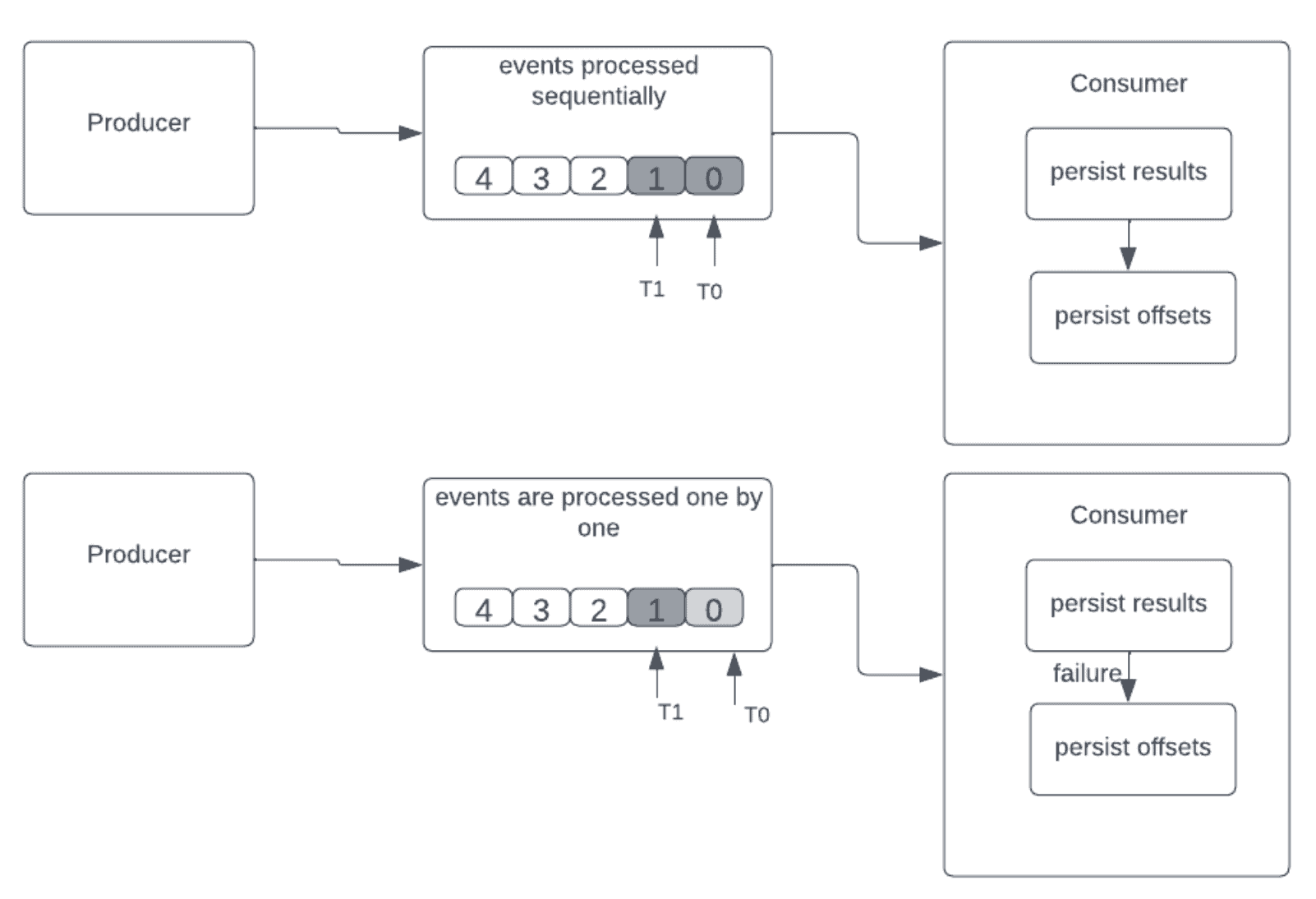
We can remove duplication in exactly-once semantics by having these:
- idempotent updates – we’ll save results on a unique key or ID that is generated. In the case of duplication, the generated key or ID will already be in the results (a database, for example), so the consumer can remove the duplicate without updating the results
- transactional updates – we’ll save the results in batches that require a transaction to begin and a transaction to commit, so in the event of a commit, the events will be successfully processed. Here we will be simply dropping the duplicate events without any results update.
Let’s see what we need to do to enable exactly-once semantics in Kafka:
- enable idempotent producer and transactional feature on the producer by setting the unique value for “transaction.id” for each producer
- enable transaction feature at the consumer by setting property “isolation.level” to value “read_committed“
5. Conclusion
In this article, we’ve seen the differences between the three delivery semantics used in streaming platforms.
After a brief overview of event flow in a streaming platform, we looked at the data loss and duplication issues. Then, we saw how to mitigate these issues using various delivery semantics. We then looked into at-least-once delivery, followed by at-most-once and finally exactly-once delivery semantics.


















