

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In this tutorial, we’re going to see how much space each object consumes in the Java heap.
First, we’ll get familiar with different metrics to calculate object sizes. Then, we’re going to see a few ways to measure instance sizes.
Usually, the memory layout of runtime data areas is not part of the JVM specification and is left to the discretion of the implementor. Therefore, each JVM implementation may have a different strategy to layout objects and arrays in memory. This will, in turn, affect the instance sizes at runtime.
In this tutorial, we’re focusing on one specific JVM implementation: The HotSpot JVM.
We also use the JVM and HotSpot JVM terms interchangeably throughout the tutorial.
2. Shallow, Retained, and Deep Object Sizes
To analyze the object sizes, we can use three different metrics: Shallow, retained, and deep sizes.
When computing the shallow size of an object, we only consider the object itself. That is, if the object has references to other objects, we only consider the reference size to the target objects, not their actual object size. For instance:
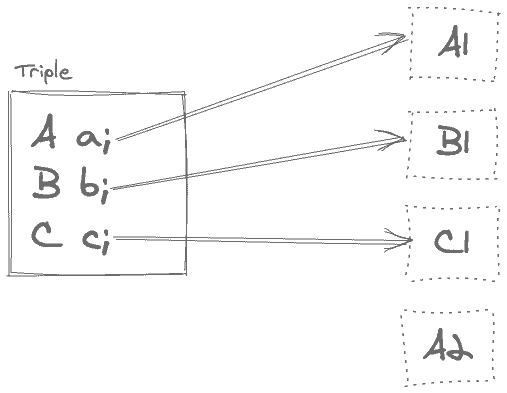
As shown above, the shallow size of the Triple instance is only a sum of three references. We exclude the actual size of the referred objects, namely A1, B1, and C1, from this size.
On the contrary, the deep size of an object includes the size of all referred objects, in addition to the shallow size:

Here the deep size of the Triple instance contains three references plus the actual size of A1, B1, and C1. Therefore, deep sizes are recursive in nature.
When the GC reclaims the memory occupied by an object, it frees a specific amount of memory. That amount is the retained size of that object:
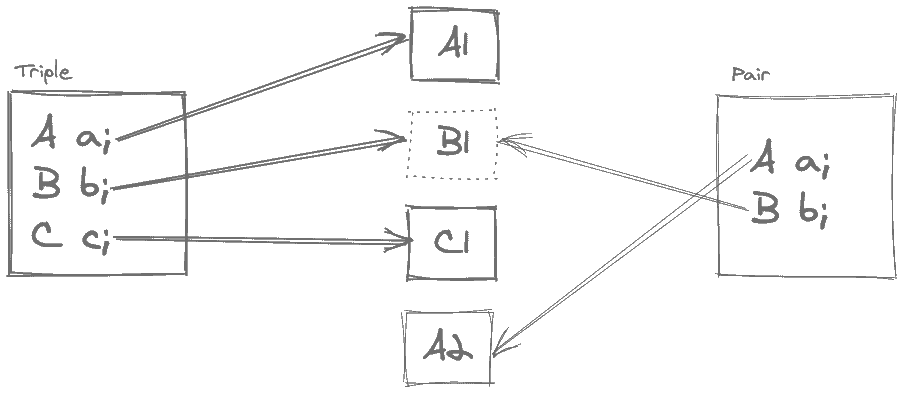
The retained size of the Triple instance only includes A1 and C1 in addition to the Triple instance itself. On the other hand, this retained size doesn’t include the B1, since the Pair instance also has a reference to B1.
Sometimes these extra references are indirectly made by the JVM itself. Therefore, calculating the retained size can be a complicated task.
To better understand the retained size, we should think in terms of the garbage collection. Collecting the Triple instance makes the A1 and C1 unreachable, but the B1 is still reachable through another object. Depending on the situation, the retained size can be anywhere between the shallow and deep size.
3. Dependency
To inspect the memory layout of objects or arrays in the JVM, we’re going to use the Java Object Layout (JOL) tool. Therefore, we’ll need to add the jol-core dependency:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>4. Simple Data Types
To have a better understanding of the size of more complex objects, we should first know how much space each simple data type consumes. To do that, we can ask the Java Memory Layout or JOL to print the VM information:
System.out.println(VM.current().details());The above code will print the simple data type sizes as following:
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]So here are the space requirements for each simple data type in the JVM:
- Object references consume 4 bytes
- boolean and byte values consume 1 byte
- short and char values consume 2 bytes
- int and float values consume 4 bytes
- long and double values consume 8 bytes
This is true in 32-bit architectures and also 64-bit architectures with compressed references in effect.
It’s also worth mentioning that all data types consume the same amount of memory when used as array component types.
4.1. Uncompressed References
If we disable the compressed references via -XX:-UseCompressedOops tuning flag, then the size requirements will change:
# Objects are 8 bytes aligned.
# Field sizes by type: 8, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 8, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]Now object references will consume 8 bytes instead of 4 bytes. The remaining data types still consume the same amount of memory.
Moreover, the HotSpot JVM also can’t use the compressed references when the heap size is more than 32 GB (unless we change the object alignment).
The bottom line is if we disable the compressed references explicitly or the heap size is more than 32 GB, the object references will consume 8 bytes.
Now that we know the memory consumption for basic data types, let’s calculate it for more complex objects.
5. Complex Objects
To calculate the size for complex objects, let’s consider a typical professor to course relationship:
public class Course {
private String name;
// constructor
}Each Professor, in addition to the personal details, can have a list of Courses:
public class Professor {
private String name;
private boolean tenured;
private List<Course> courses = new ArrayList<>();
private int level;
private LocalDate birthDay;
private double lastEvaluation;
// constructor
}5.1. Shallow Size: the Course Class
The shallow size of the Course class instances should include a 4-byte object reference (for name field) plus some object overhead. We can check this assumption using JOL:
System.out.println(ClassLayout.parseClass(Course.class).toPrintable());This will print the following:
Course object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 java.lang.String Course.name N/A
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes totalAs shown above, the shallow size is 16 bytes, including a 4 bytes object reference to the name field plus the object header.
5.2. Shallow Size: the Professor Class
If we run the same code for the Professor class:
System.out.println(ClassLayout.parseClass(Professor.class).toPrintable());Then JOL will print the memory consumption for the Professor class like the following:
Professor object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 int Professor.level N/A
16 8 double Professor.lastEvaluation N/A
24 1 boolean Professor.tenured N/A
25 3 (alignment/padding gap)
28 4 java.lang.String Professor.name N/A
32 4 java.util.List Professor.courses N/A
36 4 java.time.LocalDate Professor.birthDay N/A
Instance size: 40 bytes
Space losses: 3 bytes internal + 0 bytes external = 3 bytes totalAs we probably expected, the encapsulated fields are consuming 25 bytes:
- Three object references, each of which consumes 4 bytes. So 12 bytes in total for referring to other objects
- One int which consumes 4 bytes
- One boolean which consumes 1 byte
- One double which consumes 8 bytes
Adding the 12 bytes overhead of the object header plus 3 bytes of alignment padding, the shallow size is 40 bytes.
The key takeaway here is, in addition to the encapsulated state of each object, we should consider the object header and alignment paddings when calculating different object sizes.
5.3. Shallow Size: an Instance
The sizeOf() method in JOL provides a much simpler way to compute the shallow size of an object instance. If we run the following snippet:
String ds = "Data Structures";
Course course = new Course(ds);
System.out.println("The shallow size is: " + VM.current().sizeOf(course));It’ll print the shallow size as follows:
The shallow size is: 165.4. Uncompressed Size
If we disable the compressed references or use more than 32 GB of the heap, the shallow size will increase:
Professor object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 16 (object header) N/A
16 8 double Professor.lastEvaluation N/A
24 4 int Professor.level N/A
28 1 boolean Professor.tenured N/A
29 3 (alignment/padding gap)
32 8 java.lang.String Professor.name N/A
40 8 java.util.List Professor.courses N/A
48 8 java.time.LocalDate Professor.birthDay N/A
Instance size: 56 bytes
Space losses: 3 bytes internal + 0 bytes external = 3 bytes totalWhen the compressed references are disabled, the object header and object references will consume more memory. Therefore, as shown above, now the same Professor class consumes 16 more bytes.
5.5. Deep Size
To calculate the deep size, we should include the full size of the object itself and all of its collaborators. For instance, for this simple scenario:
String ds = "Data Structures";
Course course = new Course(ds);The deep size of the Course instance is equal to the shallow size of the Course instance itself plus the deep size of that particular String instance.
With that being said, let’s see how much space that String instance consumes:
System.out.println(ClassLayout.parseInstance(ds).toPrintable());Each String instance encapsulates a char[] (more on this later) and an int hashcode:
java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00
4 4 (object header) 00 00 00 00
8 4 (object header) da 02 00 f8
12 4 char[] String.value [D, a, t, a, , S, t, r, u, c, t, u, r, e, s]
16 4 int String.hash 0
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes totalThe shallow size of this String instance is 24 bytes, which include the 4 bytes of cached hash code, 4 bytes of char[] reference, and other typical object overhead.
To see the actual size of the char[], we can parse its class layout, too:
System.out.println(ClassLayout.parseInstance(ds.toCharArray()).toPrintable());The layout of the char[] looks like this:
[C object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00
4 4 (object header) 00 00 00 00
8 4 (object header) 41 00 00 f8
12 4 (object header) 0f 00 00 00
16 30 char [C.<elements> N/A
46 2 (loss due to the next object alignment)
Instance size: 48 bytes
Space losses: 0 bytes internal + 2 bytes external = 2 bytes totalSo, we have 16 bytes for the Course instance, 24 bytes for the String instance, and finally 48 bytes for the char[]. In total, the deep size of that Course instance is 88 bytes.
With the introduction of compact strings in Java 9, the String class is internally using a byte[] to store the characters:
java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION
0 4 (object header)
4 4 (object header)
8 4 (object header)
12 4 byte[] String.value # the byte array
16 4 int String.hash
20 1 byte String.coder # encodig
21 3 (loss due to the next object alignment)Therefore, on Java 9+, the total footprint of the Course instance will be 72 bytes instead of 88 bytes.
5.6. Object Graph Layout
Instead of parsing the class layout of each object in an object graph separately, we can use the GraphLayout. With GraphLayot, we just pass the starting point of the object graph, and it’ll report the layout of all reachable objects from that starting point. This way, we can calculate the deep size of the starting point of the graph.
For instance, we can see the total footprint of the Course instance as follows:
System.out.println(GraphLayout.parseInstance(course).toFootprint());Which prints the following summary:
Course@67b6d4aed footprint:
COUNT AVG SUM DESCRIPTION
1 48 48 [C
1 16 16 com.baeldung.objectsize.Course
1 24 24 java.lang.String
3 88 (total)That’s 88 bytes in total. The totalSize() method returns the total footprint of the object, which is 88 bytes:
System.out.println(GraphLayout.parseInstance(course).totalSize());6. Instrumentation
To calculate the shallow size of an object, we can also use the Java instrumentation package and Java agents. First, we should create a class with a premain() method:
public class ObjectSizeCalculator {
private static Instrumentation instrumentation;
public static void premain(String args, Instrumentation inst) {
instrumentation = inst;
}
public static long sizeOf(Object o) {
return instrumentation.getObjectSize(o);
}
}As shown above, we’ll use the getObjectSize() method to find the shallow size of an object. We also need a manifest file:
Premain-Class: com.baeldung.objectsize.ObjectSizeCalculatorThen using this MANIFEST.MF file, we can create a JAR file and use it as a Java agent:
$ jar cmf MANIFEST.MF agent.jar *.classFinally, if we run any code with the -javaagent:/path/to/agent.jar argument, then we can use the sizeOf() method:
String ds = "Data Structures";
Course course = new Course(ds);
System.out.println(ObjectSizeCalculator.sizeOf(course));This will print 16 as the shallow size of the Course instance.
7. Class Stats
To see the shallow size of objects in an already running application, we can take a look at the class stats using the jcmd:
$ jcmd <pid> GC.class_stats [output_columns]For instance, we can see each instance size and number of all the Course instances:
$ jcmd 63984 GC.class_stats InstSize,InstCount,InstBytes | grep Course
63984:
InstSize InstCount InstBytes ClassName
16 1 16 com.baeldung.objectsize.CourseAgain, this is reporting the shallow size of each Course instance as 16 bytes.
To see the class stats, we should launch the application with the -XX:+UnlockDiagnosticVMOptions tuning flag.
8. Heap Dump
Using heap dumps is another option to inspect the instance sizes in running applications. This way, we can see the retained size for each instance. To take a heap dump, we can use the jcmd as the following:
$ jcmd <pid> GC.heap_dump [options] /path/to/dump/fileFor instance:
$ jcmd 63984 GC.heap_dump -all ~/dump.hproThis will create a heap dump in the specified location. Also, with the -all option, all reachable and unreachable objects will be present in the heap dump. Without this option, the JVM will perform a full GC before creating the heap dump.
After getting the heap dump, we can import it into tools like Visual VM:
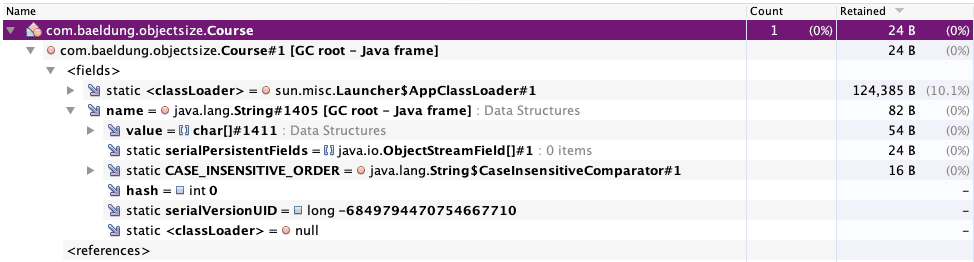
As shown above, the retained size of the only Course instance is 24 bytes. As mentioned earlier, the retained size can be anywhere between shallow (16 bytes) and deep sizes (88 bytes).
It’s also worth mentioning that the Visual VM was part of the Oracle and Open JDK distributions before Java 9. However, this is no longer the case as of Java 9, and we should download the Visual VM from its website separately.
9. Conclusion
In this tutorial, we got familiar with different metrics to measure object sizes in the JVM runtime. After that, we actually did measure instance sizes with various tools such as JOL, Java Agents, and the jcmd command-line utility.


















