

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
The JVM manages memory for us. This removes the memory management burden from the developers, so we don’t need to manipulate object pointers manually, which is proven to be time consuming and error-prone.
Under the hood, the JVM incorporates a lot of nifty tricks to optimize the memory management process. One trick is the use of Compressed Pointers, which we’re going evaluate in this article. First off, let’s see how the JVM represents objects at runtime.
2. Runtime Object Representation
The HotSpot JVM uses a data structure called oops or Ordinary Object Pointers to represent objects. These oops are equivalent to native C pointers. The instanceOops are a special kind of oop that represents the object instances in Java. Moreover, the JVM also supports a handful of other oops that are kept in the OpenJDK source tree.
Let’s see how the JVM lays out instanceOops in memory.
2.1. Object Memory Layout
The memory layout of an instanceOop is simple: it’s just the object header immediately followed by zero or more references to instance fields.
The JVM representation of an object header consists of:
- One mark word serves many purposes such as Biased Locking, Identity Hash Values, and GC. It’s not an oop, but for historical reasons, it resides in the OpenJDK’s oop source tree. Also, the mark word state only contains a uintptr_t, therefore, its size varies between 4 and 8 bytes in 32-bit and 64-bit architectures, respectively
- One, possibly compressed, Klass word, which represents a pointer to class metadata. Before Java 7, they were pointing to the Permanent Generation, but from the Java 8 onward, they are pointing to the Metaspace
- A 32-bit gap to enforce object alignment. This makes the layout more hardware friendly, as we will see later
Immediately after the header, there are to be zero or more references to instance fields. In this case, a word is a native machine word, so 32-bit on legacy 32-bit machines and 64-bit on more modern systems.
The object header of arrays, in addition to mark and klass words, contains a 32-bit word to represent its length.
2.2. Anatomy of Waste
Suppose we’re going to switch from a legacy 32-bit architecture to a more modern 64-bit machine. At first, we may expect to get an immediate performance boost. However, that’s not always the case when the JVM is involved.
The main culprit for this possible performance degradation is 64-bit object references. 64-bit references take up twice the space of 32-bit references, so this leads to more memory consumption in general and more frequent GC cycles. The more time dedicated to GC cycles, the fewer CPU execution slices for our application threads.
So, should we switch back and use those 32-bit architectures again? Even if this were an option, we couldn’t have more than 4 GB of heap space in 32-bit process spaces without a bit more work.
3. Compressed OOPs
As it turns out, the JVM can avoid wasting memory by compressing the object pointers or oops, so we can have the best of both worlds: allowing more than 4 GB of heap space with 32-bit references in 64-bit machines!
3.1. Basic Optimization
As we saw earlier, the JVM adds padding to the objects so that their size is a multiple of 8 bytes. With these paddings, the last three bits in oops are always zero. This is because numbers that are a multiple of 8 always end in 000 in binary.
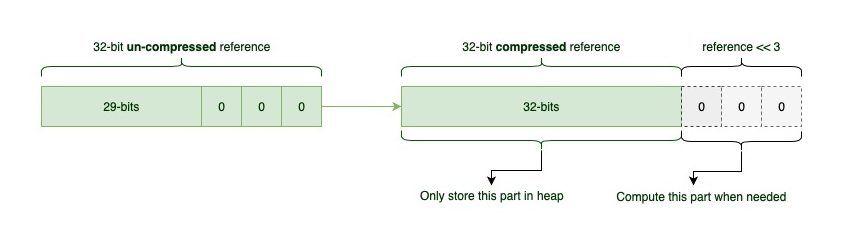
Since the JVM already knows that the last three bits are always zero, there’s no point in storing those insignificant zeros in the heap. Instead, it assumes they are there and stores 3 other more significant bits that we couldn’t fit into 32-bits previously. Now, we have a 32-bit address with 3 right-shifted zeros, so we’re compressing a 35-bit pointer into a 32-bit one. This means that we can use up to 32 GB – 232+3=235=32 GB – of heap space without using 64-bit references.
In order to make this optimization work, when the JVM needs to find an object in memory it shifts the pointer to left by 3 bits (basically adds those 3-zeros back on to the end). On the other hand, when loading a pointer to the heap, the JVM shifts the pointer to right by 3 bits to discard those previously added zeros. Basically, the JVM performs a little bit more computation to save some space. Luckily, bit shifting is a really trivial operation for most CPUs.
To enable oop compression, we can use the -XX:+UseCompressedOops tuning flag. The oop compression is the default behavior from Java 7 onwards whenever the maximum heap size is less than 32 GB. When the maximum heap size is more than 32 GB, the JVM will automatically switch off the oop compression. So memory utilization beyond a 32 Gb heap size needs to be managed differently.
3.2. Beyond 32 GB
It’s also possible to use compressed pointers when Java heap sizes are greater than 32GB. Although the default object alignment is 8 bytes, this value is configurable using the -XX:ObjectAlignmentInBytes tuning flag. The specified value should be a power of two and must be within the range of 8 and 256.
We can calculate the maximum possible heap size with compressed pointers as follows:
4 GB * ObjectAlignmentInBytesFor example, when the object alignment is 16 bytes, we can use up to 64 GB of heap space with compressed pointers.
Please note that as the alignment value increases, the unused space between objects might also increase. As a result, we may not realize any benefits from using compressed pointers with large Java heap sizes.
3.3. Futuristic GCs
ZGC, a new addition in Java 11, was an experimental and scalable low-latency garbage collector.
It can handle different ranges of heap sizes while keeping the GC pauses under 10 milliseconds. Since ZGC needs to use 64-bit colored pointers, it does not support compressed references. So, using an ultra-low latency GC like ZGC has to be weighed against using more memory.
As of Java 15, ZGC supports the compressed class pointers but still lacks the support for Compressed OOPs.
All new GC algorithms, however, won’t trade off memory for being low-latency. For instance, Shenandoah GC supports compressed references in addition to being a GC with low pause times.
Moreover, both Shenandoah and ZGC are finalized as of Java 15.
4. Conclusion
In this article, we described a JVM memory management issue in 64-bit architectures. We looked at compressed pointers and object alignment, and we saw how the JVM can address these issues, allowing us to use larger heap sizes with less wasteful pointers and a minimum of extra computation.
For a more detailed discussion on compressed references, it’s highly recommended to check out yet another great piece from Aleksey Shipilëv. Also, to see how object allocation works inside the HotSpot JVM, check out the Memory Layout of Objects in Java article.

















