

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
Java 8 introduced the Stream API that makes it easy to iterate over collections as streams of data. It’s also very easy to create streams that execute in parallel and make use of multiple processor cores.
We might think that it’s always faster to divide the work on more cores. But that is often not the case.
In this tutorial, we’ll explore the differences between sequential and parallel streams. We’ll first look at the default fork-join pool used by parallel streams.
We’ll also consider the performance implications of using a parallel stream, including memory locality and splitting/merging costs.
Finally, we’ll recommend when it makes sense to covert a sequential stream into a parallel one.
Further reading:
The Java Stream API Tutorial
Guide to Java Parallel Collectors Library
Collect a Java Stream to an Immutable Collection
2. Streams in Java
A stream in Java is simply a wrapper around a data source, allowing us to perform bulk operations on the data in a convenient way.
It doesn’t store data or make any changes to the underlying data source. Rather, it adds support for functional-style operations on data pipelines.
2.1. Sequential Streams
By default, any stream operation in Java is processed sequentially, unless explicitly specified as parallel.
Sequential streams use a single thread to process the pipeline:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
listOfNumbers.stream().forEach(number ->
System.out.println(number + " " + Thread.currentThread().getName())
);The output of this sequential stream is predictable. The list elements will always be printed in an ordered sequence:
1 main
2 main
3 main
4 main2.2. Parallel Streams
Any stream in Java can easily be transformed from sequential to parallel.
We can achieve this by adding the parallel method to a sequential stream or by creating a stream using the parallelStream method of a collection:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
listOfNumbers.parallelStream().forEach(number ->
System.out.println(number + " " + Thread.currentThread().getName())
);Parallel streams enable us to execute code in parallel on separate cores. The final result is the combination of each individual outcome.
However, the order of execution is out of our control. It may change every time we run the program:
4 ForkJoinPool.commonPool-worker-3
2 ForkJoinPool.commonPool-worker-5
1 ForkJoinPool.commonPool-worker-7
3 main3. Fork-Join Framework
Parallel streams make use of the fork-join framework and its common pool of worker threads.
The fork-join framework was added to java.util.concurrent in Java 7 to handle task management between multiple threads.
3.1. Splitting Source
The fork-join framework is in charge of splitting the source data between worker threads and handling callback on task completion.
Let’s take a look at an example of calculating a sum of integers in parallel.
We’ll make use of the reduce method and add five to the starting sum, instead of starting from zero:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
int sum = listOfNumbers.parallelStream().reduce(5, Integer::sum);
assertThat(sum).isNotEqualTo(15);In a sequential stream, the result of this operation would be 15.
But since the reduce operation is handled in parallel, the number five actually gets added up in every worker thread:
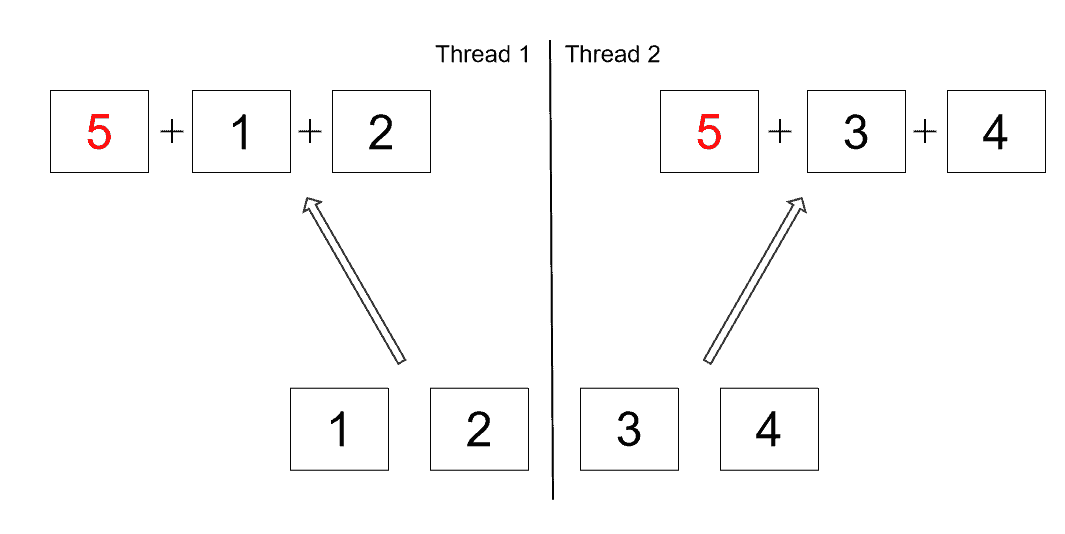
The actual result might differ depending on the number of threads used in the common fork-join pool.
In order to fix this issue, the number five should be added outside of the parallel stream:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
int sum = listOfNumbers.parallelStream().reduce(0, Integer::sum) + 5;
assertThat(sum).isEqualTo(15);Therefore, we need to be careful about which operations can be run in parallel.
3.2. Common Thread Pool
The number of threads in the common pool is equal to (the number of processor cores -1).
However, the API allows us to specify the number of threads it will use by passing a JVM parameter:
-D java.util.concurrent.ForkJoinPool.common.parallelism=4It’s important to remember that this is a global setting and that it will affect all parallel streams and any other fork-join tasks that use the common pool. We strongly suggest that this parameter is not modified unless we have a very good reason for doing so.
3.3. Custom Thread Pool
Besides in the default, common thread pool, it’s also possible to run a parallel stream in a custom thread pool:
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
ForkJoinPool customThreadPool = new ForkJoinPool(4);
int sum = customThreadPool.submit(
() -> listOfNumbers.parallelStream().reduce(0, Integer::sum)).get();
customThreadPool.shutdown();
assertThat(sum).isEqualTo(10);Note that using the common thread pool is recommended by Oracle. We should have a very good reason for running parallel streams in custom thread pools.
4. Performance Implications
Parallel processing may be beneficial to fully utilize multiple cores. But we also need to consider the overhead of managing multiple threads, memory locality, splitting the source and merging the results.
4.1. The Overhead
Let’s take a look at an example integer stream.
We’ll run a benchmark on a sequential and parallel reduction operation:
IntStream.rangeClosed(1, 100).reduce(0, Integer::sum);
IntStream.rangeClosed(1, 100).parallel().reduce(0, Integer::sum);On this simple sum reduction, converting a sequential stream into a parallel one resulted in worse performance:
Benchmark Mode Cnt Score Error Units
SplittingCosts.sourceSplittingIntStreamParallel avgt 25 35476,283 ± 204,446 ns/op
SplittingCosts.sourceSplittingIntStreamSequential avgt 25 68,274 ± 0,963 ns/opThe reason behind this is that sometimes the overhead of managing threads, sources and results is a more expensive operation than doing the actual work.
4.2. Splitting Costs
Splitting the data source evenly is a necessary cost to enable parallel execution, but some data sources split better than others.
Let’s demonstrate this using an ArrayList and a LinkedList:
private static final List<Integer> arrayListOfNumbers = new ArrayList<>();
private static final List<Integer> linkedListOfNumbers = new LinkedList<>();
static {
IntStream.rangeClosed(1, 1_000_000).forEach(i -> {
arrayListOfNumbers.add(i);
linkedListOfNumbers.add(i);
});
}We’ll run a benchmark on a sequential and parallel reduction operation on the two types of lists:
arrayListOfNumbers.stream().reduce(0, Integer::sum)
arrayListOfNumbers.parallelStream().reduce(0, Integer::sum);
linkedListOfNumbers.stream().reduce(0, Integer::sum);
linkedListOfNumbers.parallelStream().reduce(0, Integer::sum);Our results show that converting a sequential stream into a parallel one brings performance benefits only for an ArrayList:
Benchmark Mode Cnt Score Error Units
DifferentSourceSplitting.differentSourceArrayListParallel avgt 25 2004849,711 ± 5289,437 ns/op
DifferentSourceSplitting.differentSourceArrayListSequential avgt 25 5437923,224 ± 37398,940 ns/op
DifferentSourceSplitting.differentSourceLinkedListParallel avgt 25 13561609,611 ± 275658,633 ns/op
DifferentSourceSplitting.differentSourceLinkedListSequential avgt 25 10664918,132 ± 254251,184 ns/opThe reason behind this is that arrays can split cheaply and evenly, while LinkedList has none of these properties. TreeMap and HashSet split better than LinkedList but not as well as arrays.
4.3. Merging Costs
Every time we split the source for parallel computation, we also need to make sure to combine the results in the end.
Let’s run a benchmark on a sequential and parallel stream, with sum and grouping as different merging operations:
arrayListOfNumbers.stream().reduce(0, Integer::sum);
arrayListOfNumbers.stream().parallel().reduce(0, Integer::sum);
arrayListOfNumbers.stream().collect(Collectors.toSet());
arrayListOfNumbers.stream().parallel().collect(Collectors.toSet())Our results show that converting a sequential stream into a parallel one brings performance benefits only for the sum operation:
Benchmark Mode Cnt Score Error Units
MergingCosts.mergingCostsGroupingParallel avgt 25 135093312,675 ± 4195024,803 ns/op
MergingCosts.mergingCostsGroupingSequential avgt 25 70631711,489 ± 1517217,320 ns/op
MergingCosts.mergingCostsSumParallel avgt 25 2074483,821 ± 7520,402 ns/op
MergingCosts.mergingCostsSumSequential avgt 25 5509573,621 ± 60249,942 ns/opThe merge operation is really cheap for some operations, such as reduction and addition, but merge operations like grouping to sets or maps can be quite expensive.
4.4. Memory Locality
Modern computers use a sophisticated multilevel cache to keep frequently used data close to the processor. When a linear memory access pattern is detected, the hardware prefetches the next line of data under the assumption that it will probably be needed soon.
Parallelism brings performance benefits when we can keep the processor cores busy doing useful work. Since waiting for cache misses is not useful work, we need to consider the memory bandwidth as a limiting factor.
Let’s demonstrate this using two arrays, one using a primitive type and the other using an object data type:
private static final int[] intArray = new int[1_000_000];
private static final Integer[] integerArray = new Integer[1_000_000];
static {
IntStream.rangeClosed(1, 1_000_000).forEach(i -> {
intArray[i-1] = i;
integerArray[i-1] = i;
});
}We’ll run a benchmark on a sequential and parallel reduction operation on the two arrays:
Arrays.stream(intArray).reduce(0, Integer::sum);
Arrays.stream(intArray).parallel().reduce(0, Integer::sum);
Arrays.stream(integerArray).reduce(0, Integer::sum);
Arrays.stream(integerArray).parallel().reduce(0, Integer::sum);Our results show that converting a sequential stream into a parallel one brings slightly more performance benefits when using an array of primitives:
Benchmark Mode Cnt Score Error Units
MemoryLocalityCosts.localityIntArrayParallel sequential stream avgt 25 116247,787 ± 283,150 ns/op
MemoryLocalityCosts.localityIntArraySequential avgt 25 293142,385 ± 2526,892 ns/op
MemoryLocalityCosts.localityIntegerArrayParallel avgt 25 2153732,607 ± 16956,463 ns/op
MemoryLocalityCosts.localityIntegerArraySequential avgt 25 5134866,640 ± 148283,942 ns/opAn array of primitives brings the best locality possible in Java. In general, the more pointers we have in our data structure, the more pressure we put on the memory to fetch the reference objects. This can have a negative effect on parallelization, as multiple cores simultaneously fetch the data from memory.
4.5. The NQ Model
Oracle presented a simple model that can help us determine whether parallelism can offer us a performance boost. In the NQ model, N stands for the number of source data elements, while Q represents the amount of computation performed per data element.
The larger the product of N*Q, the more likely we are to get a performance boost from parallelization. For problems with a trivially small Q, such as summing up numbers, the rule of thumb is that N should be greater than 10,000. As the number of computations increases, the data size required to get a performance boost from parallelism decreases.
4.6. File Search Cost
File Search using parallel streams performs better in comparison to sequential streams. Let’s run a benchmark on a sequential and parallel stream for search over 1500 text files:
Files.walk(Paths.get("src/main/resources/")).map(Path::normalize).filter(Files::isRegularFile)
.filter(path -> path.getFileName().toString().endsWith(".txt")).collect(Collectors.toList());
Files.walk(Paths.get("src/main/resources/")).parallel().map(Path::normalize).filter(Files::
isRegularFile).filter(path -> path.getFileName().toString().endsWith(".txt")).
collect(Collectors.toList());Our results show that converting a sequential stream into a parallel one brings slightly more performance benefits when searching a greater number of files:
Benchmark Mode Cnt Score Error Units
FileSearchCost.textFileSearchParallel avgt 25 10808832.831 ± 446934.773 ns/op
FileSearchCost.textFileSearchSequential avgt 25 13271799.599 ± 245112.749 ns/op5. When to Use Parallel Streams
As we’ve seen, we need to be very considerate when using parallel streams.
Parallelism can bring performance benefits in certain use cases. But parallel streams cannot be considered as a magical performance booster. So, sequential streams should still be used as default during development.
A sequential stream can be converted to a parallel one when we have actual performance requirements. Given those requirements, we should first run a performance measurement and consider parallelism as a possible optimization strategy.
A large amount of data and many computations done per element indicate that parallelism could be a good option.
On the other hand, a small amount of data, unevenly splitting sources, expensive merge operations and poor memory locality indicate a potential problem for parallel execution.
6. Conclusion
In this article, we explored the difference between sequential and parallel streams in Java. We learned that parallel streams make use of the default fork-join pool and its worker threads.
Then we saw how parallel streams do not always bring performance benefits. We considered the overhead of managing multiple threads, memory locality, splitting the source and merging the results. We saw that arrays are a great data source for parallel execution because they bring the best possible locality and can split cheaply and evenly.
Finally, we looked at the NQ model and recommended using parallel streams only when we have actual performance requirements.


















