

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
In this tutorial, we’ll discuss the various ways to implement retry policies in gRPC, a remote procedure call framework developed by Google. gRPC is interoperable in many programming languages but we’ll focus on the Java implementation.
2. Importance of Retry
Applications increasingly rely on a distributed architecture. This approach helps handle heavy workloads through horizontal scaling. It also promotes high availability. However, it also introduces more potential points of failure. Therefore, fault tolerance is crucial when developing applications with multiple microservices.
RPCs can fail temporarily or momentarily because of various factors:
- Network latency or connection drops in the network
- Server not responding due to an internal error
- Busy system resources
- Busy or unavailable downstream services
- Other related issues
Retry is a fault-handling mechanism. A retry policy can help automatically reattempt a failed request based on some condition. It can also define how long or how often the client can retry. This simple pattern can help handle transient failures and increase reliability.
3. RPC Failure Stages
Let’s first understand where a remote procedure call (RPC) can fail:
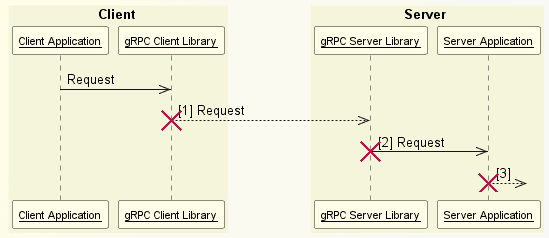
The client application initiates the request, which the gRPC client library sends to the server. Once received, the gRPC server library forwards the request to the server application’s logic.
A RPC can fail at various stages:
- Before leaving the client
- In the server but before reaching the server application logic
- In the server application logic
4. Retry Support in gRPC
Since retry is an important recovery mechanism, gRPC automatically retries failed requests in special cases and allows developers to define retry policies for greater control.
4.1. Transparent Retry
We must understand that gRPC can safely reattempt failed requests only in cases where the request hasn’t reached the application server logic. Beyond that, the gRPC cannot guarantee the idempotency of the transactions. Let’s take a look at the overall transparent retry pathway:
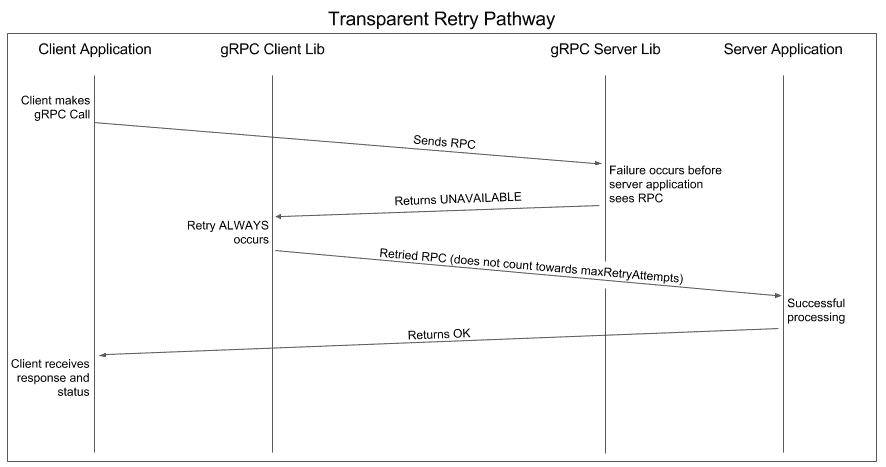
As discussed previously, internal retries can happen safely before leaving the client or in the server but before reaching the server application logic. This retry strategy is referred to as transparent retry. Once the server application successfully processes the request, it returns the response and attempts no further retries.
gRPC can perform a single retry when the RPC reaches the gRPC server library because multiple retries can add load to the network. However, it may retry unlimited times when RPC fails to leave the client.
4.2. Retry Policy
To give developers more control, gRPC supports configuring appropriate retry policies for their applications at the individual service or method level. Once the request crosses Stage 2, it comes under the purview of the configurable retry policy. Service owners or publishers can configure the retry policies of their RPCs with the help of service config, a JSON file.
Service owners, typically distribute the service configuration to the gRPC clients using name resolution services such as DNS. However, in cases where name resolution doesn’t provide a service configuration, service consumers or developers can configure it programmatically.
gRPC supports multiple retry parameters:
| Configuration Name | Description |
|---|---|
| maxAttempts |
|
| initialBackoff |
|
| maxBackoff |
|
| backoffMultiplier |
|
| retryableStatusCodes |
|
Notably, the gRPC client uses initialBackoff, maxBackoff, and backoffMultiplier parameters to randomize the delay before retrying requests.
Sometimes, the server might send an instruction in the response metadata, not to retry or try the request after some delay. This is known as server pushback.
Now that we’ve discussed both transparent and policy-based retry features of gRPC, let’s summarize how gRPC manages retries overall:

5. Programmatically Apply Retry Policy
Let’s say we have a service that can broadcast messages to the citizens by calling an underlying notification service that sends SMS to cell phones. The government uses this service to make announcements on emergencies. The client application using this service must have a retry strategy to mitigate errors due to transient failures.
Let’s explore further on this.
5.1. High-Level Design
First, let’s look at the interface definition in the broadcast.proto file:
syntax = "proto3";
option java_multiple_files = true;
option java_package = "com.baeldung.grpc.retry";
package retryexample;
message NotificationRequest {
string message = 1;
string type = 2;
int32 messageID = 3;
}
message NotificationResponse {
string response = 1;
}
service NotificationService {
rpc notify(NotificationRequest) returns (NotificationResponse){}
}The broadcast.proto file defines NotificationService with a remote method notify() and two DTOs NotificationRequest and NotificationResponse.
Overall, let’s see the classes used in the client and server sides of the gRPC application:

Later, we can use the broadcast.proto file for generating the supporting Java source code for implementing the NotificationService. The Maven plugin generates the classes NotificationRequest, NotificationResponse, and NotificationServiceGrpc.
The GrpcBroadcastingServer class on the server side uses the ServerBuilder class to register NotificationServiceImpl to broadcast messages. The client-side class GrpcBroadcastingClient uses the ManagedChannel classes of the gRPC library to manage the channel to perform the RPCs.
The service config file retry-service-config.json outlines the retry policy:
{
"methodConfig": [
{
"name": [
{
"service": "retryexample.NotificationService",
"method": "notify"
}
],
"retryPolicy": {
"maxAttempts": 5,
"initialBackoff": "0.5s",
"maxBackoff": "30s",
"backoffMultiplier": 2,
"retryableStatusCodes": [
"UNAVAILABLE"
]
}
}
]
}Earlier, we understood the retry policies such as maxAttempts, exponential backoff parameters, and retryableStatusCodes. When the client invokes the remote procedure notify() in NotificationService as defined earlier in the broadcast.proto file, the gRPC framework enforces the retry settings.
5.2. Implement Retry Policy
Let’s take a look at the class GrpcBroadcastingClient:
public class GrpcBroadcastingClient {
protected static Map<String, ?> getServiceConfig() {
return new Gson().fromJson(new JsonReader(new InputStreamReader(GrpcBroadcastingClient.class.getClassLoader()
.getResourceAsStream("retry-service-config.json"), StandardCharsets.UTF_8)), Map.class);
}
public static NotificationResponse broadcastMessage() {
ManagedChannel channel = ManagedChannelBuilder.forAddress("localhost", 8080)
.usePlaintext()
.disableServiceConfigLookUp()
.defaultServiceConfig(getServiceConfig())
.enableRetry()
.build();
return sendNotification(channel);
}
public static NotificationResponse sendNotification(ManagedChannel channel) {
NotificationServiceGrpc.NotificationServiceBlockingStub notificationServiceStub = NotificationServiceGrpc
.newBlockingStub(channel);
NotificationResponse response = notificationServiceStub.notify(NotificationRequest.newBuilder()
.setType("Warning")
.setMessage("Heavy rains expected")
.setMessageID(generateMessageID())
.build());
channel.shutdown();
return response;
}
}The broadcast() method builds the ManagedChannel object with the necessary configurations. Then, we pass it to sendNotification() which further invokes the notify() method on the stub.
The methods in the ManagedChannelBuilder class that play a crucial role in setting up the service config consisting of the retry policy are:
- disableServiceConfigLookup(): Explicitly disables the service config lookup through name resolution
- enableRetry(): Enables per-method configuration for retry
- defaultServiceConfig(): Explicitly sets up the service configuration
The method getServiceConfig() reads the service config from the retry-service-config.json file and returns a Map representation of its content. Subsequently, this Map is passed on to the defaultServiceConfig() method in the ManagedChannelBuilder class.
Finally, after creating the ManagedChannel object, we call the notify() method of the notificationServiceStub object of type NotificationServiceGrpc.NotificationServiceBlockingStub to broadcast the message. The policy works for non-blocking stubs as well.
It’s advisable to use a dedicated class for creating ManagedChannel objects. This allows for centralized management, including the configuration of retry policies.
To demonstrate the retry feature, the NotificationServiceImpl class in the server is designed to be randomly out of service. Let’s take a look at the GrpcBroadcastingClient in action:
@Test
void whenMessageBroadCasting_thenSuccessOrThrowsStatusRuntimeException() {
try {
NotificationResponse notificationResponse = GrpcBroadcastingClient.sendNotification(managedChannel);
assertEquals("Message received: Warning - Heavy rains expected", notificationResponse.getResponse());
} catch (Exception ex) {
assertTrue(ex instanceof StatusRuntimeException);
}
}The method invokes sendNotification() on the GrpcBroadcastingClient class to invoke the server-side remote procedure to broadcast messages. We can examine the logs to verify the retries:
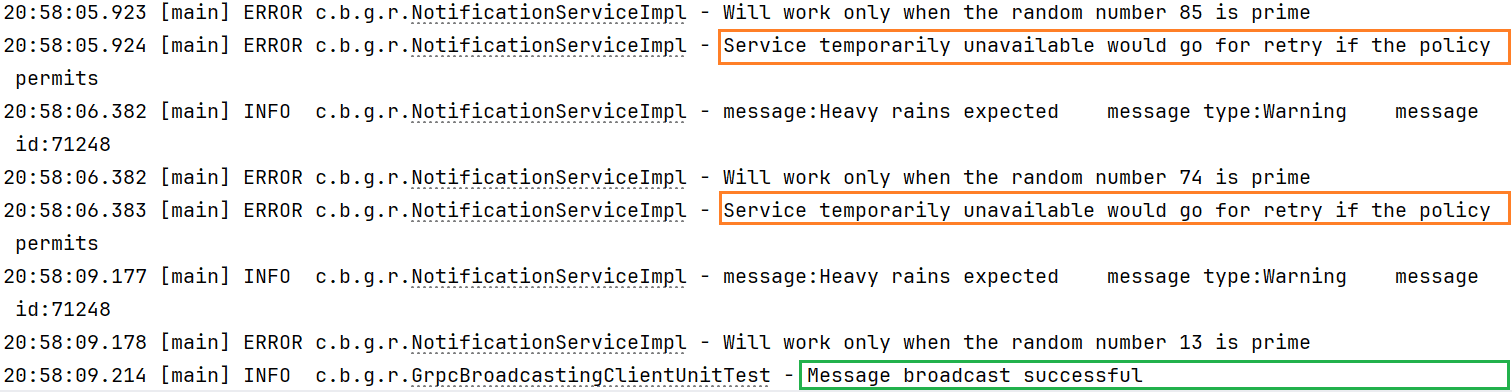
6. Conclusion
In this article, we explored the retry policy feature in the gRPC library. The ability to set up the policy declaratively through a JSON file is a powerful feature. However, we should use it for testing scenarios or when the service config is unavailable during the name resolution.
Retrying failed requests can lead to unpredictable outcomes, hence we should be careful in setting it only for idempotent transactions.

















