

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll study the similarities and differences between high availability and fault tolerance. With the expansion of computer networks and the emergence of cloud computing, networked services have caught on worldwide. Currently, networked services are incorporated into everyday life and are required anywhere and anytime.
Due to this popularization, providers must keep services provided through the network continuously available for the clients. To do so, these providers create agreements of minimum service availability and employ techniques for tolerating and recovering faults.
But, although correlated concepts, high availability and fault tolerance are not equivalents. So, in the following section, we’ll see background concepts. Next, we’ll particularly explore high availability and fault tolerance. At last, we’ll outline the studied concepts and compare them in a systematic summary.
Although high availability and fault tolerance have technically been used for a long time, the popularization of cloud computing is what really drove their evolution.
Cloud computing is not actually a novelty. It has been discussed since the first years of the Internet. However, the cloud got popular with the broad creation and access of networks by multiple and different users.
In short, the cloud provides several computing resources through the Internet. It enables stakeholders to host services online, thus making them available to several clients.
It is relevant to highlight that providing resources in cloud computing can occur through different models, such as Infrastructure-as-Service, Platform-as-a-Service, and Software-as-a-Service.
However, regardless of the adopted model, stakeholders and clients aim to access the provided services at the exact moment they need them. It is here where high availability and fault tolerance takes place: guaranteeing the continuous and correct operation of networked services.
But, before discussing the particularities of high availability and fault tolerance, let’s see an important concept for them: redundancy.
Redundancy is the practice of deploying system component copies (hardware and software). These copies are not necessary for the services’ ordinary operation but are crucial for guaranteeing its availability, detecting faults, and mitigating them.
Due to these characteristics, we’ll see that the following sections explore redundancy in multiple manners.
High availability specifies a design that aims to minimize the downtime of a system or service. So, the main objective of high availability is to keep these systems and services continuously available.
Typically, we measure high availability through the percentage of time that a service is guaranteed to be online and available for use in a year. The most common availability classes are:
Of course, there are even more restrictive high-availability classes. These classes, in turn, imply maximum downtimes of seconds (six nines and beyond) or milliseconds (eight nines and beyond) per year. But, they are challenging to implement and are usually considered only for specific sensitive scenarios.
To calculate the availability class of a given system, we can use the following equation:

Where  means the total downtime, and we can assume the
means the total downtime, and we can assume the  as:
as:

In a naive way, we can say that as higher the number of nines in a highly available system, the better it is. But, guaranteeing several nines is complex and represents high financial costs. So, the best high-availability class is the one that meets all the agreements established between providers and clients.
Commonly, high availability relies on a set of replicated components acting as a single system or service. These component sets are often called high-availability clusters.
High-availability clusters share resources among themselves. For example, they can share databases and configuration files. Thus, in failure cases or overloading scenarios, the replicas are data-consistent to assume the service and start working as soon as possible.
The following figure depicts a simplified high-available system architecture:
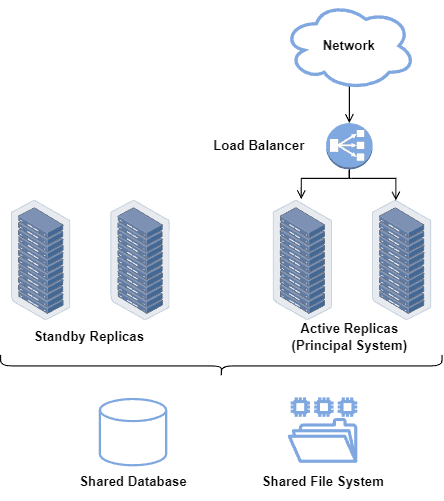
Note that the replicated systems and services may be kept in standby mode, used only when the principal systems fail somehow. In this way, we consider the time between a system failure and a replicated system starting working as inoperative time (which tends to be low, according to the desired high availability class).
Fault tolerance indicates the capability of a system to operate even with the occurrence of faults. Furthermore, fault-tolerant systems can adopt strategies to recover faulty components during their lifecycles.
We can see a fault as a condition of a component that makes it behave differently from the expected. So, when a fault manifests, we call it an error, and if an error compromises the system operation, we have a failure event.
But, before talking about fault tolerance, we should understand to which faults it refers. In short, there are three main fault models typically explored in this context:
Thus, fault-tolerant systems are first designed to detect and deal with a certain number of faults (considering a particular model), providing the correct result even with compromised components.
Due to the presented characteristics, we expect that fault-tolerant systems have high reliability (confidence that a system works as expected), high availability (keeping the system operating continuously, as previously discussed), and high testability (capability to detect and diagnose faults by analyzing errors and failures).
Similar to high-available systems, fault-tolerant ones rely, in most cases, on replicated components working together. These components, in turn, do not work as a single one but operate independently, cooperating to converge to a joint result.
In this way, tolerating a  number of faults in a given component means having at least
number of faults in a given component means having at least  replicas in the system. The number , however, depends on which is the adopted fault model but usual values for it are
replicas in the system. The number , however, depends on which is the adopted fault model but usual values for it are  and
and  .
.
In the described scenario, all the replicas receive the same input and should process and propose a result. So, the system then takes the result found by the majority of replicas as the operation result.
The figure next shows a simple example of a fault-tolerant DNS system:
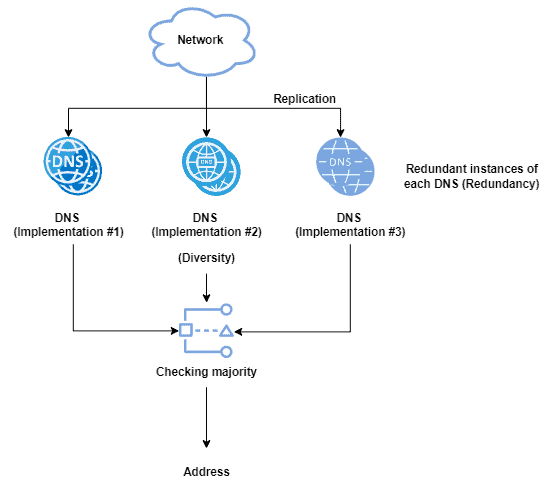
In addition to the previously described replication, fault-tolerant systems also work with redundancy and diversity.
With redundancy, we mean having replicas ready for immediately replacing failed components. With diversity, however, we mean deploying different implementations of a single component specification, reducing the probability of replicating a particular fault.
Due to all those characteristics and requirements, fault tolerance naturally implies complex systems with high capital costs.
In modern networking, multiple services are provided online, typically through the Internet. In many cases, the providers are required to keep these services continuously available for the customers once even quick interruptions may cause catastrophic consequences and enormous financial losses.
But, keeping networked services continuously available is a challenging task. So, several strategies and techniques regarding high availability and fault tolerance have been proposed to tackle this challenge.
However, it is relevant to highlight that high availability and fault tolerance are not the same concept.
High availability refers to a system design that aims to minimize downtime, regardless of the reasons for it occurring. Fault-tolerant systems, in turn, can keep working even with the manifestation of a certain number of faults.
In such a way, being a fault-tolerant system does not necessarily imply being a high-available system, nor does being a high-available system indicate being a fault-tolerant one. However, high availability and fault tolerance work well together to create robust systems and services.
The following table compares some characteristics of high availability and fault tolerance:
| High Availability | Fault Tolerance | |
|---|---|---|
| Objective | Minimizing the systems’ downtime according to certain predefined levels | Keeping services working even with the manifestation of a certain number of faults |
| Characteristics | Redundancy; Shared resources | Redundancy; Replication; Diversity |
| Infrastructure | Multiple redundant elements and management systems to activate and coordinate them as necessary | Multiple replicated elements and management systems to make them work all together |
| Pros | Cheaper than fault-tolerant systems; Easily scalable system design; Naturally load-balanced systems | Zero-interruption designed system; No data loss by design |
| Cons | Hard to keep an availability level; Potential occurrences of data loss | Hard to manage systems (complex); High costs due to replication |
In this tutorial, we investigated high availability and fault tolerance. Initially, we studied some background concepts relevant to both high-available and fault-tolerant systems. After that, we saw definitions and requirements for implementing high availability and fault tolerance in current networked systems. Finally, we compared the analyzed system designs in a systematic summary.
We can conclude that multiple services are being shifted to the online world due to the popularization and expansion of networking and the Internet. Some of these services execute sensitive operations, which must be continuously available. In such a context, high availability and fault tolerance are systems designs that fit well to these services, thus making these designs modern necessities.