Cassandra Batch in Cassandra Query Language and Java
Last updated: May 23, 2025


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In this tutorial, we’ll learn about the Cassandra batch query and its different use cases. We’ll analyze both the single partition and multiple partition tables batch queries.
We’ll explore batching in the Cqlsh as well as in Java applications.
2. Cassandra Batch Fundamentals
A distributed database like Cassandra does not support ACID (Atomicity, Consistency, Isolation, and Durability) properties, unlike relational databases. Still, in some cases, we need multiple data modifications to be an atomic or/and isolated operation.
The batch statement combines multiple data modification language statements (such as INSERT, UPDATE, and DELETE) to achieve atomicity and isolation when targeting a single partition or only atomicity when targeting multiple partitions.
Here’s the syntax for batch query:
BEGIN [ ( UNLOGGED | COUNTER ) ] BATCH
[ USING TIMESTAMP [ epoch_microseconds ] ]
dml_statement [ USING TIMESTAMP [ epoch_microseconds ] ] ;
[ dml_statement [ USING TIMESTAMP [ epoch_microseconds ] ] [ ; ... ] ]
APPLY BATCH;Let’s go through the above syntax with an example:
BEGIN BATCH
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana');
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana');
APPLY BATCH;First, we use the BEGIN BATCH statement without any optional parameters like UNLOGGED or USING TIMESTAMP to initiate the batch query, and then include all the DML operations, i.e., the insert statements for the product table.
Finally, we use the APPLY BATCH statement to execute the batch.
We should note that we’ll not be able to undo any batch query since the batch query does not support rollback functionality.
2.1. Single Partition
A batch statement applies all the DML statements within a single partition, ensuring atomicity and isolation.
A well-designed batch targeting a single partition can reduce client-server traffic and more efficiently update a table with a single row mutation. This is because the batch isolation occurs only if the batch operation is writing to a single partition.
A single partition batch can also involve two different tables having the same partition key and present in the same keyspace.
The single partition batch operations are unlogged by default and thus, do not suffer from performance penalties due to logging.
The below diagram depicts the single partition batch request flow from the coordination node H to the partition node B and its replication nodes C, D:
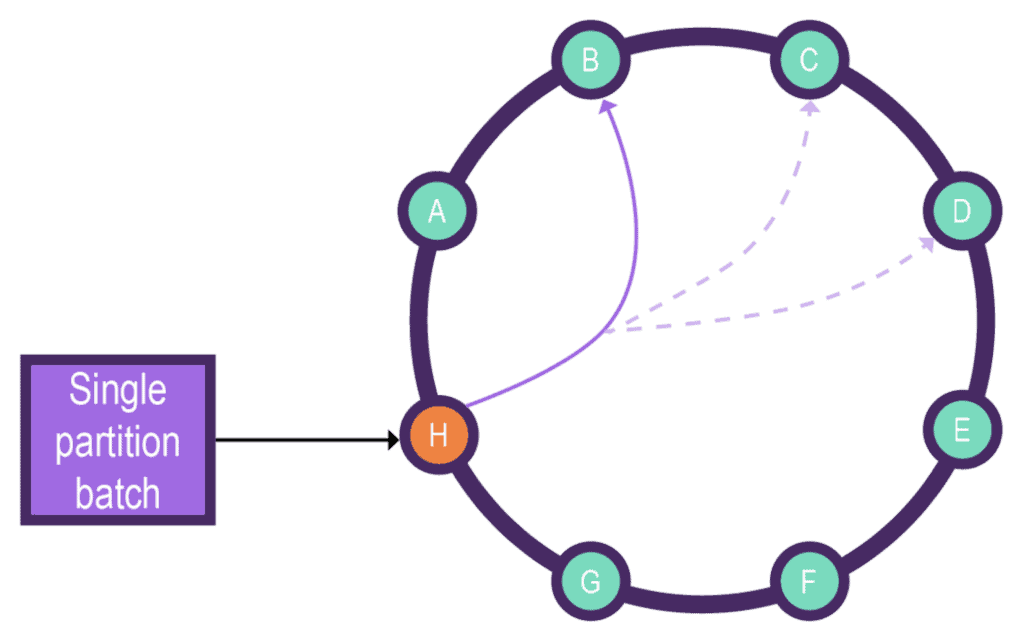
Courtesy: Datastax
2.2. Multiple Partitions
The batch involving multiple partitions needs to be well-designed as it involves coordination between multiple nodes. The best use case for a multi-partition batch is to write the same data into two related tables, i.e., two tables having the same columns with different partition keys.
Multiple partition batch operation uses the batchlog mechanism to ensure atomicity. The coordination node sends batch log requests to batch log nodes, and once it gets a confirmed receipt, it executes the batch statements. Then, it removes the batchlog from the nodes and sends a confirmation to the client.
It is recommended to avoid using multiple partitions batch queries. This is because such queries put huge pressure on the coordination node and severely affect its performance.
We should only use a multiple partition batch when there is no other viable option.
The below diagram depicts the multiple partition batch request flow from the coordination node H to the partition nodes B, E and its respective replication nodes C, D, and F, G:
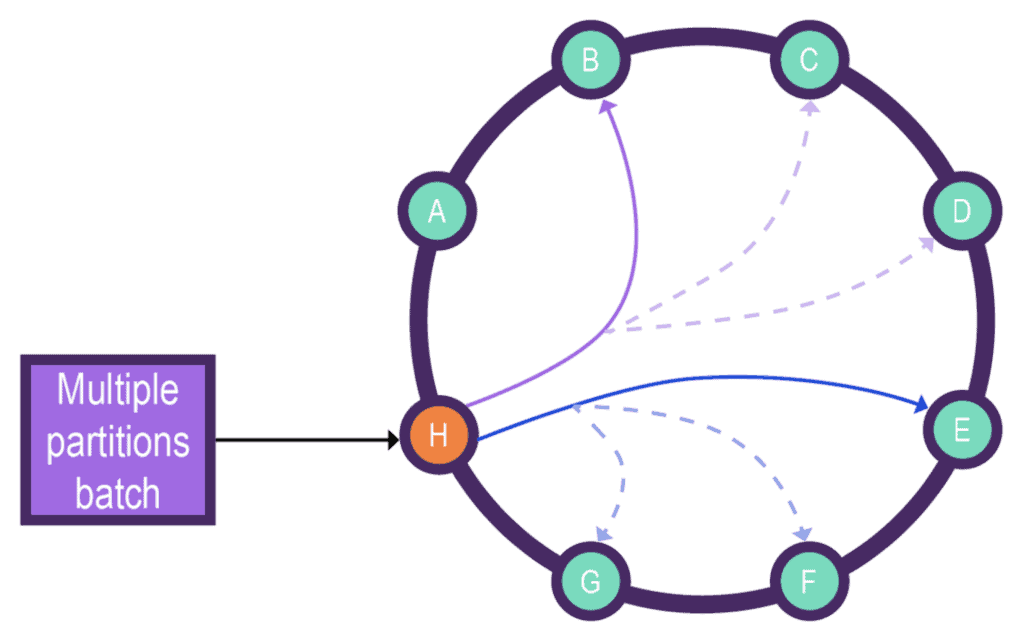
Courtesy: Datastax
3. Batch Execution in Cqlsh
First, let’s create a product table to run through some of the batch queries:
CREATE TABLE product (
product_id UUID,
variant_id UUID,
product_name text,
description text,
price float,
PRIMARY KEY (product_id, variant_id)
);3.1. Single Partition Batch Without Timestamp
We’ll execute the below batch query targeting a single partition of the product table and will not provide timestamp:
BEGIN BATCH
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana') IF NOT EXISTS;
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana') IF NOT EXISTS;
UPDATE product SET price = 7.12, description = 'banana v1'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f3;
UPDATE product SET price = 11.90, description = 'banana v2'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f5;
APPLY BATCH;The above query uses compare-and-set (CAS) logic, i.e., the IF NOT EXISTS clause, and all such conditional statements must return true to execute the batch. If any such statements return false, then the entire batch is unprocessed.
After execution of the above query, we’ll get the below successful acknowledgment:

Let’s now verify if the writetime of the data is the same after batch execution:
cqlsh:testkeyspace> select product_id, variant_id, product_name, description, price, writetime(product_name) from product;
@ Row 1
-------------------------+--------------------------------------
product_id | 3a043b68-20ee-4ece-8f4b-a07e704bc9f5
variant_id | b84b9366-9998-4b2d-9a96-7e9a59a94ae5
product_name | Banana
description | banana v1
price | 12
writetime(product_name) | 1639275574653000
@ Row 2
-------------------------+--------------------------------------
product_id | 3a043b68-20ee-4ece-8f4b-a07e704bc9f5
variant_id | facc3997-299d-419b-b133-a54b5d4dfc3b
product_name | Banana
description | banana v2
price | 12
writetime(product_name) | 16392755746530003.2. Single Partition Batch With Timestamp
We’ll now see examples of batch queries with USING TIMESTAMP option to supply timestamp in epoch time format, i.e., microseconds.
Below is the batch query that applies the same timestamp to all DML statements:
BEGIN BATCH USING TIMESTAMP 1638810270
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana');
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana');
UPDATE product SET price = 7.12, description = 'banana v1'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f3;
UPDATE product SET price = 11.90, description = 'banana v2'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f5;
APPLY BATCH;Let’s now specify custom timestamp on any of the individual DML statements:
BEGIN BATCH
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana');
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana') USING TIMESTAMP 1638810270;
UPDATE product SET price = 7.12, description = 'banana v1'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f3 USING TIMESTAMP 1638810270;
UPDATE product SET price = 11.90, description = 'banana v2'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f5;
APPLY BATCH;We’ll now see an invalid batch query that has both the custom timestamp and compare-and-set (CAS) logic, i.e., IF NOT EXISTS clause:
BEGIN BATCH USING TIMESTAMP 1638810270
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana') IF NOT EXISTS;
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana') IF NOT EXISTS;
UPDATE product SET price = 7.12, description = 'banana v1'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f3;
UPDATE product SET price = 11.90, description = 'banana v2'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f5;
APPLY BATCH;We’ll get the below error on executing the above query:
InvalidRequest: Error from server: code=2200 [Invalid query]
message="Cannot provide custom timestamp for conditional BATCH"The above error is because the client-side timestamps are prohibited for any conditional insert or updates.
3.3. Multiple Partition Batch Query
The best use case for batch on multiple partitions is to insert the exact data into two related tables.
Let’s insert the same data into both product_by_name and product_by_id tables having different partition keys:
BEGIN BATCH
INSERT INTO product_by_name (product_name, product_id, description, price)
VALUES ('banana',2c11bbcd-4587-4d15-bb57-4b23a546bd7f,'banana',12.00);
INSERT INTO product_by_id (product_id, product_name, description, price)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,'banana','banana',12.00);
APPLY BATCH;Let’s now enable the UNLOGGED option to the above query:
BEGIN UNLOGGED BATCH
INSERT INTO product_by_name (product_name, product_id, description, price)
VALUES ('banana',2c11bbcd-4587-4d15-bb57-4b23a546bd7f,'banana',12.00);
INSERT INTO product_by_id (product_id, product_name, description, price)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,'banana','banana',12.00);
APPLY BATCH;The above UNLOGGED batch query will not ensure atomicity or isolation and does not use the batch log to write the data.
3.4. Batching on Counter Updates
We’ll need to use the COUNTER option for any counter columns as counter updates operations are not idempotent.
Let’s create a table product_by_sales which stores sales_vol as Counter datatype:
CREATE TABLE product_by_sales (
product_id UUID,
sales_vol counter,
PRIMARY KEY (product_id)
);The below counter batch query increases the sales_vol twice by 100:
BEGIN COUNTER BATCH
UPDATE product_by_sales
SET sales_vol = sales_vol + 100
WHERE product_id = 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47;
UPDATE product_by_sales
SET sales_vol = sales_vol + 100
WHERE product_id = 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47;
APPLY BATCH4. Batch Operation in Java
Let’s look at a few examples of building and executing the batch query in a Java application.
4.1. Maven Dependency
Firstly, we would need to include the DataStax-related Maven dependencies:
<dependency>
<groupId>com.datastax.oss</groupId>
<artifactId>java-driver-core</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>com.datastax.oss</groupId>
<artifactId>java-driver-query-builder</artifactId>
<version>4.1.0</version>
</dependency>4.2. Single Partition Batch
Let’s look at an example to see how to execute batch into single-partition data.
We’ll build the batch query using the BatchStatement instance. The BatchStatement is instantiated using the DefaultBatchType enum and the BoundStatement instances.
First, we’ll create a method to get a BoundStatement instance by binding Product attributes to a PreparedStatement insert query:
BoundStatement getProductVariantInsertStatement(Product product, UUID productId) {
String insertQuery = new StringBuilder("")
.append("INSERT INTO ")
.append(PRODUCT_TABLE_NAME)
.append("(product_id, variant_id, product_name, description, price) ")
.append("VALUES (")
.append(":product_id")
.append(", ")
.append(":variant_id")
.append(", ")
.append(":product_name")
.append(", ")
.append(":description")
.append(", ")
.append(":price")
.append(");")
.toString();
PreparedStatement preparedStatement = session.prepare(insertQuery);
return preparedStatement.bind(
productId,
UUID.randomUUID(),
product.getProductName(),
product.getDescription(),
product.getPrice());
}Now, we’ll execute the BatchStatement for the above created BoundStatement using the same Product UUID:
UUID productId = UUID.randomUUID();
BoundStatement productBoundStatement1 = this.getProductVariantInsertStatement(productVariant1, productId);
BoundStatement productBoundStatement2 = this.getProductVariantInsertStatement(productVariant2, productId);
BatchStatement batch = BatchStatement.newInstance(DefaultBatchType.UNLOGGED,
productBoundStatement1, productBoundStatement2);
session.execute(batch);The above code inserts two product variants on the same partition key using the UNLOGGED batch.
4.3. Multiple Partition Batch
Now, let’s see how to insert the same data into two related tables – product_by_id and product_by_name.
First, we’ll create a reusable method to get a BoundStatement instance for the PreparedStatement insert query:
BoundStatement getProductInsertStatement(Product product, UUID productId, String productTableName) {
String cqlQuery1 = new StringBuilder("")
.append("INSERT INTO ")
.append(productTableName)
.append("(product_id, product_name, description, price) ")
.append("VALUES (")
.append(":product_id")
.append(", ")
.append(":product_name")
.append(", ")
.append(":description")
.append(", ")
.append(":price")
.append(");")
.toString();
PreparedStatement preparedStatement = session.prepare(cqlQuery1);
return preparedStatement.bind(
productId,
product.getProductName(),
product.getDescription(),
product.getPrice());
}Now, we’ll execute the BatchStatement using the same Product UUID:
UUID productId = UUID.randomUUID();
BoundStatement productBoundStatement1 = this.getProductInsertStatement(product, productId, PRODUCT_BY_ID_TABLE_NAME);
BoundStatement productBoundStatement2 = this.getProductInsertStatement(product, productId, PRODUCT_BY_NAME_TABLE_NAME);
BatchStatement batch = BatchStatement.newInstance(DefaultBatchType.LOGGED,
productBoundStatement1,productBoundStatement2);
session.execute(batch);This inserts the same product data into the product_by_id and product_by_name tables using LOGGED batch.
5. Conclusion
In this article, we’ve learned about the Cassandra batch query and how to apply it in Cqlsh and Java using BatchStatement.


















