

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about the tree edit distance (TED) and how to calculate it. TED is similar to string edit distance but works on trees.
TED is the minimal number of select operations necessary to transform one tree ( ) to another (
) to another ( ). Usually, those operations are: relabel, delete, and insert a node. However, we can also define edge-based operations such as the removal and creation of an edge between two nodes. In either case, they act only on
). Usually, those operations are: relabel, delete, and insert a node. However, we can also define edge-based operations such as the removal and creation of an edge between two nodes. In either case, they act only on  .
.
We can also associate different costs to those operations. Then, TED will be the cost of the least expensive sequence of actions transforming to , where the sequence’s cost is the sum of the individual actions’ costs.
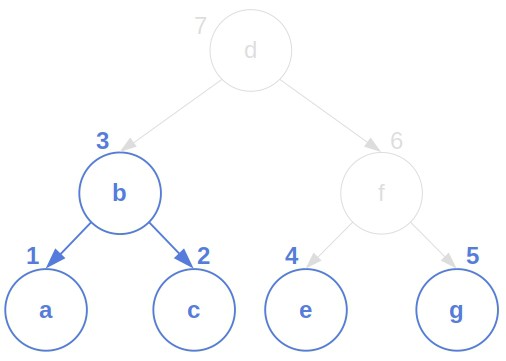
Let’s take a look at these two trees:
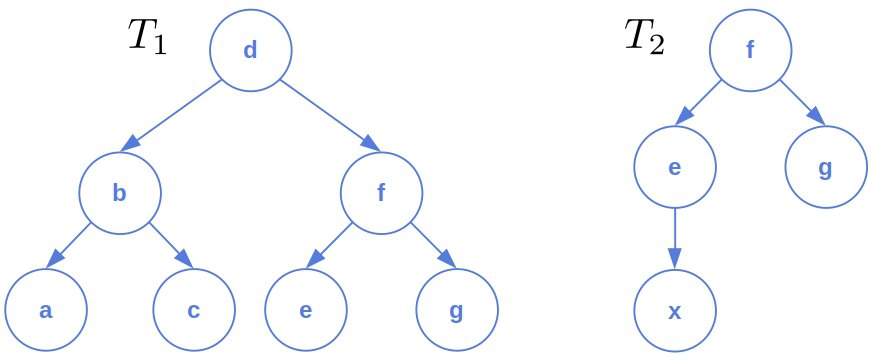
We can define the transformation costs as follows:
The least expensive sequence is:
Its cost is  . So,
. So,  .
.
Since it depends on the transforming operations and their costs, TED can be interpreted only concerning those settings. Using different operations and costs can give different distances. Therefore, we should choose them in a way that makes sense in our application.
Anyhow, if TED fulfills the metric axioms, it induces a metric space of trees. That allows us to analyze them rigorously.
So, let’s now define a general TED and the way to calculate it.
Let  represent the set of operations we can perform on tree
represent the set of operations we can perform on tree  , and let
, and let  be the cost of operation
be the cost of operation  . The costs can be negative, but we’ll focus only on the case where all are positive.
. The costs can be negative, but we’ll focus only on the case where all are positive.
Our general recursive definition of TED is:
(1) 
We can’t say more about its complexity other than it may be exponential, depending on  and
and  .
.
However, if we find an efficient way to hash trees, we may reduce the complexity. The first time we calculate  , we hash and insert the pair
, we hash and insert the pair  into a hash map. That way, if appears again in the recursion, we don’t have to compute it again.
into a hash map. That way, if appears again in the recursion, we don’t have to compute it again.
This particular technique is known as memoization. Some authors consider it to be a tool of dynamic programming.
The recursion (1) covers a general case of TED. Here, we’ll focus on more specific operations and costs. In particular, on the node-based relabel, insert, and delete.
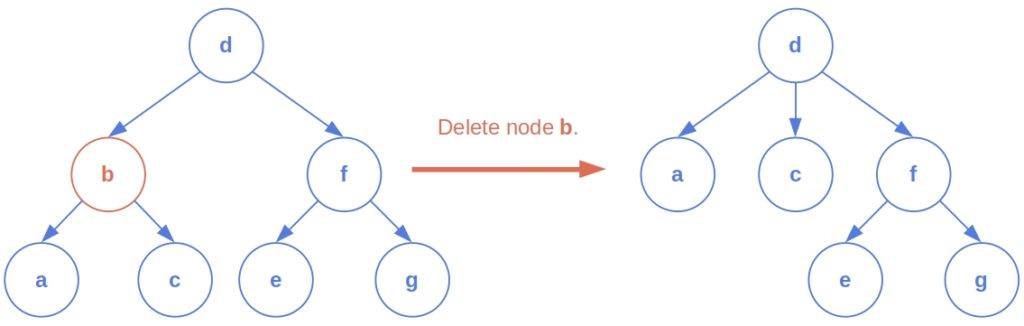
Let’s explain the operations in more detail. While deleting a node, we don’t leave its children hanging in the air. Instead, we add them as the new children of the node’s parent:
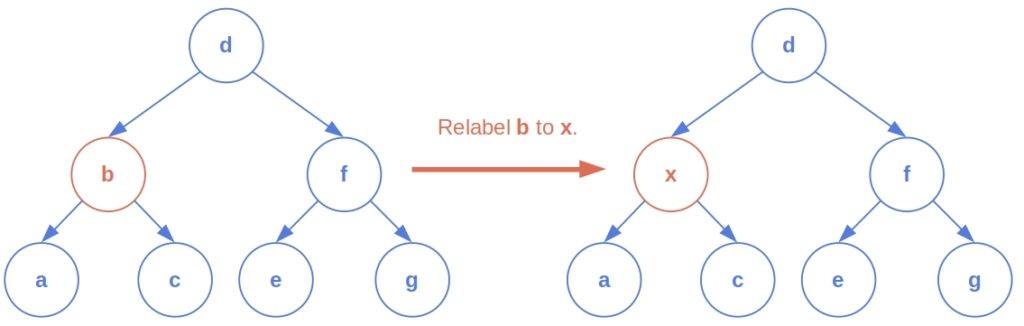
Relabeling a node means changing its label. For example:
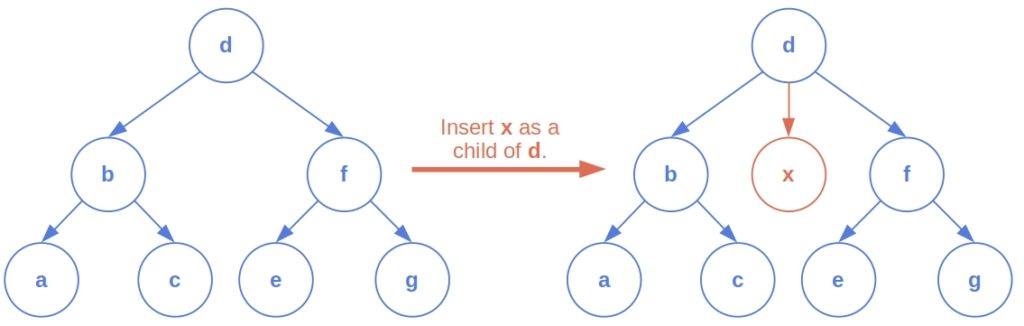
Unlike deletion and relabeling, insertions have more than one argument. We specify the node to insert and the node that will be its parent:
Let’s first state an important assumption: the nodes in and have a left-to-right ordering. So, for any two nodes in a tree, we can say which one is to the left of the other.
Another assumption is that we can insert, delete, or relabel a node at most once during the transformation. For instance, we can’t delete a node after inserting it. Otherwise, the space of possible transformation sequences to consider would become infinite.
The costs of the operations are constant. So,  has the same cost regardless of the node we’re deleting (
has the same cost regardless of the node we’re deleting ( ) and the state of the tree we’re deleting it from (). The same goes for insertion and relabeling. Let
) and the state of the tree we’re deleting it from (). The same goes for insertion and relabeling. Let  be their costs.
be their costs.
Since inserting a node to is the same as deleting it from  , we need not apply insertion to in our implementation. Instead, we can delete the node from and consider it inserted into . Analogously, when relabeling
, we need not apply insertion to in our implementation. Instead, we can delete the node from and consider it inserted into . Analogously, when relabeling  to match
to match  , we don’t need to actually change the label. We can delete both nodes from the trees and consider relabeled to
, we don’t need to actually change the label. We can delete both nodes from the trees and consider relabeled to  . To ease the notation, we’ll denote deletions with a minus sign:
. To ease the notation, we’ll denote deletions with a minus sign:  instead of .
instead of .
Finally, the cost function in our algorithm is restricted to be a distance metric. That makes the TED that it computes a distance metric too. A non-negative constant cost function we opted for fulfills this condition.
In its intermediate steps, the algorithm operates on forests. It does so by considering the post-order numbering of the nodes. Let ![T[i]](/wp-content/ql-cache/quicklatex.com-ccb8ad4cae98ad5136d0bfd02e9d027b_l3.svg "Rendered by QuickLaTeX.com") be the
be the  -th node of in the post-order traversal. Then,
-th node of in the post-order traversal. Then, ![T[i..j]](/wp-content/ql-cache/quicklatex.com-f06c7b314624f83214b04b15abde9cff_l3.svg "Rendered by QuickLaTeX.com") is the forest consisting of the nodes numbered
is the forest consisting of the nodes numbered  in the post-order traversal of . For instance:
in the post-order traversal of . For instance:
Although it may seem that dealing with a more general structure will complicate things, it isn’t so. Instead, it makes the problem easier. By dividing the trees into sub-forests, we can solve the problem using dynamic programming.
Let ![F_1 =T_1[i..j]](/wp-content/ql-cache/quicklatex.com-bdbea899976e81ffca9b9141023acfd7_l3.svg "Rendered by QuickLaTeX.com") be the post-order sub-forest of and let
be the post-order sub-forest of and let  denote its rightmost root. Also, let
denote its rightmost root. Also, let  be the rightmost tree of
be the rightmost tree of  (the one rooted at ). The same notation holds for . Then, we calculate TED as follows:
(the one rooted at ). The same notation holds for . Then, we calculate TED as follows:
(2)
We can calculate the recurrence with the memoization technique. For instance, we can hash each forest (tree) as a pair  , where and
, where and  are the post-order bounds of the nodes in the original tree. So, the first time we calculate the TED of
are the post-order bounds of the nodes in the original tree. So, the first time we calculate the TED of ![\boldsymbol{T_1[i_1..j_1]}](/wp-content/ql-cache/quicklatex.com-eab3e47b6319a68b663b25b82864c593_l3.svg "Rendered by QuickLaTeX.com") and
and ![\boldsymbol{T_2[i_2, j_2]}](/wp-content/ql-cache/quicklatex.com-aba027e114cde083c09ff73cd40f6f70_l3.svg "Rendered by QuickLaTeX.com") , we use
, we use  as the key and insert the corresponding value into a map. Later, we reuse the stored result to avoid repeated calculation.
as the key and insert the corresponding value into a map. Later, we reuse the stored result to avoid repeated calculation.
The forest and tree structures should be supplied with efficient methods for evaluating  , and
, and  (
( ).
).
First, let’s observe that the root of the rightmost tree of the forest ![\boldsymbol{F_1=T_1[i_1..j_1]}](/wp-content/ql-cache/quicklatex.com-0ca1855961e019b6dbe94eb83735d7ab_l3.svg "Rendered by QuickLaTeX.com") is the node number
is the node number  , so
, so  for
for ![F_1=T_1[i_1..j_1]](/wp-content/ql-cache/quicklatex.com-df6ebadf72e733efc8c97f236844c737_l3.svg "Rendered by QuickLaTeX.com") . From there,
. From there,  amounts to
amounts to ![T_1[i_1..(j_1-1)]](/wp-content/ql-cache/quicklatex.com-e47201a3f71d85e3a6bf64ce7ba4874f_l3.svg "Rendered by QuickLaTeX.com") . The difference of and is the forest consisting of all the nodes that are in but not . The same goes for the other tree
. The difference of and is the forest consisting of all the nodes that are in but not . The same goes for the other tree ![F_2=T_2[i_2..j_2]](/wp-content/ql-cache/quicklatex.com-823bdc692287c5f37170476912336dbf_l3.svg "Rendered by QuickLaTeX.com") ..
..
Finding  (
( ), however, requires a more careful consideration. The right boundary of is the post-order index of its root, that is,
), however, requires a more careful consideration. The right boundary of is the post-order index of its root, that is,  . We can compute the left boundary on the fly by running a post-order traversal routine, but this approach will slow down the algorithm. Instead, it’s more efficient to preprocess the tree and compute each sub-tree’s post-order left boundary so that it’s available in
. We can compute the left boundary on the fly by running a post-order traversal routine, but this approach will slow down the algorithm. Instead, it’s more efficient to preprocess the tree and compute each sub-tree’s post-order left boundary so that it’s available in  time during the computation of TED. We can do it in linear time using a post-order traversal algorithm.
time during the computation of TED. We can do it in linear time using a post-order traversal algorithm.
So, we’ll assume that  , the left post-order boundary of the tree whose root is
, the left post-order boundary of the tree whose root is  , is available for the nodes in both trees. Then, is
, is available for the nodes in both trees. Then, is ![T_k[\ell(r_k).. r_k]](/wp-content/ql-cache/quicklatex.com-1a5abe3ffac1f09922d68bd53274fa3a_l3.svg "Rendered by QuickLaTeX.com") , and
, and  is
is ![T_k\left[\ell(r_k)..r_k-1\right]](/wp-content/ql-cache/quicklatex.com-8a9e88d42422ac40521b0253d363c65a_l3.svg "Rendered by QuickLaTeX.com") . If
. If  (the forest doesn’t contain only one tree), then
(the forest doesn’t contain only one tree), then  is
is  . Otherwise,
. Otherwise, ![F_k-R_k = \emptyset \equiv T_k[0, 0]](/wp-content/ql-cache/quicklatex.com-367ff8198fac856bc3b0ffec17e1ec48_l3.svg "Rendered by QuickLaTeX.com") .
.
Here’s how we can calculate  with a memoization algorithm:
with a memoization algorithm:
algorithm TEDMemoized(T1, T2, n, m):
// INPUT
// T1 = the tree to transform
// T2 = the tree to transform T1 into
// n = the number of nodes in T1
// m = the number of nodes in T2
// T1 and T2 have been preprocessed to determine the left boundaries ℓ(·) for all the nodes
// results = the storage for the results, initially empty
// OUTPUT
// The tree edit distance between T1 and T2
// Initially called as TED(T1[1 : n], T2[1 : m])
// Apply the memoization technique
if results[T1, T2] is known:
return results[T1, T2]
// Cover the base cases
if T1 = empty set and T2 = empty set:
return 0
if T1 != empty set and T2 = empty set:
r1 <- find the rightmost root of T1
return cost_del + TED(T1 - r1, empty set)
if T1 = empty set and T2 != empty set:
r2 <- find the rightmost root of T2
return cost_ins + TED(empty set, T2 - r2)
// Cover the recursive case (both T1, T2 != empty set)
Determine r1, R1, r2, R2
ted_del <- TED(T1 - r1, T2) + cost_del
ted_ins <- TED(T1, T2 - r2) + cost_ins
ted_rel <- TED(T1 - R1, T2 - R2) + cost_rel + TED(R1 - r1, R2 - r2)
// Store and return the result
results[T1, T2] <- min{ted_del, ted_ins, ted_rel}
return results[T1, T2]This algorithm is a memoized version of Zhang and Shasha‘s iterative TED algorithm. So, its complexity is the same.
We’ll derive it by considering the relevant (sub)forests of and .
A forest is relevant if it appears in the recursive calculation of  . Zhang and Shasha define a keyroot as a tree’s root or a node with a left sibling. We can prove that the post-order numbering of a relevant forest is a prefix of the post-order traversal of a keyroot’s tree.
. Zhang and Shasha define a keyroot as a tree’s root or a node with a left sibling. We can prove that the post-order numbering of a relevant forest is a prefix of the post-order traversal of a keyroot’s tree.
Let the keyroot depth  of
of  () be the highest number of keyroot nodes on the path from the root to any other node in the tree. Then, Zhang and Shasha’s algorithm’s complexity (and consequently of ours too) is
() be the highest number of keyroot nodes on the path from the root to any other node in the tree. Then, Zhang and Shasha’s algorithm’s complexity (and consequently of ours too) is  .
.
We can improve the result even further. Let  and
and  denote the height and the number of leaves in , and let
denote the height and the number of leaves in , and let  and
and  do the same for . Zhang and Shasha prove that
do the same for . Zhang and Shasha prove that  and that
and that  . So, the overall complexity is:
. So, the overall complexity is:
![\[O\left( \min\{n_{\mathrm{height}}, n_{\mathrm{leaves}}\} \min\{m_{\mathrm{height}}, m_{\mathrm{leaves}}\} n m \right)\]](/wp-content/ql-cache/quicklatex.com-9fcc3eae091dd5d897837d363d765d08_l3.svg "Rendered by QuickLaTeX.com")
If the trees are balanced, then  and
and  , so the overall complexity becomes:
, so the overall complexity becomes:
![\[O \left( (n \log n) (m \log m) \right)\]](/wp-content/ql-cache/quicklatex.com-55bbe9c54edcab44beef9d034bff3d2a_l3.svg "Rendered by QuickLaTeX.com")
or  if
if  . However, if the trees are degenerate and represent linked lists, the complexity is
. However, if the trees are degenerate and represent linked lists, the complexity is  . Therefore, the worst-case complexity stays the same as in the version without the keyroots. In practice, we expect the improved algorithm to perform faster.
. Therefore, the worst-case complexity stays the same as in the version without the keyroots. In practice, we expect the improved algorithm to perform faster.
We can trace the minimal sequence of operations that transform into the same way we trace the paths in the search algorithms.
When we determine the minimum of  ,
,  , and
, and  , we remember which operation leads to that results. When we compute the complete TED, we can follow the operations in the reversed order.
, we remember which operation leads to that results. When we compute the complete TED, we can follow the operations in the reversed order.
In this article, we talked about tree edit distance. We showed how to define and how to calculate it in polynomial time.
![\[cost(relabel) = 2 \quad cost(delete) = cost(insert) = 3\]](/wp-content/ql-cache/quicklatex.com-8500c5ed53273972d51ccd42b38d9fb2_l3.svg "Rendered by QuickLaTeX.com")
![\[\begin{aligned} \text{delete } & c, e, g \\ \text{relabel } & f \rightarrow g, d \rightarrow f, b \rightarrow e, a \rightarrow x \\ \end{aligned}\]](/wp-content/ql-cache/quicklatex.com-1f181bdce79cbc2b4c241fc54509e4cf_l3.svg "Rendered by QuickLaTeX.com")
