

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
An important concept in linear algebra is the Single Value Decomposition (SVD). With this technique, we can decompose a matrix into three other matrices that are easy to manipulate and have special properties.
In this tutorial, we’ll explain how to compute the SVD and why this method is so important in many fields, such as data analysis and machine learning. We’ll also see real-world examples of how SVD can be used to compress images and reduce the dimensionality of a dataset.
Let’s suppose we have a matrix  with dimensions
with dimensions  , and we want to compute its SVD. We want to obtain the following representation:
, and we want to compute its SVD. We want to obtain the following representation:

in which:

Sometimes we might also say that the columns of  are the left-singular vectors of and the columns of
are the left-singular vectors of and the columns of  are the right-singular vectors of .
are the right-singular vectors of .
Now, let’s compute the SVD of a random matrix :

First, we need to find the eigenvalues of 

Now we compute the characteristic equation for this matrix:

Then we can represent as  and our singular values are
and our singular values are  and
and  . Then we define the first matrix:
. Then we define the first matrix:

We can now compute the orthonormal set of eigenvectors of for each eigenvalue. They are orthogonal by definition since is symmetric. For  we have:
we have:

We need to reduce this matrix to echelon form. We do that in two steps. First, we divide the first row by -2.88:

In the second step, we subtract the first row multiplied by 3.84 from the second row, and we finally have:

After that, we compute a unit-length vector  such that
such that  in the kernel of that matrix, and we find:
in the kernel of that matrix, and we find:

Similarly, to  we obtain:
we obtain:

So the matrix V is represented as:

To compute the matrix , we use that each column is given by:

And the whole matrix is given by:

The final SVD decomposition is given by:

Now that we know how to compute the SVD, let’s discuss its main two interpretations.
Since this is a fundamental concept in linear algebra, we’ll start with the orthogonality analysis. The columns of matrices and represent the set of orthogonal vectors that remains orthogonal after applying the transformation of matrix :


We can easily verify the orthogonality before and after the transformation by plotting the vectors:
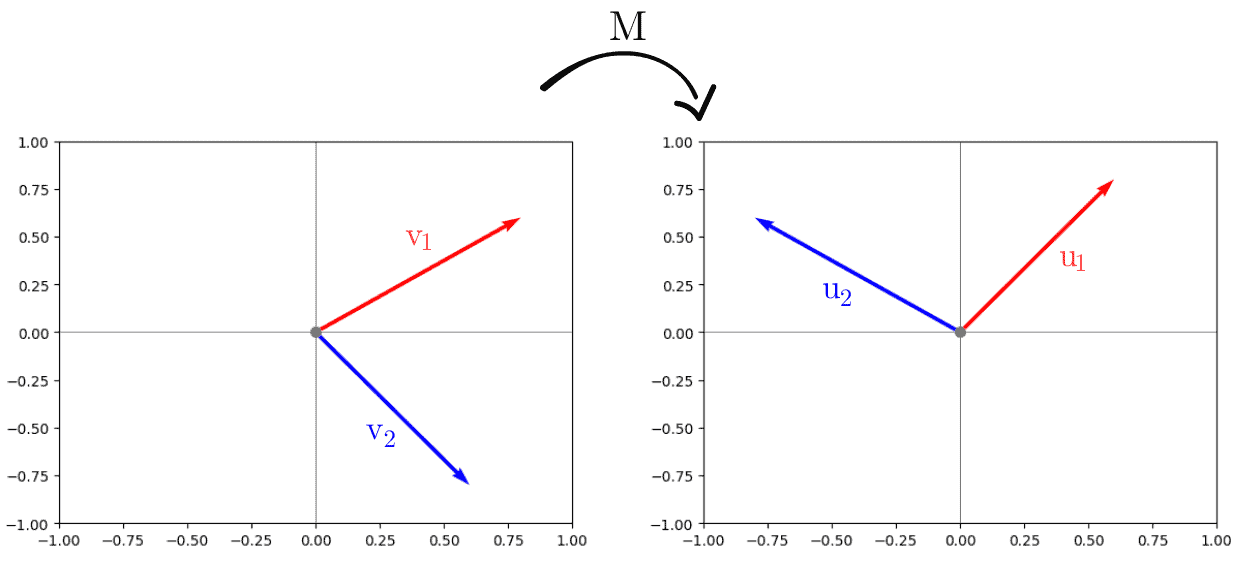
The second interpretation of the SVD is on an optimization problem. If we need to find out in which direction a matrix stretches a unit vector the most, we solve:

For the sake of simplicity, we won’t demonstrate here, but the solution for this problem is given by the first column of matrix ( ).
).
Now let’s see how SVD works on real-world applications.
We’ll discuss two different applications. First, we’ll show how SVD can compress an image then we’ll see how SVD can be used to analyze a high-dimensional dataset.
Considering that we proposed the model for the SVD, now let’s introduce the k-rank SVD model.
In this model, we’ll only consider the first  columns of , the most significant singular values of
columns of , the most significant singular values of  , and the first rows of
, and the first rows of  . To see this in practice, let’s consider a grayscale image of the Sagrada Familia Basilica in Barcelona for different low-rank approximations:
. To see this in practice, let’s consider a grayscale image of the Sagrada Familia Basilica in Barcelona for different low-rank approximations:

For a quantitative metric of compression, let’s consider the formula:

It is clear that for  , we can barely see the church, but the compression rate is incredibly high, equal to 158. As we increase the rank to 15, our image becomes clearer. For that case, we have a compression rate of 31.79. Once we reach the highest rank in our experiments, the church is well represented, and our compression rate is equal to 4.76.
, we can barely see the church, but the compression rate is incredibly high, equal to 158. As we increase the rank to 15, our image becomes clearer. For that case, we have a compression rate of 31.79. Once we reach the highest rank in our experiments, the church is well represented, and our compression rate is equal to 4.76.
This illustrates the potential of the SVD in the image compression field, especially if we need to uncover essential features in an image.
As a final example, let’s discuss a second application of SVD called Principal Component Analysis (PCA).
A PCA aims to find linear combinations of the original coordinates of a matrix in the form:

for  . We’ll only highlight here that the components have to be orthogonal, which is the case of an SVD decomposition. For a more detailed description of PCA, we’ll refer to a previous article.
. We’ll only highlight here that the components have to be orthogonal, which is the case of an SVD decomposition. For a more detailed description of PCA, we’ll refer to a previous article.
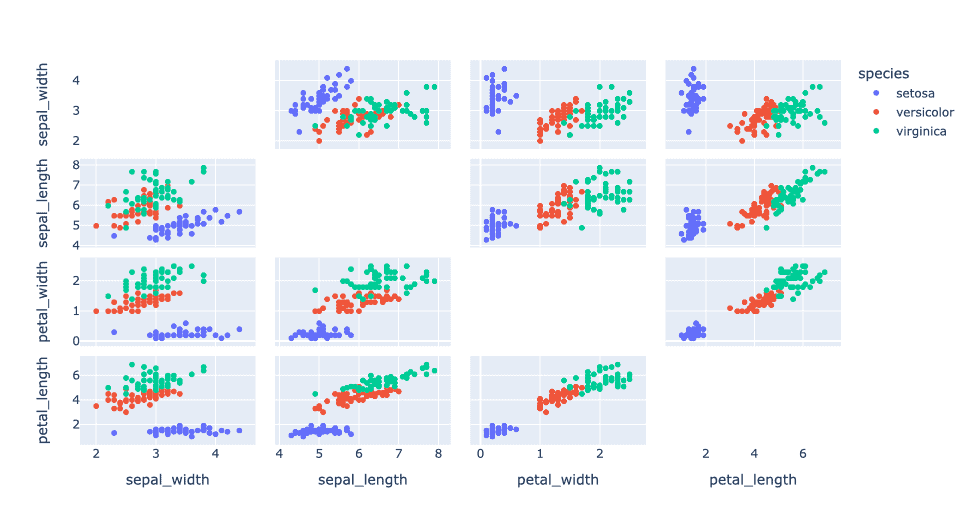
Here, we’ll see how the PCA can reduce dimensionality. We’ll use the traditional Iris dataset with four features:  ,
,  ,
,  , and
, and  .
.
The complexity of the data is evidenced if we plot all the features in 2D for the three species of plants:
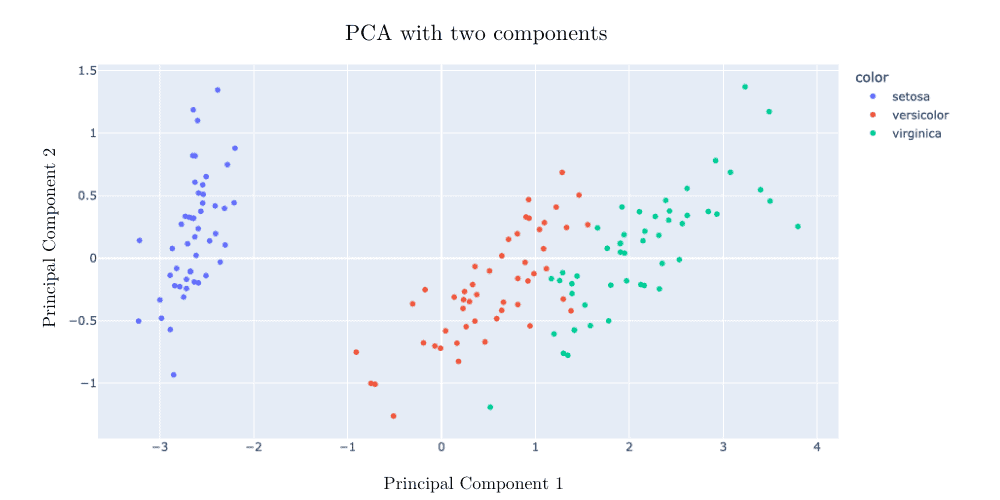
 But once we perform a PCA with two components, the plants are successfully segmented:
But once we perform a PCA with two components, the plants are successfully segmented:
In this article, we discussed the relevance and how to compute an SVD of a matrix. Many applications rely on the implementation of this method.
From insights and dimensionality reduction to linear algebra proofs, SVD plays a crucial role. We should keep in mind that after performing an SVD, we’ll end up with matrices that are easier to manipulate and have a strong interpretation, as we saw in this article.