

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Text similarity is one of the active research and application topics in Natural Language Processing. In this tutorial, we’ll show the definition and types of text similarity and then discuss the text semantic similarity definition, methods, and applications.
In Natural Language Processing (NLP), the answer to “how two words/phrases/documents are similar to each other?” is a crucial topic for research and applications. Text similarity is to calculate how two words/phrases/documents are close to each other. That closeness may be lexical or in meaning.
Semantic similarity is about the meaning closeness, and lexical similarity is about the closeness of the word set.
Let’s check the following two phrases as an example:
According to the lexical similarity, those two phrases are very close and almost identical because they have the same word set. For semantic similarity, they are completely different because they have different meanings despite the similarity of the word set.
Calculating text similarity depends on converting text to a vector of features, and then the algorithm selects a proper features representation, like TF-IDF. Finally, the similarity work s on the representation vectors of texts.
There are a lot of techniques to calculate text similarity, whether they take semantic relations into account or no. On top of these techniques:
We’ll start with an example using Google search. Let’s have a look at the following two phrases:
As per the below image, if you used the first phrase on Google search, you will get the second phrase in the top 5 results. For lexical similarity, these two statements are not close to each other, but for semantic similarity, they are very close because they have strongly close meaning despite the difference in word set:
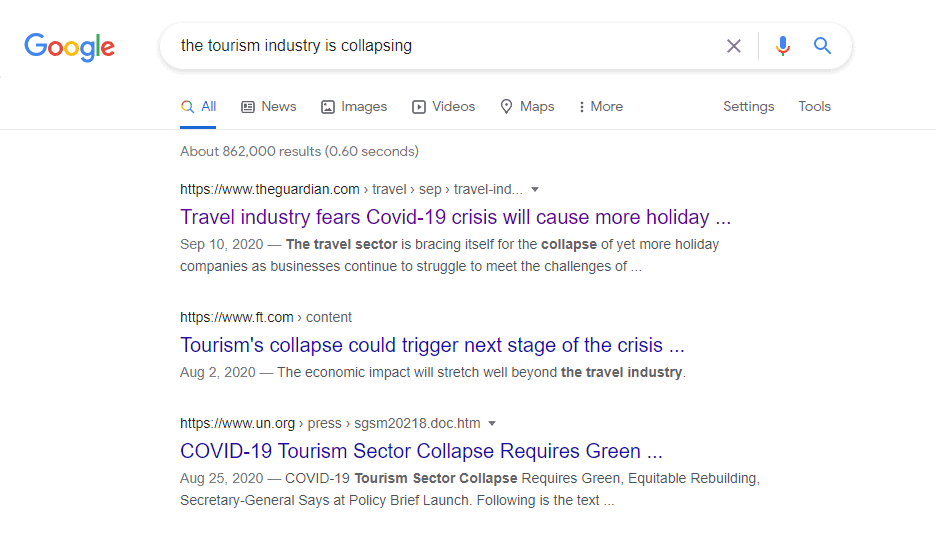
The result (the second phrase) will change with time because events affect the search results. But the sure thing, that the result will have a different word set but very close meaning.
Semantic similarity between two pieces of text measures how their meanings are close. This measure usually is a score between 0 and 1. 0 means not close at all, and 1 means they almost have identical meaning.
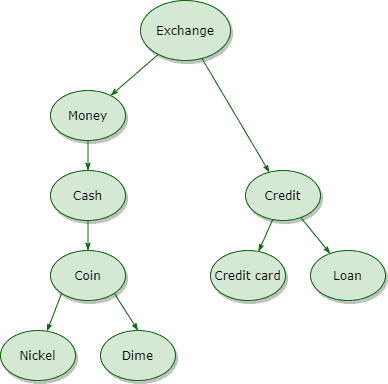
We use this type to determine the semantic similarity between concepts. This type represents each concept by a node in an ontology graph. This method is also called the topological method because the graph is used as a representation for the corpus concepts.
A minimum number of edges between two concepts (nodes) means they are more close in meaning and more semantically close.
The following graph shows an example of how concepts form a topology, and this graph will result in “coin” is more close to “money” more than “credit card”:
This type calculates the semantic similarity based on learning features’ vectors from the corpus.
Vectors representation can depend on many techniques, like count or TF-IDF in Latent Semantic Analysis (LSA), weights of Wikipedia concepts in Explicit Semantic Analysis (ESA), synonyms in Pointwise Mutual Information (PMI), and co-occurring words of a set of predefined words in Hyperspace Analogue to Langauge (HAL).
In this type, most of the previous techniques can be combined with word embeddings for better results because word embeddings capture the semantic relation between words.
Measuring semantic similarity doesn’t depend on this type separately but combines it with other types for measuring the distance between non-zero vectors of features.
The most important algorithms in this type are Manhattan Distance, Euclidean Distance, Cosine Similarity, Jaccard Index, and Sorensen-Dice Index.
Euclidean Distance is calculated as follows:
![\[d(x, y) = \sqrt{\sum_{i=1}^{n} (y_{i} - x_{i})^{^{2}} }\]](/wp-content/ql-cache/quicklatex.com-00e411bfcf4dd351dbdb9c23bb98fa16_l3.svg "Rendered by QuickLaTeX.com")
where  is the size of features vector.
is the size of features vector.
Cosine Similarity as follows:
![\[Similarity(A, B) = \frac{A . B}{\left \| A \right \| \times \left \| B \right \|} = \frac{\sum_{i=1}^{n}A_{i} B_{i}}{\sqrt{\sum_{i=1}^{n}A_{i}^{2}}\sqrt{\sum_{i=1}^{n}B_{i}^{2}}}\]](/wp-content/ql-cache/quicklatex.com-8ff4a47114e3d9845051b7d380b8bbe2_l3.svg "Rendered by QuickLaTeX.com")
where is the size of features vector.
The scientific community introduced this type in 2016 as a novel type of semantic similarity measurement between two English phrases, with the assumption that they are syntactically correct.
This type has five main steps:
All the algorithms we mentioned in this article are already implemented and optimized in different programming languages, mainly Python and Java.
Sematch is one of the most recent tools in Python for measuring semantic similarity. It depends on the knowledge-based similarity type. The following code snippet shows how simply you can measure the semantic similarity between two basic words in English with an output of 0.5:
from sematch.semantic.similarity import WordNetSimilarity
wns = WordNetSimilarity()
wns.word_similarity('dog', 'cat', 'li')
Text semantic similarity is an active research area within the natural language processing and linguistics fields. Also, it gets involved in many applications for natural language processing and informatics sciences.
For natural language processing (NLP), we use the semantic similarity in many applications, like sentiment analysis, natural language understanding, machine translation, question answering, chatbots, search engines, and information retrieval
For informatics sciences, we have applications in the biomedical field and geo-informatics. Biomedical informatics builds the biomedical ontologies (Genes Ontology) mainly using semantic similarity methods. Geo-Informatics, geographical feature type ontologies depend on topological and statistical types of semantic similarity. One of the most known tools for this type of application is The OSM Semantic Network used to compute the semantic similarity of tags in OpenStreetMap.
In this article, we showed the text-similarity in a nutshell. Then we showed the semantic similarity definition, types and techniques, and applications. Also, we showed the usage of one of the most recent Python libraries for semantic similarity.