

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll introduce the definition and known techniques for topic modeling. Then, we’ll show an overview of word embeddings and the Word2Vec algorithm. And finally, we’ll learn how we can extend Word2Vec for topic modeling.
2. Topic Modeling
Topic modeling is an unsupervised machine learning technique that aims to scan a set of documents and extract and group the relevant words and phrases. These groups are named clusters, and each cluster represents a topic of the underlying topics that construct the whole data set. Topic modeling is a Natural Language Processing (NLP) problem.
An example of topic modeling is automatically tagging customer support tickets based on ticket content. So, each set of tickets could be assigned to the correct team.
There are two well-known techniques for topic modeling:
- Latent Semantic Analysis (LSA)
- This approach assumes that two words are similar if they appear in the same context
- Similar documents will contain approximately the same distribution of words’ frequencies. This approach uses TF-IDF scores to calculate words’ frequencies
- Latent Dirichlet Allocation (LDA)
- This approach assumes that similar topics almost consist of similar words, and documents cover different and several topics
- LDA assumes that the distribution of topics over documents, and distribution of words over topics, are Dirichlet distributions
As mentioned before, topic modeling is an unsupervised machine learning technique for text analysis. The supervised version of topic modeling is topic classification. In topic classification, we need a labeled data set in order to train a model able to classify the topics of new documents.
The most well-known Python library for topic modeling is Gensim.
3. Word2Vec
Before talking about Word2Vec, we’ll show the definition of word embeddings.
3.1. Word Embeddings
Word embeddings are simply vectors representation for document vocabulary. Each word has a representation vector, its length is the size of the set of unique words in the document. The algorithm uses these vectors to detect word context, semantic similarity, syntactic similarity, or relation with another word.
Context similarity between words is measured based on the similarity between their corresponding vectors. The similarity between vectors is measured by the angle between them, which is called, cosine similarity.
There are two types of word embeddings:
- Frequency-based embeddings. This type uses deterministic methods to construct the words’ vectors, which means statistical measurements construct the vectors’ elements, like counting and TF-IDF scores of words
- Prediction-based embeddings. This type uses neural networks to learn the words’ vectors, which means probabilities construct the vectors’ elements. Word2Vec belongs to this type of word embeddings
3.2. Word2Vec
The capabilities of deterministic or statistical methods to build word vectors are limited, especially with a high volume of data. So in 2013, a group of Google researchers introduced Word2Vec as the state of the art of prediction-based word embedding. Word2Vec is a probabilistic method to learn word embedding (word vectors) from textual data corpus. Conceptually, it’s a two-layer neural network that analyzes the corpus and produces a set of vectors that represents the words.
Word2Vec detects the contextual similarity of words mathematically through its neural network. Words with similar context, their vectors will lie within close proximity, which is measured by cosine similarity. So it can detect the relation between words, like “man” to “boy”, and “woman” to “girl”. In the initial training of Word2Vec on Wikipedia corpus, it learns to link “man” to “king”. So when you ask for the similarity of “woman”, it produces “queen” because “man” and “woman” are contextually similar words. This is called the “+king-man+woman” problem.
Word2Vec has two models:
- Continuous Bag of Words (CBOW)
- CBOW model predicts the probability of a word given the context (single word or group of words)
- Faster and has better performance with large data sets
- Skip-gram
- This model predicts the context given the target word
- Works well with small data sets, and better representation for rare words
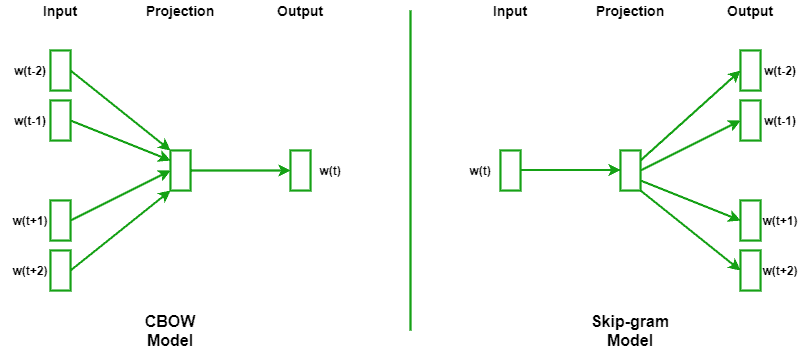
The following diagram shows the abstract neural network representation of CBOW and Skip-gram models:
4. Topic Modeling with Word2Vec
Word2Vec algorithms aim to give equal weights to all words in the corpus. However, from a contextual perspective, some words are more important than others. That is the main challenge with using only Word2Vec for topic modeling.
Another two challenges with Word2Vec:
- It doesn’t have a good technique to deal with ambiguity. Two exact words but in two different contexts will have too close vectors.
- It can’t deal well with new vocabulary that comes out of the training set, which is called out-of-vocabulary (OOV)
One of the basic ideas to achieve topic modeling with Word2Vec is to use the output vectors of Word2Vec as an input to any clustering algorithm. This will result in a group of clusters, and each represents a topic. This approach will produce similar but less accurate LDA results.
4.1. LDA2Vec
LDA considers each document as a bag-of-words, and all vectors have the same length, which is equivalent to the size of the vocabulary of all documents. The problem with the BOW model is that it ignores any structure or semantic relationship between the words. Here comes the benefits of word embeddings, which will capture the semantic and syntactic relationship between words and will produce variant length vectors as documents’ representation.
LDA2Vec is a model that uses Word2Vec along with LDA to discover the topics behind a set of documents. In 2016, Chris Moody introduced LDA2Vec as an expansion model for Word2Vec to solve the topic modeling problem. LDA2Vec has the following characteristics:
- It uses Word2Vec to build vectors for words, documents, and topics
- It depends on a modified skip-gram approach. Instead of using a word to predict the context, it uses a word and a document combined to predict the context vector
- It produces a set of sparse documents weights vectors like LDA (not dense vectors like Word2Vec), plus the topics vectors, as a result
Current implementations for LDA2Vec:
5. Conclusion
In this tutorial, we’ve shown the definitions and techniques of topic models, word embeddings, and WordVec. Then we’ve shown how LDA2Vec expands LDA and Word2Vec for better topic modeling.