

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: February 28, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll introduce the Random Forest algorithm, examine the phenomena of overfitting and underfitting, and explore how Random Forest mitigates these challenges.
Decision trees (DTs) represent a non-parametric supervised learning approach utilized for both classification and regression tasks. Their objective is to construct a predictive model that estimates the value of a target variable through the acquisition of basic decision rules derived from the features within the data:
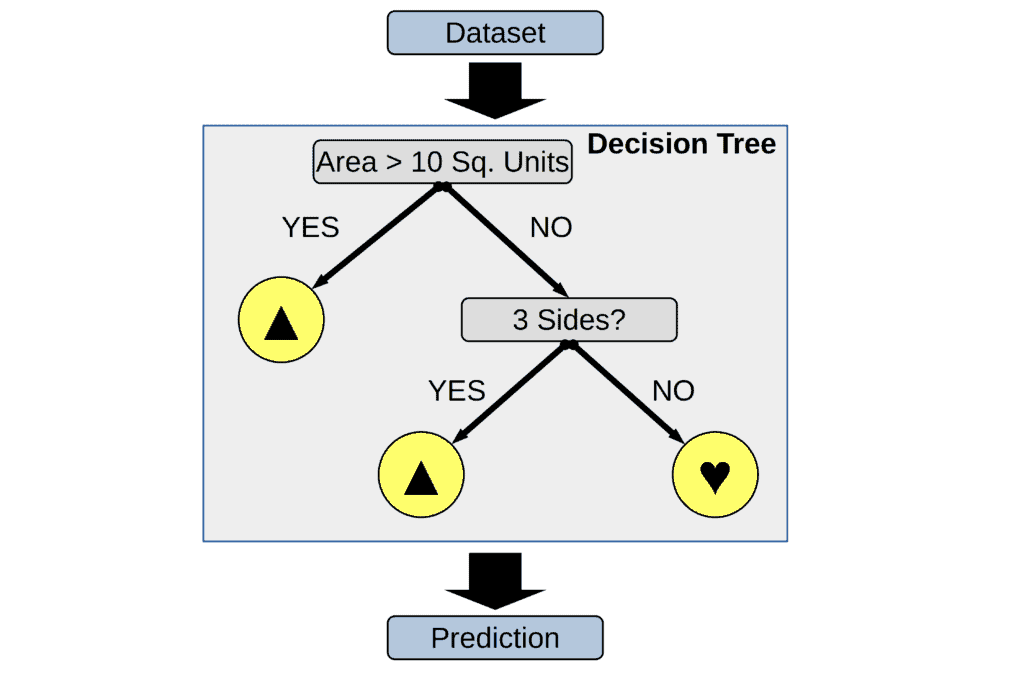
A decision tree functions as a hierarchical decision-making model, portraying decisions and their probable outcomes in a tree-like structure. This encompasses potential chance event results, associated resource expenses, and utility considerations. It serves as a method to visualize an algorithm primarily composed of conditional control statements.
Random Forest is a supervised learning algorithm that employs an ensemble technique comprising numerous decision trees, with the combined output representing the consensus of the most optimal solution to the problem.
Ensemble learning strategies amalgamate multiple machine learning (ML) algorithms to yield an enhanced model, leveraging the collective insight of diverse algorithms—a concept akin to harnessing the collective wisdom of a group for data analysis. The fundamental principle behind ensemble learning is that a group of individuals with varied expertise on a particular problem domain can collectively arrive at a superior solution to an individual with extensive knowledge.
In essence, a random forest constitutes an amalgamation of decision trees, a familiar problem-solving concept. Decision trees ascertain an outcome by posing a sequence of true/false inquiries about elements within a dataset:
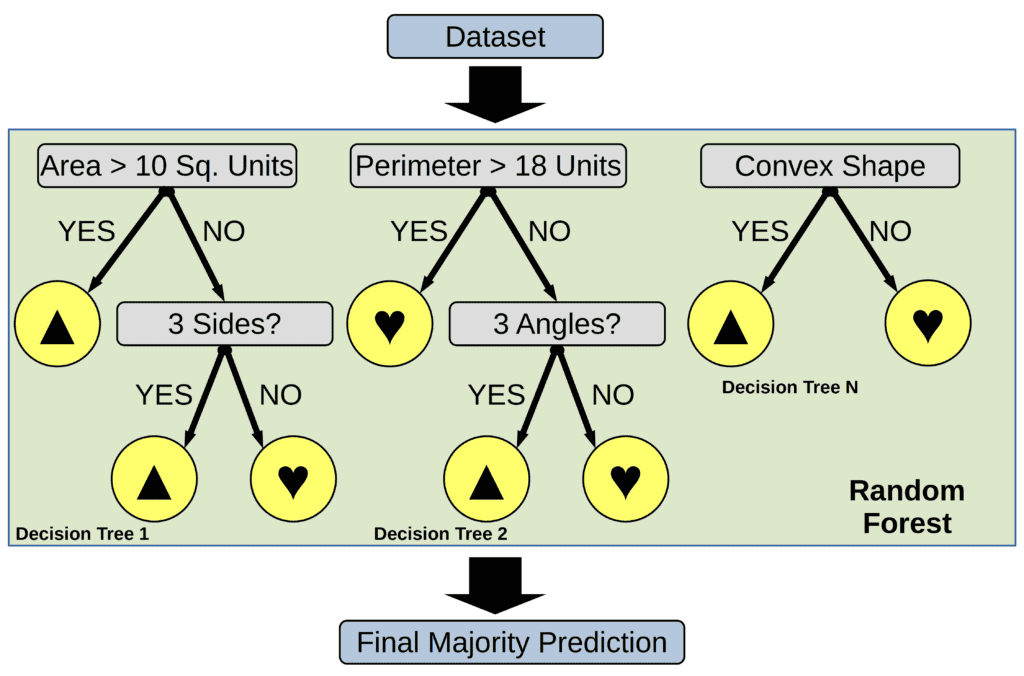
In the above example, when deciding whether a shape is a triangle or a heart, a decision tree could consider factors such as area, perimeter, number of sides and angles, and whether the shape is convex or concave. Within the algorithmic framework, the system persistently seeks the factor that enables partitioning the dataset to maximize distinctions between groups while ensuring that individuals within each group exhibit comparable attributes.
Random forest employs a method known as “bagging” to simultaneously construct full decision trees from random bootstrap samples of both the dataset and its features. In contrast to decision trees, which rely on a predetermined set of features and frequently suffer from overfitting, randomness plays a crucial role in the success of the forest.
By incorporating randomness, each tree in the forest exhibits low correlations with others, mitigating the risk of bias. Moreover, the presence of numerous trees helps alleviate overfitting, a situation where the model captures excessive “noise” from the training data, leading to suboptimal decisions.
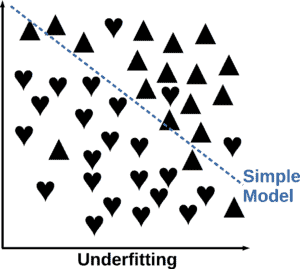
Underfitting occurs when a model’s complexity is insufficient for the dataset, resulting in a hypothesis that is overly simplistic and inaccurate. Underfitting, also known as high bias, signifies that although the algorithm may generate precise predictions, its initial assumptions regarding the data are not correct:
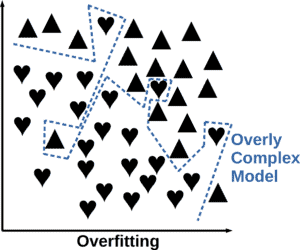
Conversely, overfitting arises when a model is overly complex relative to the dataset, leading to a hypothesis that is excessively intricate and inaccurate. For instance, when the data exhibits linearity, but the model employs a high-degree polynomial. Overfitting, or high variance, indicates that the algorithm struggles to make accurate predictions, as minor variations in the input data yield significant changes in the model output:
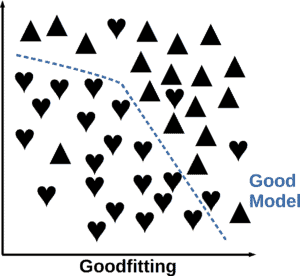
When a model’s complexity is well-balanced with the dataset, the resulting model is neither overly simplistic nor overly complex. Such a model avoids both underfitting and overfitting and is called a goodfitting model:
We can employ several fundamental approaches within the Random Forest framework to reduce overfitting conditions.
One effective strategy involves simplifying the model architecture by using less complex decision trees within the ensemble. We can reduce overfitting by restricting the depth or complexity of individual trees and limiting the number of features considered at each split.
Techniques such as controlling the maximum tree depth or implementing feature selection methods can help prevent the model from memorizing noise in the training data.
We can control the complexity of the Random Forest model by adjusting hyperparameters. An example of a hyperparameter would be the minimum samples required to split a node or apply penalties on large trees. Regularization methods play a crucial role in preventing overfitting. These methods impose constraints on the model’s parameters during training.
Dropout or early stopping techniques can also be effective in regularizing the model by preventing it from becoming too specialized to the training data.
We can reduce the size of the feature vector by employing techniques using dimensionality reduction algorithms like principal component analysis (PCA). Reducing the dimensionality of the feature space can help alleviate overfitting in random forests.
Feature hashing or embedding methods can further aid in representing features in a lower-dimensional space, thereby reducing the risk of overfitting caused by high-dimensional data.
Acquiring more diverse training data is another effective strategy for mitigating overfitting in random forest models. The data cleaning process aims to remove noise and irrelevant information from the dataset. Hold-out validation or cross-validation can help assess the model’s performance on unseen data. Augmenting the dataset by generating synthetic data points or leveraging data augmentation techniques can help diversify the training set, leading to improved model generalization performance.
In this article, we learned how Random Forests effectively address overfitting by employing strategies such as simplification, regularization, feature reduction, and data augmentation, ensuring the development of robust and accurate predictive models.