Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Biases in Machine Learning
Last updated: May 2, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll go through the different types of biases we observe in machine learning. This will help us understand what we mean by biases, and why it’s essential to avoid them.
We’ll also learn how biases make their way into machine learning applications, and more importantly, how we can identify, avoid, and correct them.
2. Applications of Machine Learning
This tutorial assumes a certain level of familiarity with machine learning algorithms and the basic construction process for applications using them. However, in the context of biases, it’s important to understand the practical applications of machine learning. This will allow us to grasp the impact of biases in such applications.
Machine learning is a branch of a broader field known as artificial intelligence. Artificial intelligence is the area of study concerned with building smart machines capable of performing tasks that typically require human intelligence. Machine learning, in particular, is the study of algorithms that improve automatically through experience and the use of data:
Machine learning itself is an extensive area of study. We can categorize it into supervised, unsupervised, semi-supervised, reinforcement, and various other types of learning algorithms. Within this categorization also lies the popular neural networks and deep learning fields. However, it’s beyond the scope of this tutorial to cover this in detail.
Interestingly, artificial intelligence and machine learning have been in practice for quite a long time. However, it’s only in the last few decades that it’s moved out of academic research and found its way into practical applications. This can largely be attributed to the general availability of cloud computing, and a massive amount of data being generated during this period.
The field of machine learning has matured enough to find interesting and important applications in a wide range of industries now. We’re entrusting these algorithms to take more decisions for us. For instance, we’re using machine learning to identify people at public places, select candidates for recruitment, decide on loan applications, etc.
3. What Is Bias and Why Should We Care?
Before we proceed further, it’s essential to understand what we mean by bias. The formal definition of bias is an inclination or prejudice for or against one person or group. In the context of machine learning, bias occurs when the algorithm produces systemically prejudiced results. This can often lead to situations that are unfair for multiple reasons.
But why does this happen in machine learning algorithms at all? As we saw earlier, machine learning algorithms depend primarily on the quality, objectivity, and size of training data to learn from. So if there’s an inherent bias in the input data, it’s likely to show in the algorithm’s output decisions.
This isn’t the only source of bias in a machine learning application though. A careful observation of the process of building such an application can reveal several other sources that we’ll examine in the next section. What we need to understand is why we should care about such biases. There are several powerful examples to explain this:

It isn’t difficult to see that when we deploy biased algorithms to solve real-world problems for us, it can have unintended consequences. For example, a facial recognition system can start to be racially discriminatory, or a credit application evaluation system can become gender-biased. There can be severe implications for these biased applications.
A bias can also render an application useless if used in a different context. For instance, if we develop a voice assistant, but only train it with the voices of people from a particular region, we can’t expect it to perform very well if we use it in a different region due to changes in voice tone, dialect, culture, etc.
It’s worth noting that a bias doesn’t necessarily have to be as severe as these examples.
4. Types of Biases in Machine Learning
We briefly touched upon how bias can creep into our machine learning applications. In the process of building our application, we have to collect the data, process it, and then feed it into a machine learning model so the model can learn from the data. Inadvertently, we can introduce bias at any stage in this process, and the source of bias is quite diverse:
It’s essential to understand the mechanics of introducing a bias if we want to deal with it efficiently. Broadly, we can classify bias in machine learning algorithms into multiple categories:
- Prejudicial Bias: Fundamentally, biases make their way into an application because those of us designing them carry these biases knowingly or unknowingly. Over the ages, we, as a society, have developed deep-rooted prejudices that are difficult to do away with. This can influence any stage of developing a machine learning application. Hence, this is perhaps the most complex and important source to correct.
- Sampling Bias: Another common source of bias is how we collect data to train our model. Intentionally or unintentionally, we may oversample from a population group, leading to the predictions being biased towards the characteristics representative of that group. For instance, we may be sampling from a particular gender more often than others.
- Algorithm Bias: The next step is choosing an algorithm that we’ll use to create the model to train. As we’ve previously seen, there are several algorithms to choose from, like linear regression, support vector machines, decision trees, etc. Although these algorithms have broad applications, there are certainly use cases that fit an algorithm better. The wrong choice of algorithm can also lead to bias in predictions.
- Confirmation Bias: Once we start to train our model and evaluate its predictions, we may tend to retain information that affirms our preconceived notions. We might start to exclude or remove data that goes against our theory in the process. This will lead to a certain bias in the data, and therefore our application’s predictions. While this may satisfy us as developers, it can significantly reduce the application’s usability.
By no means is this an exhaustive list of sources from where bias can enter a machine learning application. But this does cover the most frequently occurring sources of bias. By effectively dealing with these sources, we should be able to achieve a more reasonable application.
5. How to Identify and Measure Bias
In the previous sections, we learned what bias is and how it can enter a machine learning application. It’s also fairly obvious why we should try to get rid of it as much as possible. But before we try to reduce or eliminate bias, it’s essential to identify and measure bias in our application. Since a machine learning model can continuously improve itself through incremental data, it’s important to look for bias and take measures against it periodically.
The way a machine learning application generates outcomes is often very loosely understood. For most practical applications, we treat this as a black box where data enters in one end, and predictions flow from the other:
We can build intuitions behind those predictions for some of the simpler models, like linear regression. But it’s more complicated for complex models, like neural networks and deep learning models. Even when these models are working efficiently, it’s quite tricky to understand the inner mechanics of what’s happening.
This makes it hard to know how and why a particular machine learning application generates biased outcomes. Thus, the emphasis should be to continuously check for biases in an application’s large set of predictions. Every organization should establish what can constitute a bias in the context of its operations. For example, a recruitment firm should periodically assess if they’re selecting more often from a particular gender, race, or ethnicity.
6. How to Prevent Bias in Machine Learning
Finally, we can address the bias. As we saw earlier, machine learning is essentially a heuristic process. Although we can explain it to a certain extent, we don’t understand it completely. This also makes checking and eliminating biases cumbersome.
Nevertheless, this remains an important topic for the field of its study.
The problem of bias has existed in machine learning applications for decades, and so too have the efforts to handle them efficiently. Over the years, we’ve developed several best practices to avoid biases as much as possible. The onus is mainly on the organizations leveraging these applications to define a framework to deal with this in a traditional manner:
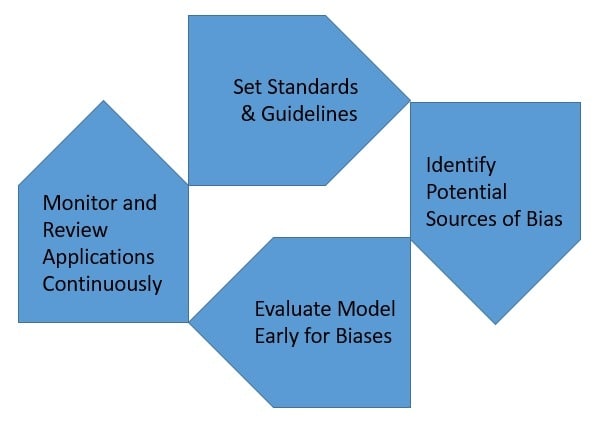
- Set Standards and Guidelines: One of the first steps towards handling biases is to get serious about them. Although we’ve got a very mature set of best practices, it’s continuously evolving. It’s essential for any organization to set evident standards and guidelines to look for potential biases and ways to handle them. More importantly, these standards and guidelines need to be reviewed frequently.
- Identify Potential Sources of Bias: As we saw, the data we feed into a machine learning model primarily forms the basis of predictions it makes. Therefore, we should be careful in identifying potential sources of bias in collecting data. This could come from our prejudices, a fault in our measurements, biased sampling, etc. Identifying all such possible sources is the key to remedial actions.
- Evaluate Model Early for Biases: When we develop a machine learning application, we take great care to ensure it delivers the performance we expect. We often only measure and react to performance measures like accuracy and precision. It’s essential that we see the measure of bias as an equally relevant performance indicator. This will help us take care of potential biases early in the process.
- Monitor and Review Applications Continuously: Almost all machine learning models are trained with a certain amount of training data. When the application is deployed in production, the actual data can vary with time. Moreover, the model continuously learns from more data it observes in production. So it’s quite important to continuously observe the performance of such applications for potential biases while in operation.
7. How Does It Relate to Responsible AI
As we previously discussed, machine learning is part of a larger umbrella that we refer to as artificial intelligence. We often employ many techniques under this umbrella to create intelligent and autonomous systems. As a result, the problem of biases isn’t only restricted to machine learning. In fact, the field of artificial intelligence is facing ever-growing ethical and legal concerns.
In this regard, governments, large organizations, and civil societies discuss making the parties involved in these practices more responsible. This often comes in a governance framework that we call Responsible AI, which aims to develop fair and trustworthy artificial intelligence applications.
When we refer to artificial intelligence, we usually mean machine learning. This is due to machine learning’s sheer popularity and practical applications. Consequently, when we refer to Responsible AI, a governance framework promoting transparency and democratization in machine learning applications is its foundation.
Today, the responsibility to develop this kind of governance framework is primarily up to organizations. Large organizations employing substantial AI applications have made their policy around Responsible AI public. There are a lot of steps they’re taking to ensure it’s fair and comprehensive. However, there is a lack of standardization across organizations in this regard.
8. Tools for Fair AI
As we’ve started to realize the importance of fairness in AI, some tools have become available in the open-source world to help us in this regard. Once we’ve done our due diligence to follow all the best practices in developing a proper application, we can turn to these tools to evaluate its performance.
One such tool has been made available by the People & AI Research (PAIR) team at Google. This tool is called What-If Tool, and it provides visualization for developers to try on five different types of fairness. It presents five buttons that sort data according to different fairness based on mathematical measures.
Another tool we can use in this regard is AI Fairness 360 toolkit from IBM Research. This extensible toolkit can help us examine, report, and mitigate discrimination and bias in machine learning models throughout the AI application lifecycle. These Python packages include a comprehensive set of metrics for datasets and models to test for biases.
9. Conclusion
In this article, we examined biases in machine learning applications. We also discussed how to identify the source of biases and measure them in applications. Then we looked at ways to handle biases so that we can reduce or eliminate them. Most importantly, we learned why it’s crucial to take care of such biases.