

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Probably Approximately Correct (PAC) learning defines a mathematical relationship between the number of training samples, the error rate, and the probability that the available training data are large enough to attain the desired error rate.
In this tutorial, we’ll discuss the PAC learning theory and review its results.
We use a collection of training samples to train a machine learning algorithm to learn classification or regression patterns. Usually, we calculate various metrics to estimate its performance. One of these metrics is the error rate.
However, the problem is that we can only estimate it using a test set. The estimates differ from the actual value due to their statistical nature. So, we may ask how many training samples we need to be confident about our estimates.
The PAC theory is an answer to that. It’s about finding the relationship between the true error rate and the number of training samples.
Additionally, the PAC theory is concerned with the confidence with which we can say that our estimate is correct.
Let’s set up the notation and revise the prerequisites.
Let’s say we have a set  of samples
of samples  with size
with size  , where
, where  are the features and
are the features and  are the labels.
are the labels.
Then, we have a hypothesis space  , which contains the class of all possible hypotheses (e.g., linear classifiers) that we’d like to use to find the mapping between the features and the labels. Additionally, the target concept
, which contains the class of all possible hypotheses (e.g., linear classifiers) that we’d like to use to find the mapping between the features and the labels. Additionally, the target concept  is the true underlying function from which we’ve drawn the training samples. In other words, for any , we have
is the true underlying function from which we’ve drawn the training samples. In other words, for any , we have  .
.
The hypotheses that fit the data with zero error are called consistent with the training data. We call the set of hypotheses that are consistent with training data the version space.
Since the error on the training data for a hypothesis from the version space is zero, we have no idea about the true error. The main theorem in PAC learning describes the relationship between the number of training samples , the true error rate  , and the size of the hypothesis space
, and the size of the hypothesis space  .
.
It says that the probability that the space contains a training-consistent hypothesis with a true error rate  is lower than
is lower than  . Mathematically:
. Mathematically:
![\[P(\exists h\in H, s.t.\ error_{train}(h) = 0\ \land\ error_{true}(h) > \epsilon) < |H|e^{-\epsilon m}\]](/wp-content/ql-cache/quicklatex.com-70feb449f84921193c32b0bd4b531356_l3.svg "Rendered by QuickLaTeX.com")
The assumptions are that is finite and the training samples are independent and identically distributed.
The word approximately means that hypotheses from the hypothesis space can produce errors, but the error rate can be kept small with enough training data.
We want to find the probability of containing a hypothesis with zero error on the training set and the true error rate greater than  .
.
The probability that a classifier whose error rate is greater than classifies a training sample correctly is lower than  . In addition, we can see that:
. In addition, we can see that:
![\[1 - \epsilon \le e^{-\epsilon}\]](/wp-content/ql-cache/quicklatex.com-f26495daf4de3f910628c4a2c8e9dae7_l3.svg "Rendered by QuickLaTeX.com")
So, the probability it will correctly classify all the training data points is less than  .
.
Now, let  be the set of all hypotheses in whose error rate is greater than . The probability that any hypothesis from is consistent with the training data is at most
be the set of all hypotheses in whose error rate is greater than . The probability that any hypothesis from is consistent with the training data is at most  .
.
Since  , the probability that contains a hypothesis with an error rate greater than and consistent with the entire training set is at most:
, the probability that contains a hypothesis with an error rate greater than and consistent with the entire training set is at most:
![\[|H|e^{-\epsilon m}\]](/wp-content/ql-cache/quicklatex.com-9156d394f3b87ed18ec90d637103b589_l3.svg "Rendered by QuickLaTeX.com")
which we wanted to prove.
We can bound  from above:
from above:
![\[|H|e^{-\epsilon m} \leq \delta\]](/wp-content/ql-cache/quicklatex.com-bfe78c73246113e163d9dba2d03f56bf_l3.svg "Rendered by QuickLaTeX.com")
From this, we can calculate the number of samples (i.e., sample complexity) we need for a set of hypotheses to be approximately correct with the predefined probability:
![\[m \geq \frac{1}{\epsilon}\left(\ln |H| + \ln \frac{1}{\delta}\right)\]](/wp-content/ql-cache/quicklatex.com-36e595462f9305985c02ee29e315ac64_l3.svg "Rendered by QuickLaTeX.com")
This is where the word probably in probably approximately correct comes from. So, if we had more than  samples, we could decrease the error rate to a value lower than . The same goes for
samples, we could decrease the error rate to a value lower than . The same goes for  . With more data, we get a tighter bound.
. With more data, we get a tighter bound.
It’s worth mentioning that this is the worst-case scenario since, in real-life applications, we can train models with less data than this formula suggests.
Agnostic PAC learning considers the case where the hypothesis space is inconsistent with the training data. That means the error rate of the hypothesis set on the training data is non-zero. In this case, we have:
![\[ P(error_{true}(h) > error_{train}(h) + \epsilon) \leq |H|e^{-2m\epsilon^2} \]](/wp-content/ql-cache/quicklatex.com-66dba5ff9e64d04e84d61873b237e001_l3.svg "Rendered by QuickLaTeX.com")
That means that the probability that the space contains a hypothesis whose true error ( ) is at least plus its training error (
) is at least plus its training error ( ) will be less than
) will be less than  .
.
From the above inequality, we can find the sample complexity in agnostic PAC learning:
![\[ m \geq \frac{1}{2\epsilon^2} \left(\ln |H| + \ln \frac{1}{\delta} \right)\]](/wp-content/ql-cache/quicklatex.com-2893ed5f2e3ca7307a30b47e96be4d2b_l3.svg "Rendered by QuickLaTeX.com")
Let’s take as an example the space of conjunctions using boolean literals. There are three possibilities for each literal: (positive, negative, or not appearing in a formula). As a result, the size of the hypothesis space is  .
.
Let  . If we want a hypothesis that’s
. If we want a hypothesis that’s  accurate (
accurate ( ) with
) with  chance (
chance ( ), then we need
), then we need  samples.
samples.
As we saw above, PAC learnability for a concept class holds if the sample complexity is a polynomial function of  ,
,  ,
,  , and size().
, and size().
VC dimension is the maximum number of points a hypothesis can shatter (i.e., separate differently labeled points for any labeling). PAC learnability and VC dimension are closely related:
In this case, we can calculate the sample complexity using the VC dimension of the hypothesis space :
![\[m > \frac{1}{\epsilon}(8VC(H)\log\frac{13}{\epsilon} + 4\log\frac{2}{\delta}) \]](/wp-content/ql-cache/quicklatex.com-40f10c1e26954221a94b84494bac1978_l3.svg "Rendered by QuickLaTeX.com")
where is the learner’s maximum error with the  probability.
probability.
Let’s review some examples.
The set of axis-aligned rectangles in a two-dimensional space is PAC-learnable.
To show this, it’s sufficient to find the sample complexity of this hypothesis set. And to do that, we can find its VC dimension.
From the figures below, we can see that a rectangle can separate two, three, and four data points with any labeling:
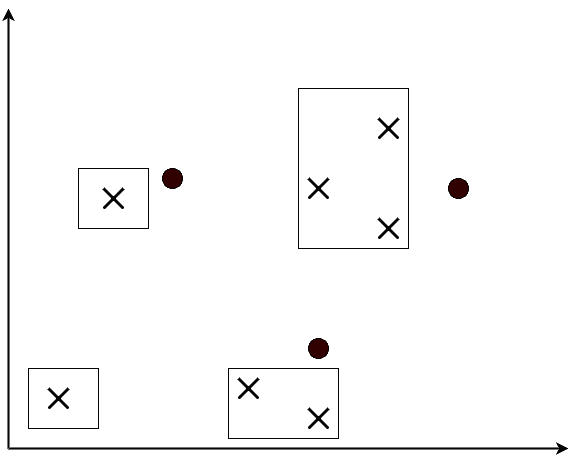
No matter how these points are labeled, we can always place a rectangle that separates differently labeled points.
However, when there are five points, shattering them with a rectangle is impossible. As a result, the VC dimension of axis-aligned rectangles is 4.
Using this, we can calculate the sample complexity with arbitrary and .
So, the class of 2D rectangles is PAC-learnable.

A classifier in a one-dimensional line can shatter at most 2 points, and a line in two-dimensional space can shatter at most 3 points. Similarly, the VC dimension of a polynomial classifier of degree is  . As a result, each finite polynomial is PAC-learnable.
. As a result, each finite polynomial is PAC-learnable.
However, the class of all polynomial classifiers (i.e., their union) has a VC dimension of  . Therefore, the union of polynomial classifiers is not PAC-learnable.
. Therefore, the union of polynomial classifiers is not PAC-learnable.
So, although any set of polynomials with the same finite degree is learnable, their union isn’t.
In this article, we gave an explanation of the PAC learning theory and discussed some of its main results.
In a nutshell, PAC learning is a theoretical framework investigating a relationship between the desired error rate and the number of samples for training a learnable classifier.