

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
An Introduction to the Hidden Markov Model
Last updated: August 31, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll look into the Hidden Markov Model, or HMM for short. This is a type of statistical model that has been around for quite a while.
Since its appearance in the literature in the 1960s, it has been battle-tested through applications in a variety of scientific fields. Moreover, it’s still a widely preferred way to tackle many data modeling tasks.
The HMM was first used for speech recognition, but since then, scientists have used the approach for part-of-speech tagging, time-series analysis, gene prediction, transport optimization, and many other sequence-related tasks.
2. The Model
One might wonder why the HMM is so versatile and effective. The answer lies in the solid mathematical principles on which the model is based and in its simplicity.
Every hidden Markov Model relies on the assumption that the events we observe depend on some internal factors or states that are not directly observable. This trait is very general, which makes it very applicable and is also where the hidden part of the name comes from.
The Markov part, however, comes from how we model the changes of the above-mentioned hidden states through time. Additionally, we use the Markov property, a strong assumption that the process of generating the observations is memoryless, meaning the next hidden state depends only on the current hidden state. This consequently also makes things a lot easier to work with mathematically, as we’ll see later.
2.1. A Guessing Game
Let’s start with a classic example to better understand the characteristics of the Hidden Markov Model. Alice and Bob are close friends who live far away from each other, but they talk over the phone every day and discuss what they do. They decide to play a guessing game in which Alice tries to guess the weather based only on what Bob tells her he is doing that day.
For simplicity, let’s imagine Bob’s behavior is limited. He can do one of three things during the day – walk in the park, go shopping, or clean his apartment. Additionally, his actions fully depend on the weather of the given day. Therefore, the weather will also have only two states: rainy or sunny.
2.2. The Markov Property
Even with those conditions, it’s still hard for Alice to guess the weather. However, let’s explore how Alice might tackle this problem.
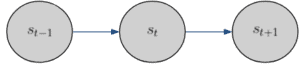
The first case is when the weather is exclusively affected by the weather yesterday. This is the Markov property and an important assumption we make when using the Hidden Markov Model. Mathematically, we can say the probability of the weather being in a certain state  at a certain time
at a certain time  only depends on time step
only depends on time step  :
:

This can also be illustrated with a simple diagram with respect to time:
2.3. Markov Chains
Since Alice has an idea of the weather in Bob’s area, we can also translate her knowledge into probabilities.
If yesterday was sunny, there is a  probability that today will be sunny again. Similarly, we have a
probability that today will be sunny again. Similarly, we have a  probability that it’ll rain. Likewise, if it had been raining yesterday, there would have been a
probability that it’ll rain. Likewise, if it had been raining yesterday, there would have been a  probability that it would rain again and a
probability that it would rain again and a  probability that it would be sunny.
probability that it would be sunny.
Since the sequence has to start from somewhere, Alice says that there is a probability of starting with a rainy day and for starting with a sunny day. Therefore, Alice’s model would then look like this:
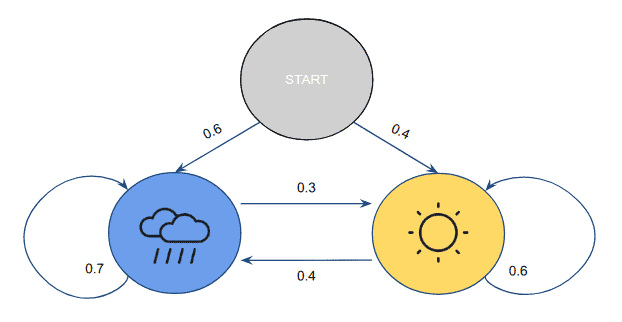
This kind of model is also known as a Markov Chain, and the probability of getting from one state to the other is called transition probability. Generally, these probabilities are defined using a transition matrix. In our example, the transition matrix would be:
![\[A = \begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \\ \end{bmatrix} = \begin{bmatrix} 0.6 & 0.4 \\ 0.3 & 0.7 \\ \end{bmatrix}\]](/wp-content/ql-cache/quicklatex.com-2ceca722ca25ad4e30c92ad142afe232_l3.svg "Rendered by QuickLaTeX.com")
Here, one important property to notice is that the sum of all transition probabilities from a particular state should be 1. In other words, the rows of our matrix should sum up to 1.
Additionally, since we got to start from somewhere, we define another one-dimensional vector  that contains the initial probabilities:
that contains the initial probabilities:
![\[\pi=\begin{bmatrix} 0.4 & 0.6\end{bmatrix}\]](/wp-content/ql-cache/quicklatex.com-f865e9093819373b2f0bb05bd97a4b7f_l3.svg "Rendered by QuickLaTeX.com")
2.3. Model Summary
Therefore, till now, we have discussed the total number of hidden states  , the transition probability matrix
, the transition probability matrix  , and the initial probability vector .
, and the initial probability vector .
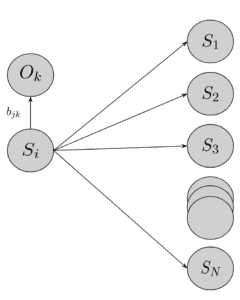
However, we’d also need to incorporate Bob’s activities somehow. As we said, they depend fully on the weather. Hence, we can assign conditional probabilities for each state, which are known as emission probabilities.
For example, if today is sunny, there is a  probability that Bob will go for a walk,
probability that Bob will go for a walk,  for shopping, and for cleaning his house. Since Alice talks with him each day, she has gathered a sequence of observations of his actions. Depending on her observations, one possible combination of probabilities might be:
for shopping, and for cleaning his house. Since Alice talks with him each day, she has gathered a sequence of observations of his actions. Depending on her observations, one possible combination of probabilities might be:
![\[B = \begin{bmatrix} b_{11} & b_{12} & b_{13}\\ b_{21} & b_{22} & b_{23}\\ \end{bmatrix} = \begin{bmatrix} 0.1 & 0.4 & 0.5\\0.6 & 0.3 & 0.1\\ \end{bmatrix}\]](/wp-content/ql-cache/quicklatex.com-5309d9f2519ba24a1a1075216d1902c7_l3.svg "Rendered by QuickLaTeX.com")
where each row of the matrix  represents a hidden state and each column an activity.
represents a hidden state and each column an activity.
After including , we now have everything needed to assemble the Hidden Markov Model that gives Alice the best chance of guessing correctly. Visually, we get the following picture:
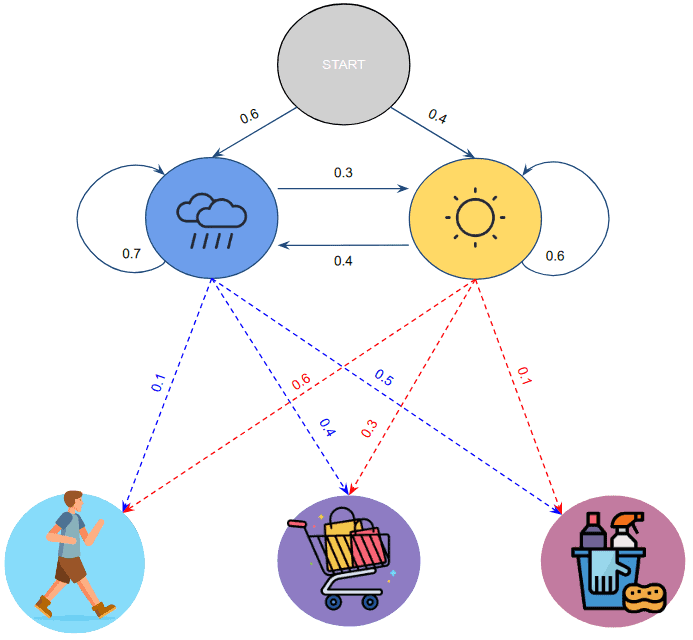
However, now the question is how would Alice use it to infer the weather. Well, she’ll need to answer the following question: What is the sequence of hidden states given our model that best explains the given sequence of observations? Answering this, however, is not so trivial.
3. The Evaluation Problem
To better grasp the above question, let’s try to answer its inverse first: What is the probability that this particular model generated the given sequence of observations?
Let’s also add some mathematical notation. We have a series of observations  for
for  time steps representing the number of days talking to Bob in our example. Additionally, we have our model in the form of the parameters , , and , which we can, for short, denote as
time steps representing the number of days talking to Bob in our example. Additionally, we have our model in the form of the parameters , , and , which we can, for short, denote as  .
.
Therefore, the question “What is the probability that this particular model generated the given sequence of observations?” can be expressed as:
![\[p(O_T \mid \theta) = ?\]](/wp-content/ql-cache/quicklatex.com-938f249f0b12e0a79bd7174275c0baef_l3.svg "Rendered by QuickLaTeX.com")
To answer it, let’s first imagine a particular sequence of hidden states  that generates the sequence of observations. For example, if we have
that generates the sequence of observations. For example, if we have  days of observations
days of observations  , one possible hidden sequence might be
, one possible hidden sequence might be  . What would be the probability of seeing this observation sequence given ?
. What would be the probability of seeing this observation sequence given ?
We need only to multiply the probabilities of seeing a particular observation  given the hidden state at time
given the hidden state at time  :
:
![\[p(O_T \mid S_T, \theta) = \prod_{t=1}^{T} p(O_t \mid s_t, \theta)\]](/wp-content/ql-cache/quicklatex.com-6a5e5ba1ed2749b7152f15bdbd7b7e83_l3.svg "Rendered by QuickLaTeX.com")
This can be easily calculated by looking up the particular emission probability in for each hidden state in the sequence. For the example  this would be:
this would be:
![\[p(Walk, Shopping, Cleaning \mid Sunny, Sunny, Rainy)= p(Walk \mid Sunny)* p(Shopping \mid Sunny)* p(Cleaning \mid Rainy) = 0.6 * 0.3 *0.5\]](/wp-content/ql-cache/quicklatex.com-caabe2bbd457e3a6d95a86a8a11ba640_l3.svg "Rendered by QuickLaTeX.com")
3.1. Formulation
However, we don’t know the exact sequence that gave us the observations. But for starters, let’s answer the question of the probability of a particular hidden state sequence occurring like the one in our example. Since we’re operating under the Markov Property, each state transition is independent:
![\[p(S \mid \theta) = \prod_{t=1}^{T} p(s_t \mid s_{t-1})\]](/wp-content/ql-cache/quicklatex.com-7c7676cff3da924e9d35f878ad022d8b_l3.svg "Rendered by QuickLaTeX.com")
So, the joint probability of getting a particular hidden sequence and a particular observation sequence would be:
![\[p(O,S) = \prod_{t=1}^{T} p(O_t \mid s_t, \theta)\prod_{t=1}^{T} p(s_t \mid s_{t-1})\]](/wp-content/ql-cache/quicklatex.com-e51758d8826c2bf54203b659cf65fee4_l3.svg "Rendered by QuickLaTeX.com")
We, however, need to consider all possible combinations of state sequences that could have generated the observation sequence. To do that, we can marginalize out all the joint probabilities of all possible hidden state sequences and their occurrence by summation:
![\[\begin{aligned} p(O \mid \theta) & =\sum_{q=1}^{Q}p(O,S_q \mid \theta) \\ & =\sum_{q=1}^{Q}\prod_{t=1}^{T} p(O_t \mid s_t, \theta)\prod_{t=1}^{T} p(s_t \mid s_{t-1})\]](/wp-content/ql-cache/quicklatex.com-498bbce24439a9a0757ef138a3e50a8d_l3.svg "Rendered by QuickLaTeX.com")
where  is the number of all possible hidden state sequences.
is the number of all possible hidden state sequences.
Calculating this won’t be a problem, but the computation complexity is very high for practical scenarios. If the number of hidden states is , there are  possible state sequences. For each sequence of hidden states, we calculate transitions and emissions between hidden states.
possible state sequences. For each sequence of hidden states, we calculate transitions and emissions between hidden states.
Hence, the total number of operations we need to perform for each sequence of the hidden state is  . Therefore, a total of
. Therefore, a total of  operations are required. Finally, the time complexity would be
operations are required. Finally, the time complexity would be  .
.
3.2. The Forward Algorithm
Not all is lost, though. In this enormous calculation, there are many redundant products that imply the use of another way of formulating the result we´re after. The most common approach is the Forward-Backward Algorithm, which strongly relies on the principles of Divide-and-conquer. As the name suggests, this algorithm consists of two parts: forward and backward. However, only one is usually enough to answer our first question, so let’s look at the forward part first.
To employ the forward part of this approach, we’ll need to express the probability of a particular hidden state  at a particular time in terms of the steps before it. We’re going to do this inductively by introducing a new aggregate variable
at a particular time in terms of the steps before it. We’re going to do this inductively by introducing a new aggregate variable  , which is going to capture the probability of seeing a series of observations up to a certain point and then end up at
, which is going to capture the probability of seeing a series of observations up to a certain point and then end up at  given our model:
given our model:
![\[\alpha_t(i) = p(O_1,O_2,...,O_3, q_t=S_i \mid \theta)\]](/wp-content/ql-cache/quicklatex.com-f26e128c775aab7dae9f41bbce2e5c26_l3.svg "Rendered by QuickLaTeX.com")
The base case for our variable would then be:
![\[\alpha_1(i) = \pi_i b_i(O_1)\]](/wp-content/ql-cache/quicklatex.com-a13a7aedf738b93979f53dc47a31e0e2_l3.svg "Rendered by QuickLaTeX.com")
for  .
.
Furthermore, for the inductive step, we describe more generally  :
:
![\[\alpha_{t+1} = \bigg[\sum_{i=1}^{N}\alpha_t(i) a_{ij}\bigg]b_j(O_{t+1})\]](/wp-content/ql-cache/quicklatex.com-0efe9976a527c3c46d0abf97e7a261f4_l3.svg "Rendered by QuickLaTeX.com")
for  and .
and .
What the above equation is saying is that the probability of seeing the series of observations up to and ending up at state  is equal to the sum of all the different ways of getting to state given our observation sequence(
is equal to the sum of all the different ways of getting to state given our observation sequence( ) multiplied by the probability of actually transitioning to (
) multiplied by the probability of actually transitioning to ( ) and also observing the next observation
) and also observing the next observation  given that we are now at state (
given that we are now at state ( ).
).
Another way to look at the equation is through a diagram:
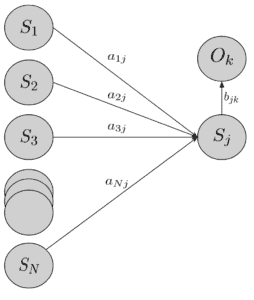
Furthermore, the only thing we need to account for is that in the last time step, we don’t need to transition anymore. Hence, we can just sum over all alphas:
![\[p(O_T \mid \theta) = \sum_{i=1}^{N}\alpha_T(i)\]](/wp-content/ql-cache/quicklatex.com-6e13d1f5988b3c4bbacb7bc955f3247e_l3.svg "Rendered by QuickLaTeX.com")
Overall, the algorithm works significantly faster for computing  compared to the naive calculation. Since for every time step, we are considering all previous states in the computation for every one of the next states, we have a computational complexity of
compared to the naive calculation. Since for every time step, we are considering all previous states in the computation for every one of the next states, we have a computational complexity of  , which is a significant improvement.
, which is a significant improvement.
3.3. The Backward Algorithm
What is more interesting about the Forward-Backward algorithm is that, as the name suggests, it works in reverse. As we have all the observations, we can apply the same logic backward. Instead of defining a parameter for the probability of seeing observations up to a certain point and being in a state , we can define a new recursive parameter  that’ll describe the probability of being in state at time knowing what observations are ahead.
that’ll describe the probability of being in state at time knowing what observations are ahead.
To formulate the base case of , we start from the end of our observations. Since there are no other observations following, we define it as one:
![\[\beta_T(i) = 1\]](/wp-content/ql-cache/quicklatex.com-f5079a0bb2d2b8ed1d36f8a401990dee_l3.svg "Rendered by QuickLaTeX.com")
and that’s for every one of our states  .
.
Furthermore, inductively, we can define every other to be:
![\[\beta_t(i) = \sum_{j=1}^{N}a_{ij}b_j(O_{t+1})\beta_{t+1}\]](/wp-content/ql-cache/quicklatex.com-0b23f1733da92a076c454bd69f454912_l3.svg "Rendered by QuickLaTeX.com")
In this equation again, just like with , we are considering all possible state transitions between states, but instead of accounting for the transitions forward, we’re looking backward and describing  not with the one before it but with the ones after it.
not with the one before it but with the ones after it.
Here is a diagram to highlight the difference:
4. The Decoding Problem
Now, we’re ready to answer our original question: What is the sequence of hidden states given our model that best explains the given sequence of observations?
One way of doing it would be to use our knowledge from the last section to calculate the probability that our model generated and the observation we saw for every possible sequence of hidden states. Furthermore, we find the one sequence with the biggest resulting value. Similar to the previous section, we can’t use the brute force method for this calculation as it’s not feasible.
Moreover, we can try to take inspiration from the Forward-Backward Algorithm. In both versions of that algorithm, we’re summing over each hidden sequence of states in a smart, recursive way. Let’s do something similar, but instead of using the summation operator, use the  one. The resulting approach is called the Viterbi algorithm.
one. The resulting approach is called the Viterbi algorithm.
Just like before, we can define a recursive variable that’ll contain the most probable path up to the current time step and ends up at state . The base case will start from the first time step and looks like this:


The only thing that is different here is that we need to take note of where we came from at each time step to recreate the path. To this end, we define a variable  , which would denote what state we came from, given that we’re at the current state .
, which would denote what state we came from, given that we’re at the current state .
For the base case , we don’t need to track any state, so it’ll simply be equal to zero.
As one might guess, the basic inductive step to extend our new parameters is again similar to the one in the Forward-Backward Algorithm:
![\[\begin{array}{lr} \delta_{t}(j)=\max _{1 \leq i \leq N}\left[\delta_{t-1}(i) a_{i j}\right] \cdot b_{j}\left(O_{t}\right) & 2 \leq t \leq T \\ \psi_{t}(j)=\underset{1 \leq i \leq N}{\operatorname{argmax}}\left[\delta_{t-1}(i) a_{i j}\right] & 1 \leq j \leq N \end{array}\]](/wp-content/ql-cache/quicklatex.com-cfbc0d9717488f4b17f653ded8bd026c_l3.svg "Rendered by QuickLaTeX.com")
which essentially means that  will denote the most probable path up to time step to transition into state and get the observations we have, while keeps track of the states visited.
will denote the most probable path up to time step to transition into state and get the observations we have, while keeps track of the states visited.
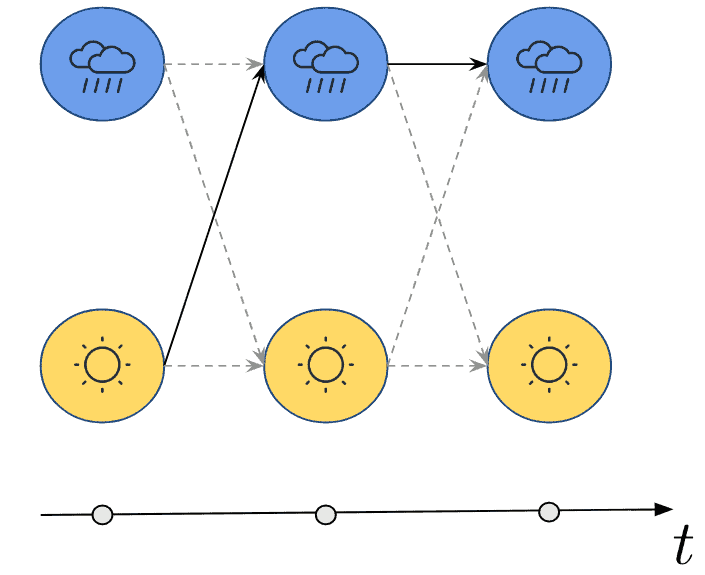
To illustrate visually, we can take our guessing game example and draw a diagram with the most probable path of hidden states given some examples of observations like  :
:
5. Conclusion
In this article, we discussed the hidden Markov Model, starting with an imaginary example that introduced the concept of the Markov Property and Markov Chains.
Furthermore, we consequently explored the Forward-Backward algorithm in pursuit of actually assigning correct probabilities, finally ending up with the similar but important Viterbi algorithm, which helps us fully use a ready HMM model.