

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll present three ways to determine the rank of a node in a binary search tree (BST).
2. A Node’s Rank in a Tree
The rank of a node value  in a tree is the number of the nodes whose values are
in a tree is the number of the nodes whose values are  . The nodes can be of any data type as long as it comes with an ordering relation
. The nodes can be of any data type as long as it comes with an ordering relation  . For example, the rank of
. For example, the rank of  in the following tree is
in the following tree is  :
:
So, we have a value and the root of a tree, and the goal is to find the ‘s rank in it.
We don’t assume that  is present in the tree. If it is, it may repeat. The approaches we’ll present cover all the cases.
is present in the tree. If it is, it may repeat. The approaches we’ll present cover all the cases.
3. The Brute-Force Method to Determine Rank
The most obvious approach is to recursively calculate and add up the numbers of nodes with values  in the left and right sub-trees. If the root is , we increment the sum by
in the left and right sub-trees. If the root is , we increment the sum by  . If not, the sum is the rank of in the whole tree:
. If not, the sum is the rank of in the whole tree:
![\[rank(x, root) = \begin{cases} 0,& root \text{ is the root of an empty tree}\\ 1 + rank(x, root.left) + rank(x, root.right),& root \text{ isn't empty and } x \leq root.value\\ rank(x, root.left) + rank(x, root.right), & root \text{ isn't empty and } x > root.value \end{cases}\]](/wp-content/ql-cache/quicklatex.com-c4dd3433f173f65009f97d33c41f63d3_l3.svg "Rendered by QuickLaTeX.com")
3.1. Pseudocode
Here’s the pseudocode:
algorithm BruteForceRank(node, x):
// INPUT
// x = the value whose rank we want to determine
// node = the root node of the (sub-)tree
// for which we're calculating the rank of x
// OUTPUT
// rank = the rank of x in the (sub-)tree whose root is node
if node = NONE:
return 0
// first, count the nodes that are <= x in the left sub-tree
rank_left <- BruteForceRank(node.left, x)
// then, count the nodes that are <= x in the right sub-tree
rank_right <- BruteForceRank(node.right, x)
if node.value <= x:
return 1 + rank_left + rank_right
else:
return rank_left + rank_right3.2. Example
Let’s see how this brute-force method calculates the rank of in the following tree:
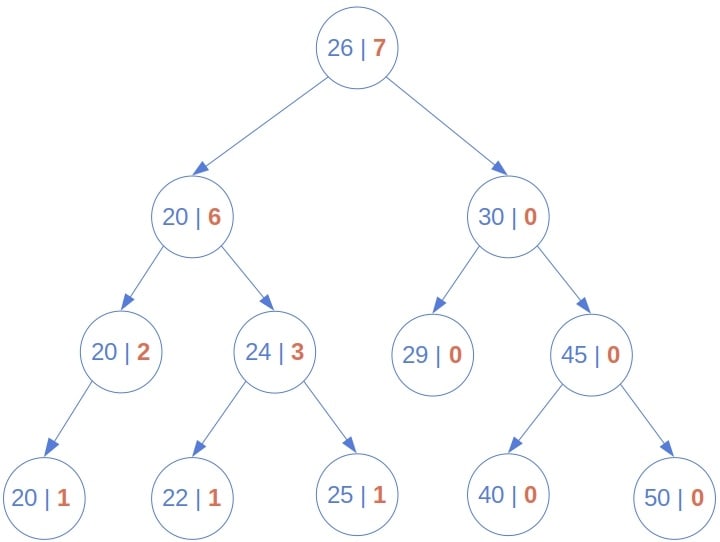
It goes all the way down to the leaves and recursively propagates the ranks of in the sub-trees until it gets to the root.
3.3. Complexity
This approach isn’t efficient. We always traverse the whole tree, so the time complexity is  , where
, where  is the number of nodes. The reason is that we don’t use the fact that the tree is ordered.
is the number of nodes. The reason is that we don’t use the fact that the tree is ordered.
4. Order-Based Calculation of Rank
There’s no need to calculate  if
if  because all the nodes in the right sub-tree are also greater than . So, we differentiate between two cases:
because all the nodes in the right sub-tree are also greater than . So, we differentiate between two cases:
- If
 , we should make recursive calls on both left and right sub-trees.
, we should make recursive calls on both left and right sub-trees. - If , we can disregard the right sub-tree.
The pseudocode is as follows:
algorithm OrderBasedCalculationOfRank(node, x):
// INPUT
// x = the value whose rank we want to determine
// node = the root node of the (sub-)tree
// for which we're calculating the rank of x
// OUTPUT
// rank = the rank of x in the (sub-)tree whose root is node
if node = NONE:
return 0
if node.value <= x:
return 1 + Rank(node.left, x) + Rank(node.right, x)
else:
return Rank(node.left, x)4.1. Example
This is how the order-based method determines the rank of :
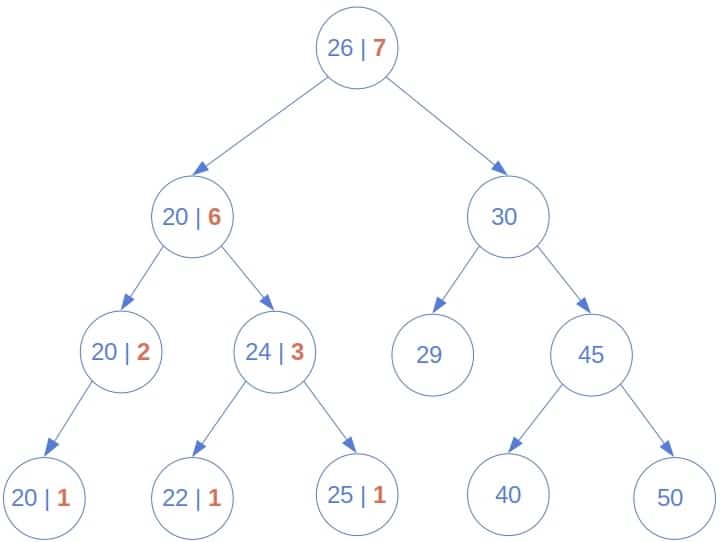
As we see, only the nodes less than or equal to were visited.
4.2. Complexity
The worst-case scenario happens when is greater than all the nodes in the tree. The algorithm will end up traversing the whole tree, so the worst-case time complexity is  , the same as for the brute-force approach.
, the same as for the brute-force approach.
Still, the method will mostly run faster than brute force because it visits exactly  nodes for any , whereas the brute-force solution visits nodes no matter the rank of .
nodes for any , whereas the brute-force solution visits nodes no matter the rank of .
We can, however, speed it up even more if we’re ready to do a little bookkeeping.
5. Order-Statistic Trees for Rank Calculation
If we augment each node with the information on its size, we can skip traversing the left sub-tree. Instead, we read the value of the size attribute and recurse on the right sub-tree only:
algorithm Rank(node, x):
// INPUT
// x = the value whose rank we want to determine
// node = the root node of the (sub-)tree
// for which we're calculating the rank of x
// OUTPUT
// The rank of x in the (sub-)tree whose root is node
if node = NONE:
return 0
if node.value <= x:
if node.left = NONE:
return 1 + Rank(node.right, x)
else:
return 1 + node.left.size + Rank(node.right, x)
else:
return Rank(node.left, x)The trees whose nodes store the size can efficiently answer the queries about the rank of a value and find the node that has the given rank. Such trees are called order-statistic trees.
5.1. Example
Let’s see which nodes this algorithm will visit to determine the rank of :
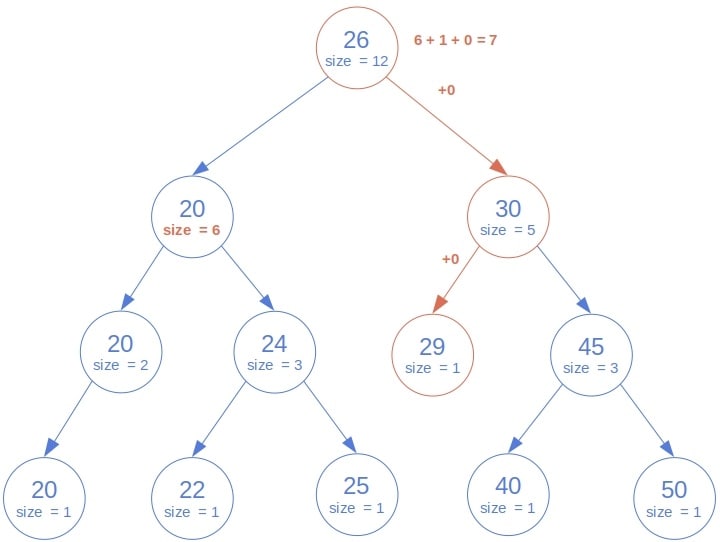
Since the root is  , we read the size of its left sub-tree (
, we read the size of its left sub-tree ( ), count the root as by adding to , and then recurse on the right sub-tree. The root of the right sub-tree (
), count the root as by adding to , and then recurse on the right sub-tree. The root of the right sub-tree ( ) is
) is  so that we can disregard it along with its right descendants. Therefore, we make a recursive call for its left child. It’s also , so we go to the left again. However, there’s no left child, so we return
so that we can disregard it along with its right descendants. Therefore, we make a recursive call for its left child. It’s also , so we go to the left again. However, there’s no left child, so we return  and propagate it to the root of the whole tree. That way, we calculate the rank as
and propagate it to the root of the whole tree. That way, we calculate the rank as  , which is the correct result.
, which is the correct result.
5.2. Complexity
This method traverses a single path in the tree to find the input value’s rank. Any path’s length is bounded by  , the tree’s height, i.e., the length of the longest path between the root and a leaf node. So, the time complexity is
, the tree’s height, i.e., the length of the longest path between the root and a leaf node. So, the time complexity is  . Depending on the tree’s structure, is usually considerably lower than . But, the downside is that whenever we add or delete a node, we have to update the size attributes of all the node’s ancestors to the root.
. Depending on the tree’s structure, is usually considerably lower than . But, the downside is that whenever we add or delete a node, we have to update the size attributes of all the node’s ancestors to the root.
If the tree is balanced, it will hold that  , so the whole algorithm will be of logarithmic complexity in the worst case. However, to keep the tree balanced, we need to rebalance it after every update.
, so the whole algorithm will be of logarithmic complexity in the worst case. However, to keep the tree balanced, we need to rebalance it after every update.
If the tree is unbalanced, the worst case is the degenerate tree consisting of a single branch with larger than all the nodes. In that case, the algorithm will visit all nodes and have the worst-case complexity of  just like the other two approaches.
just like the other two approaches.
5.3. Tail-Recursive Rank Calculation
Unlike the previous two methods, this one can be made tail-recursive since there’s nothing with the return value of a recursive call other than passing it up the call stack. To transform the function to the tail-recursive form, we accumulate the partial results and make sure that the return statement is the last one executed in the function’s body:
algorithm TailRecursiveRank(node, x, current):
// INPUT
// node = the root node of the (sub-)tree
// for which we are calculating the rank of x
// x = the value whose rank we want to determine
// current = the rank of x in the part of the tree considered before node
// (initialized to 0)
// OUTPUT
// rank = the rank of x in the (sub-)tree whose root is node
if node = NONE:
return current
if node.value <= x:
if node.left = NONE:
current <- current + 1
else:
current <- current + 1 + node.left.size
return TailRecursiveRank(node.right, x, current)
else:
return TailRecursiveRank(node.left, x, current)Tail-recursive functions can be tail-call optimized, which means that a single frame on the call stack can be reused for each call. Without tail-call optimization, we risk the stack overflow error if the path being visited is too deep.
Further, there’s a straightforward way to turn tail-recursive functions into iterative ones.
6. Discussion
Which algorithm should we use? The answer is: it depends.
The brute-force approach is the least efficient of all the three but is sometimes the only way to go. If the tree is ordered by relation  , and we want to find the rank for another relation
, and we want to find the rank for another relation  , our only option is brute force. We have to traverse the whole tree because
, our only option is brute force. We have to traverse the whole tree because  tells us nothing about
tells us nothing about  (in general).
(in general).
If we want to determine the rank for the same relation that orders the tree, the second and the third approaches will work better than brute force. If we can’t augment nodes with the size attribute, we should use the second algorithm. If we can, the third method should be our choice.
Whether or not we use the balanced trees depends on multiple factors. The first and the second algorithms don’t require balanced trees, but other operations we might perform on the tree may benefit if we keep it balanced. The third approach benefits the most from balancing the trees. But, due to rebalancing, it may not pay off. That’s the case if the rank queries are rare and insertions, deletions, and updates happen frequently.
7. Conclusion
In this article, we presented three ways to determine a node’s rank in a binary search tree. One is  if the input tree is balanced. Otherwise, all the three are in the worst case, although the two non-brute-force approaches are typically faster than the brute-force method in practice.
if the input tree is balanced. Otherwise, all the three are in the worst case, although the two non-brute-force approaches are typically faster than the brute-force method in practice.