

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
Merge sort is one of the fastest sorting algorithms. However, it uses an extra buffer array while performing the sort. In this tutorial, we’ll implement an in-place merge sort algorithm with constant space complexity.
Initially, we’ll quickly remind you of the traditional merge sort algorithm. After that, we’ll give two approaches to implementing an in-place version of the algorithm. Finally, we’ll provide a step-by-step example to show how the algorithm performs the sorting.
2. Traditional Merge Sort
In the traditional merge sort algorithm, we use an additional array to merge sorted parts. Let’s start by giving an example of how the algorithm works and then discuss the time and space complexities.
2.1. Example
The merge sort algorithm divides the array in half, sorts each recursively, and then merges the two sorted parts. To merge the two parts, we use an auxiliary array called the buffer array. Let’s check the following example:
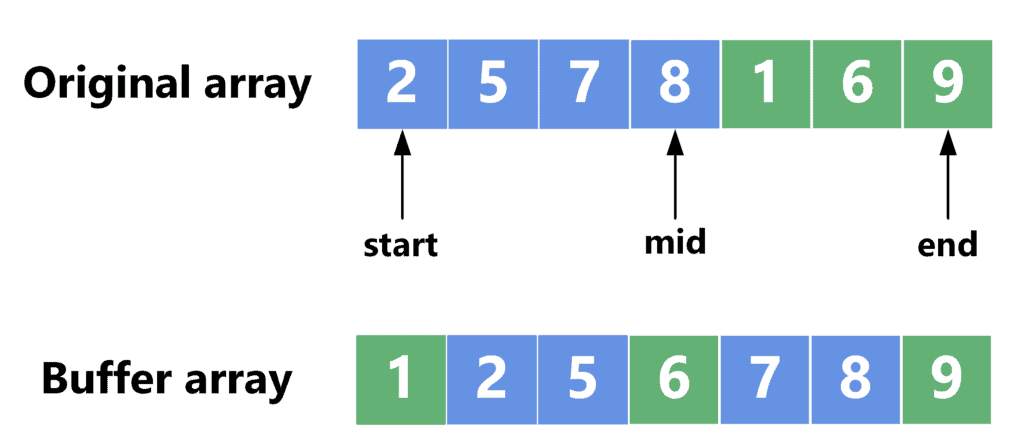
After sorting the two halves of the original array, we merged both parts into the buffer array. This is done by taking the smaller element between both halves and appending it to the buffer array. After this is done, the content of the buffer array can be copied over to the original array.
2.2. Complexity
The time complexity of merge sort is  , where
, where  is the number of elements inside the array. Although the time complexity is considered very good, the space complexity is a problem. Since we need the buffer array to merge the sorted parts, the space complexity of merge sort is
is the number of elements inside the array. Although the time complexity is considered very good, the space complexity is a problem. Since we need the buffer array to merge the sorted parts, the space complexity of merge sort is  , where
, where  is the size of the array.
is the size of the array.
3. Naive In-Place Merge Sort
Let’s start with the naive approach to implementing an in-place merge sort. We’ll provide an example, then jump into the implementation and discuss the complexities of time and space.
3.1. Naive Approach Example
Since we’ll use an in-place approach, we can’t define any buffer arrays and must perform the merge sort on the same array. To merge two sorted parts of the array, we always compare the smaller element in each part and output the smaller one to the result.
Note that when using the same array to perform the merge, and if the element on the left part is smaller than the element on the right, we don’t need to do anything. This is because the element on the left side is already in its correct location.
However, if the element on the right is smaller, it must be placed before all the elements on the left side. Therefore, we’ll shift the elements on the left side to the right by one, freeing one space before it. Then, we can move the small element into that space.
This can be shown through the following example:
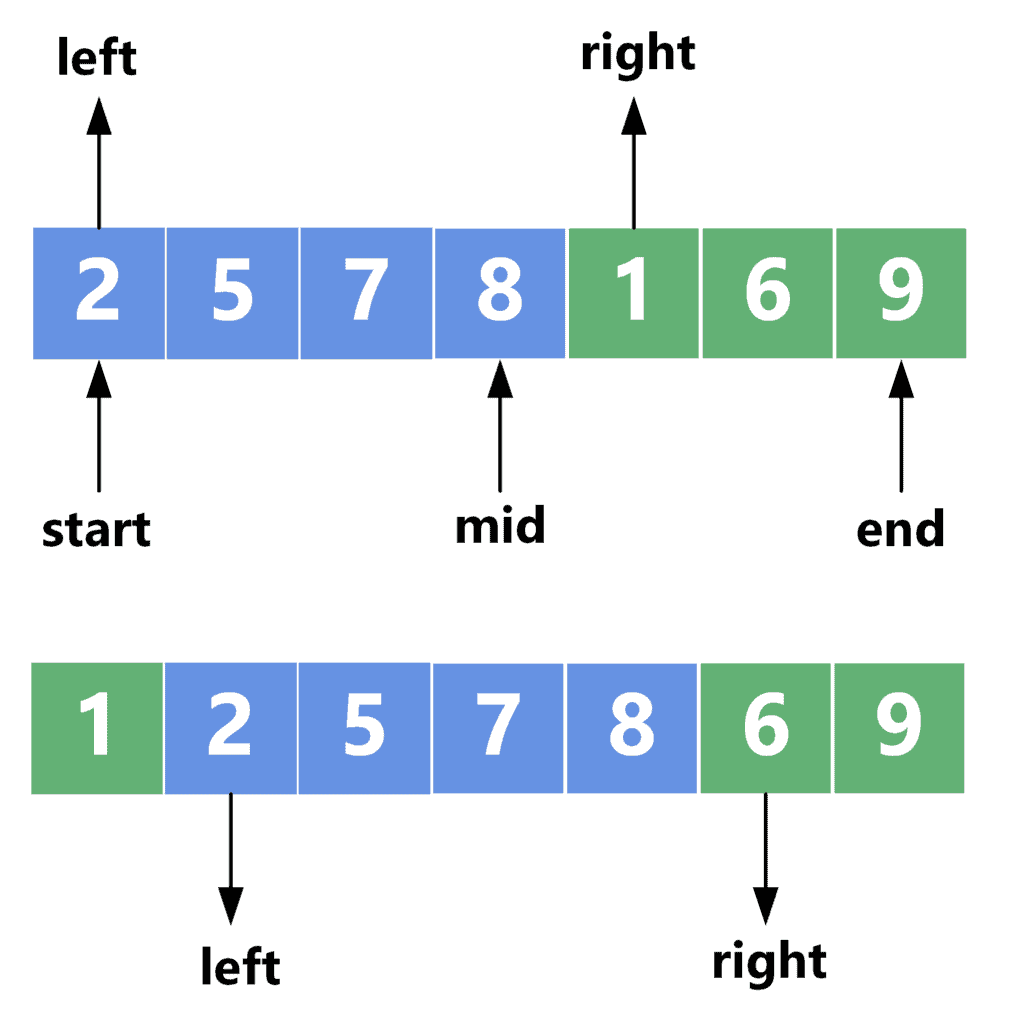
As we can see, the values  and
and  point to the first element in each part. Since
point to the first element in each part. Since ![array[right] = 1](/wp-content/ql-cache/quicklatex.com-78899d47a2d9037db2091767d6c4775a_l3.svg "Rendered by QuickLaTeX.com") is smaller than
is smaller than ![array[left] = 2](/wp-content/ql-cache/quicklatex.com-9b793f6f9c02183fd94753aa36e0d043_l3.svg "Rendered by QuickLaTeX.com") , we shift all the elements on the left side one step forward. After that, we place the smallest value in its place and move the pointer one step forward to the next element.
, we shift all the elements on the left side one step forward. After that, we place the smallest value in its place and move the pointer one step forward to the next element.
Now, we can move to implement the algorithm described in this example.
3.2. Naive Approach Implementation
Take a look at the implementation of the naive approach:
algorithm NaiveMergeSort(array, start, end):
// INPUT
// array = the array to be sorted
// start = the starting index of the array
// end = the ending index of the array
// OUTPUT
// The array is sorted in-place
if start >= end:
return
mid <- (start + end) / 2
NaiveMergeSort(array, start, mid)
NaiveMergeSort(array, mid + 1, end)
left <- start
right <- mid + 1
while left <= mid and right <= end:
if array[left] <= array[right]:
left <- left + 1
else:
temp <- array[right]
shift(array, left, mid)
array[left] <- temp
left <- left + 1
mid <- mid + 1
right <- right + 1We define a function called  that takes the required array and the
that takes the required array and the  and
and  positions of the array. Initially, this function should be called with
positions of the array. Initially, this function should be called with  and
and  , where is the size of the array.
, where is the size of the array.
We start by checking the base case. If we reach an array with a size of less than one, then this array is already sorted, and we return immediately. Otherwise, we sort both halves recursively.
Once both halves are sorted, we start the merging process. We check if the left element is smaller than the right one. If so, then it’s already in its correct place. Thus, we only move the pointer one step forward to the next element.
However, if the right element is smaller, we shift the array’s left part one step forward and place the right element before the left part. After that, we move the ,  , and pointers one step forward.
, and pointers one step forward.
After the  loop ends, it means one of the two conditions was broken. If reaches the point, all the left-side elements are already in place, and whatever is left to the right is already in the correct place.
loop ends, it means one of the two conditions was broken. If reaches the point, all the left-side elements are already in place, and whatever is left to the right is already in the correct place.
If the pointer reached the end, we already placed all right-side elements in their correct place. In this case, the left-side elements remain at the end of the array, which should already be in their correct place.
3.3. Naive Approach Complexity
The extra space complexity of the naive approach is  because we didn’t use any additional arrays besides the original one. However, the time complexity is a little tricky to calculate. To do that, take a look at the following figure:
because we didn’t use any additional arrays besides the original one. However, the time complexity is a little tricky to calculate. To do that, take a look at the following figure:
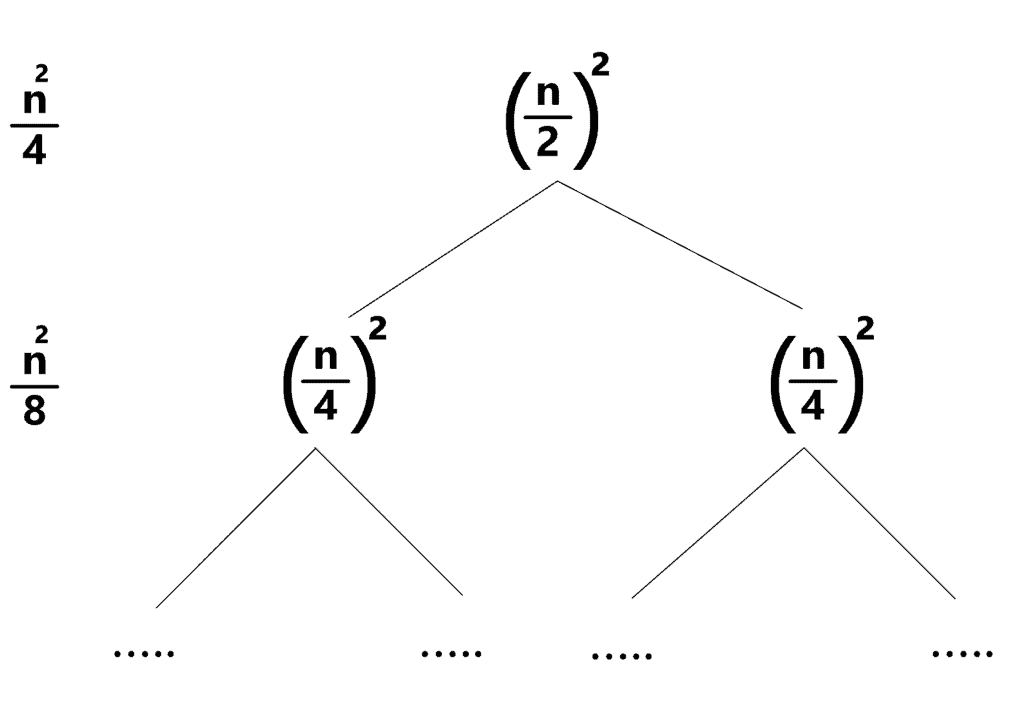
The first level represents the merging that is done on the full array. At that level, the array is divided into two halves. In the worst case, we’ll shift the right part  times, where is the number of elements. Each shifting operation takes approximately operations. Thus, the overall complexity for that level is
times, where is the number of elements. Each shifting operation takes approximately operations. Thus, the overall complexity for that level is  .
.
The next level is applied twice, one time for each half. Similarly to the previous case, we need  shifting operations for each half that result in a total of
shifting operations for each half that result in a total of  complexity. However, since this is applied on each half, the overall complexity is
complexity. However, since this is applied on each half, the overall complexity is  , which is
, which is  ).
).
By following this sequence, we can formulate the following formula for the time complexity:
![\[complexity = \dfrac{n^2}{4} + \dfrac{n^2}{8} + ...\]](/wp-content/ql-cache/quicklatex.com-e0a3d0480363f10384f620eb5fe60d37_l3.svg "Rendered by QuickLaTeX.com")
![\[complexity = \sum_{i=2}^{log(n)} \dfrac{n^2}{2^i}\]](/wp-content/ql-cache/quicklatex.com-3b44fc2cf0853b3cb44788541c24be60_l3.svg "Rendered by QuickLaTeX.com")
![\[complexity = \dfrac{n^2}{2}\]](/wp-content/ql-cache/quicklatex.com-32c1ac9d5abacd8da574ee9b9447d28c_l3.svg "Rendered by QuickLaTeX.com")
As a result, we can see that the overall time complexity is  , where is the size of the array.
, where is the size of the array.
4. Advanced In-Place Approach
We’ll start by explaining the theoretical idea behind the advanced approach. After that, we can implement the algorithm and provide an example to explain it.
4.1. Theoretical Idea
Since we don’t want to use any buffer arrays, we’ll need to use parts of the original array to merge sorted parts. To achieve this, the buffer array inside the original array must satisfy one of the following two conditions:
- The size of the two sorted parts must not exceed the size of the buffer area.
- The buffer area can overlap with one of the sorted parts. However, we must ensure that none of the unsorted elements gets overwritten.
Let’s say we want to sort the full array. We can recursively sort the right part of the array. We will end up with a case like the following:
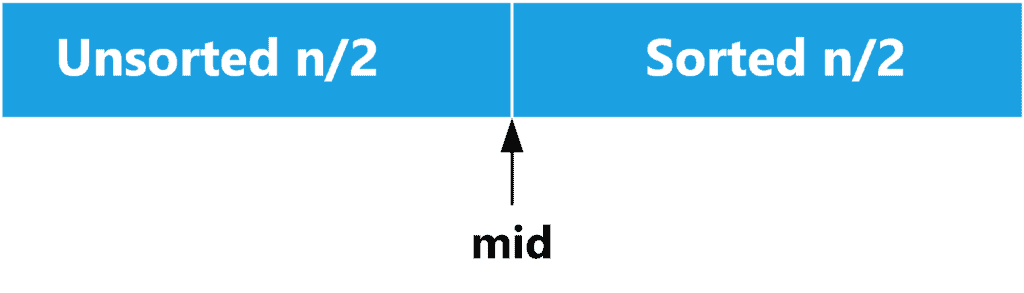
However, we can’t recursively sort the left part of the array because we will have two sorted parts and no buffer area to merge them. Nevertheless, we can divide the left part into two halves, and sort the first one recursively. After that, we come to the following scenario:
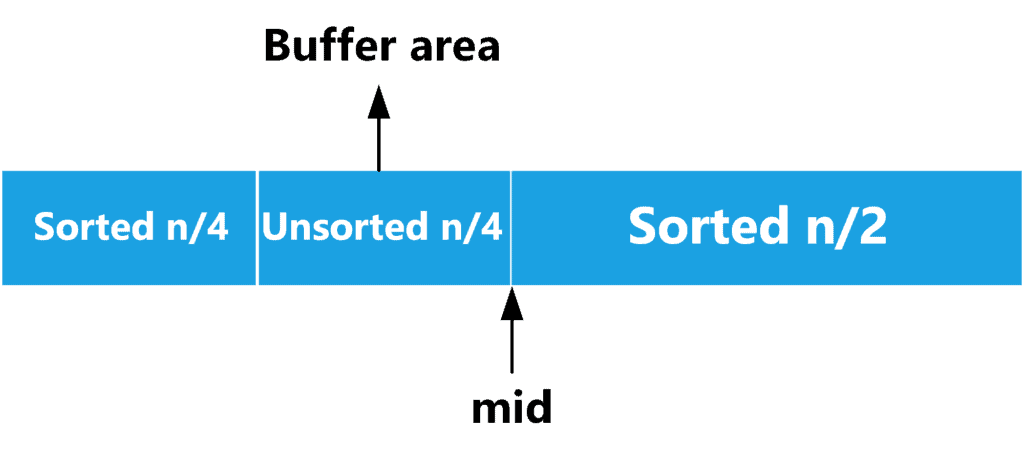
The idea here is that we want to merge the two sorted parts using the remaining unsorted part as the buffer area. The unsorted part forms one-quarter of the elements and, therefore, doesn’t satisfy the first condition for the buffer area.
However, let’s take a closer look at the merging process. If the element on the left-sorted part is smaller, then we can replace it with the element from the buffer area. Since the first sorted part also forms one-quarter of the elements, the elements should fit into the buffer area.
If the right sorted part is smaller, we will replace it with the element from the buffer area. However, this means the buffer area lost one place from its beginning and gained one new place at the end. Thus, its capacity remained untouched. Therefore, we can always ensure that no elements will be overwritten and end up with the following result:

Finally, following the same approach, we can keep reducing the buffer area size by half. If we reach the base case of two elements, we can use insertion sort, for example, to sort them.
Now, let’s implement the above-mentioned approach.
4.2. Merge Function
We’ll dive into the implementation step by step. First, let’s implement the merge function:
algorithm Merge(array, from1, to1, from2, to2, buffer):
// INPUT
// array = the original array containing two sorted parts
// from1 = the starting index of the first sorted part
// to1 = the ending index of the first sorted part
// from2 = the starting index of the second sorted part
// to2 = the ending index of the second sorted part
// buffer = the index where the merged result will be stored
// OUTPUT
// The merged array with elements sorted into the buffer area
while from1 <= to1 and from2 <= to2:
if array[from1] <= array[from2]:
swap(array[from1], buffer)
from1 <- from1 + 1
else:
swap(array[from2], buffer)
from2 <- from2 + 1
buffer <- buffer + 1
while from1 <= to1:
swap(array[from1], buffer)
from1 <- from1 + 1
buffer <- buffer + 1
while from2 <= to2:
swap(array[from2], buffer)
from2 <- from2 + 1
buffer <- buffer + 1We define the function  that takes the original array, the first range
that takes the original array, the first range ![[from1, to1]](/wp-content/ql-cache/quicklatex.com-94f9d1a8ad5906763f0005bc96922af2_l3.svg "Rendered by QuickLaTeX.com") , the second range
, the second range ![[from2, to2]](/wp-content/ql-cache/quicklatex.com-dc03a29e8e7e662384859b7b2df7a1de_l3.svg "Rendered by QuickLaTeX.com") , and the beginning of the buffer area. We keep comparing the first element from each range since it’s the smallest one. We move the smallest one to the buffer area and replace it with the element there. We also advance the corresponding pointers one step forward.
, and the beginning of the buffer area. We keep comparing the first element from each range since it’s the smallest one. We move the smallest one to the buffer area and replace it with the element there. We also advance the corresponding pointers one step forward.
When the loop breaks, it means only one of the two ranges ended. Therefore, we similarly copy the remaining part of the other range to the buffer area.
4.3. In-Place Merge Sort Implementation
After defining the merge function, we can now define the sort algorithm. Take a look at the implementation:
algorithm AdvancedInPlaceMergeSort(array, start, end, buffer):
// INPUT
// array = the array to sort
// start = the starting index of the subarray
// end = the ending index of the subarray
// buffer = the starting index of the buffer area
// OUTPUT
// The array sorted in place
if start >= end:
swap(array[start], array[buffer])
else:
mid <- (start + end) / 2
mergeSort(array, start, mid)
mergeSort(array, mid + 1, end)
merge(array, start, mid, mid + 1, end, buffer)
algorithm mergeSort(array, start, end):
// INPUT
// array = the array to sort
// start = the starting index of the subarray
// end = the ending index of the subarray
// OUTPUT
// The array sorted in place
if start < end:
mid <- (start + end + 1) / 2 - 1
buffer <- end - (mid - start)
AdvancedInPlaceMergeSort(array, start, mid, buffer)
L2 <- buffer
R2 <- end
L1 <- start
R1 <- L2 - 1
while R1 - L1 > 1:
mid <- (L1 + R1) / 2
len <- R1 - mid - 1
AdvancedInPlaceMergeSort(array, mid + 1, R1, mid + 1)
merge(array, L1, L1 + len - 1, L2, R2, R1 - len + 1)
R1 <- R1 - len
L2 <- R1 + 1
for i <- R1 to L1:
j <- i + 1
while j <= end and array[j - 1] > array[j]:
swap(array[j - 1], array[j])We define two functions. The first one is  which sorts the range
which sorts the range ![[from, end]](/wp-content/ql-cache/quicklatex.com-3a2334ee3c02e95d68cc2906dbdb4ef8_l3.svg "Rendered by QuickLaTeX.com") and writes the result to the buffer area starting at pointer
and writes the result to the buffer area starting at pointer  . We start with the base case. If we only have one element, we move that element to the buffer.
. We start with the base case. If we only have one element, we move that element to the buffer.
Otherwise, we divide the array in half, recursively sort each part using the  function, and then merge both parts into the buffer area using the function defined in section 4.3.
function, and then merge both parts into the buffer area using the function defined in section 4.3.
The second function is , the main function that sorts the array. We start by dividing the array in half, sorting the first part, and writing the result to the buffer area, which is the second part. Note that if the array’s length is odd, then we make sure to choose the so that the sorted part can fit into the buffer area.
Now, we’ve divided our array into a range ![[L_1, R_1]](/wp-content/ql-cache/quicklatex.com-4e9808ee0f0cb34e3faebff666c664ea_l3.svg "Rendered by QuickLaTeX.com") forming the unsorted part, and
forming the unsorted part, and ![[L_2, R_2]](/wp-content/ql-cache/quicklatex.com-1b3867e2f11ac0fb1e62f784d01789dd_l3.svg "Rendered by QuickLaTeX.com") forming the sorted part. Next, we’ll keep reducing the size of the unsorted part until it becomes very small that we can use insertion sort to merge it with the sorted part.
forming the sorted part. Next, we’ll keep reducing the size of the unsorted part until it becomes very small that we can use insertion sort to merge it with the sorted part.
Therefore, we’ll divide the unsorted part into two halves, sort the second part, and write the result in the first part. Note that we pay attention to defining the in a way that keeps the buffer area big enough to hold the sorted elements.
After that, we merge the sorted part at the beginning of the array with the sorted part at the end and write the result into the buffer area in the middle of the array, as explained in section 4.1. Once this is done, we’ll have the sorted part at the end of the array, while the unsorted part remains at the beginning. We keep repeating this process until the size of the unsorted part becomes two elements.
Finally, we perform insertion sort to place the remaining two elements at their correct location in the sorted part.
4.4. Time and Space Complexity
The additional space complexity is because we didn’t use any extra arrays. This approach is similar to the original merge sort approach regarding the time complexity. We only manipulate the location of the buffer area, which replaces the auxiliary array we used in the original approach.
The only difference is the insertion sort we perform at the end, which is  . However, this is done at each level of the recursion. In total, we have
. However, this is done at each level of the recursion. In total, we have  levels because we keep dividing the array in half. Therefore, its complexity is . This step is performed after the recursion. Thus, its complexity is added to the overall complexity.
levels because we keep dividing the array in half. Therefore, its complexity is . This step is performed after the recursion. Thus, its complexity is added to the overall complexity.
As a result, the overall time complexity is  .
.
4.5. Example
Let’s provide a step-by-step example of how the function works. Take a look at the following array:
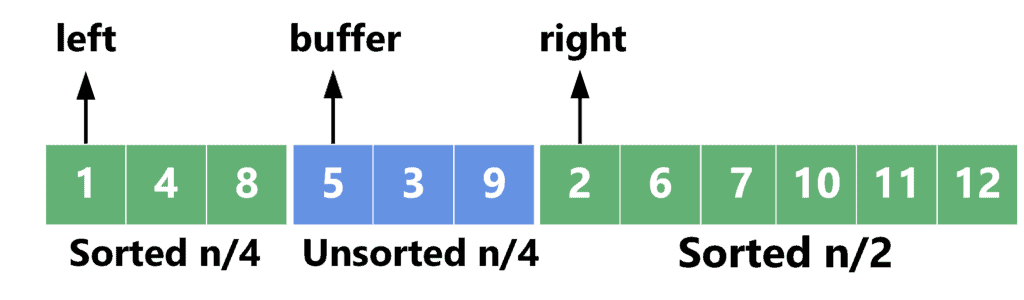
The first quarter is sorted, the second one is the buffer area, and the second half is sorted. We start by comparing the first element in each sorted part and moving the smallest to the buffer area. In this case, ![array[left] = 1](/wp-content/ql-cache/quicklatex.com-2a8083f13f0197b9eb097f774f38be92_l3.svg "Rendered by QuickLaTeX.com") is smaller than
is smaller than ![array[right] = 2](/wp-content/ql-cache/quicklatex.com-9b93ce17f62808f69218496939d59985_l3.svg "Rendered by QuickLaTeX.com") . Thus, we swap it with the first element in the buffer area:
. Thus, we swap it with the first element in the buffer area:
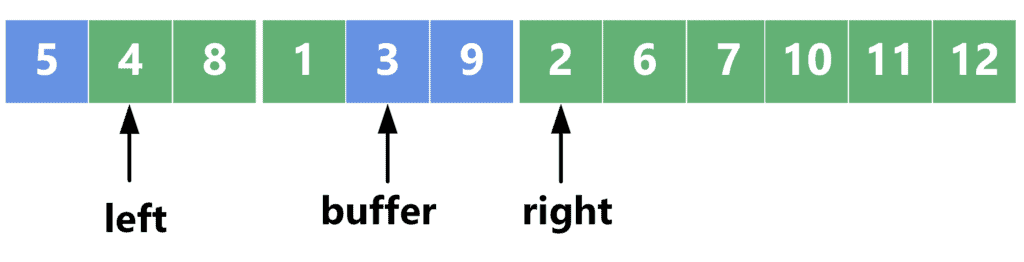
Next, we compare ![array[left] = 4](/wp-content/ql-cache/quicklatex.com-726ee0835cb8bcbd498154e2e7f6430b_l3.svg "Rendered by QuickLaTeX.com") with . Since the element on the right is smaller, we swap it with the next element in the buffer area:
with . Since the element on the right is smaller, we swap it with the next element in the buffer area:
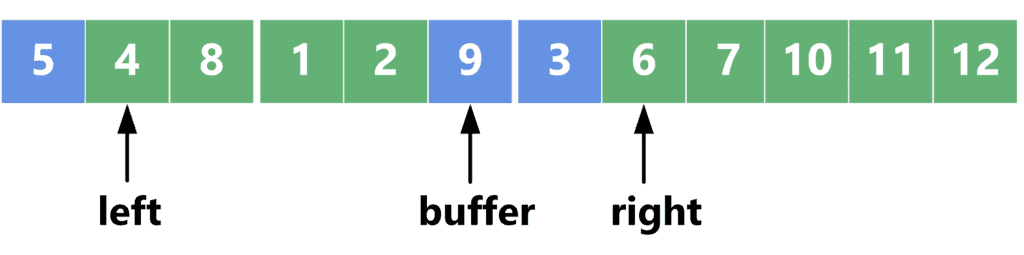
Note that element 3 from the buffer area seems to be added to the second sorted part. However, this is not correct. Actually, the right sorted part now starts at the position of the , while the buffer area contains  . We also have element
. We also have element  at the beginning of the array.
at the beginning of the array.
After the function ends, we’ll get the following array:

As we can see, the first quarter of the array contains unsorted elements in a different order than they originally appeared. This shouldn’t matter since they are unsorted anyways. The other part of the array now contains sorted elements.
5. Conclusion
In this tutorial, we discussed the in-place merge sort. We started with a quick reminder of how merge sort works, then presented two approaches to writing the in-place implementation. We also provided a step-by-step example of how the merge function works.