

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll show several ways to find the  smallest numbers in an array. We’ll also discuss those methods’ complexity and relative performance to one another.
smallest numbers in an array. We’ll also discuss those methods’ complexity and relative performance to one another.
All those techniques can be adapted to the converse problem of finding the largest numbers in an array.
2. Problem Description
Given an array  of
of  numbers, our goal is to find the
numbers, our goal is to find the  smallest elements and return them in the non-decreasing order.
smallest elements and return them in the non-decreasing order.
For example, if ![a = [1, 20, -30, 0, 11, 1, 503]](/wp-content/ql-cache/quicklatex.com-bad8b198cdbaccc06ada0cdf7529239c_l3.svg "Rendered by QuickLaTeX.com") and
and  , the solution is the array
, the solution is the array ![[-30, 0, 1]](/wp-content/ql-cache/quicklatex.com-ea55e87e1ad1c41c11615ccdb6624e28_l3.svg "Rendered by QuickLaTeX.com") because those are the three smallest numbers in
because those are the three smallest numbers in  .
.
When  , the problem reduces to finding the minimum of an array.
, the problem reduces to finding the minimum of an array.
3. Naïve Solutions
We can loop over the array times and find and remove the smallest number in each pass. This solution’s time complexity is  . It’s inefficient because it traverses the whole array repeatedly.
. It’s inefficient because it traverses the whole array repeatedly.
Another naïve solution is to sort the whole non-decreasingly and then take the first elements of the sorted array. The problem with this approach is that it sorts all the  elements even though we need only the smallest. This method’s complexity depends on the sorting algorithm but will be inefficient whenever is much smaller than . For instance, it doesn’t make sense to sort the whole array of
elements even though we need only the smallest. This method’s complexity depends on the sorting algorithm but will be inefficient whenever is much smaller than . For instance, it doesn’t make sense to sort the whole array of  numbers if we need only the five smallest.
numbers if we need only the five smallest.
4. The Solution Based on a Min-Heap
We can do better with a min-heap. Thought of as a binary tree, a min-heap has the property that each node is less than or equal to its children. So, the root node is the minimum of a min-heap.
Once we build a min-heap out of the array, we can pop its root to get the smallest element in it. Then, we process the rest of the heap to preserve the heap property and pop the new root to get the second smallest number.
Repeating the process times gives us the desired output:
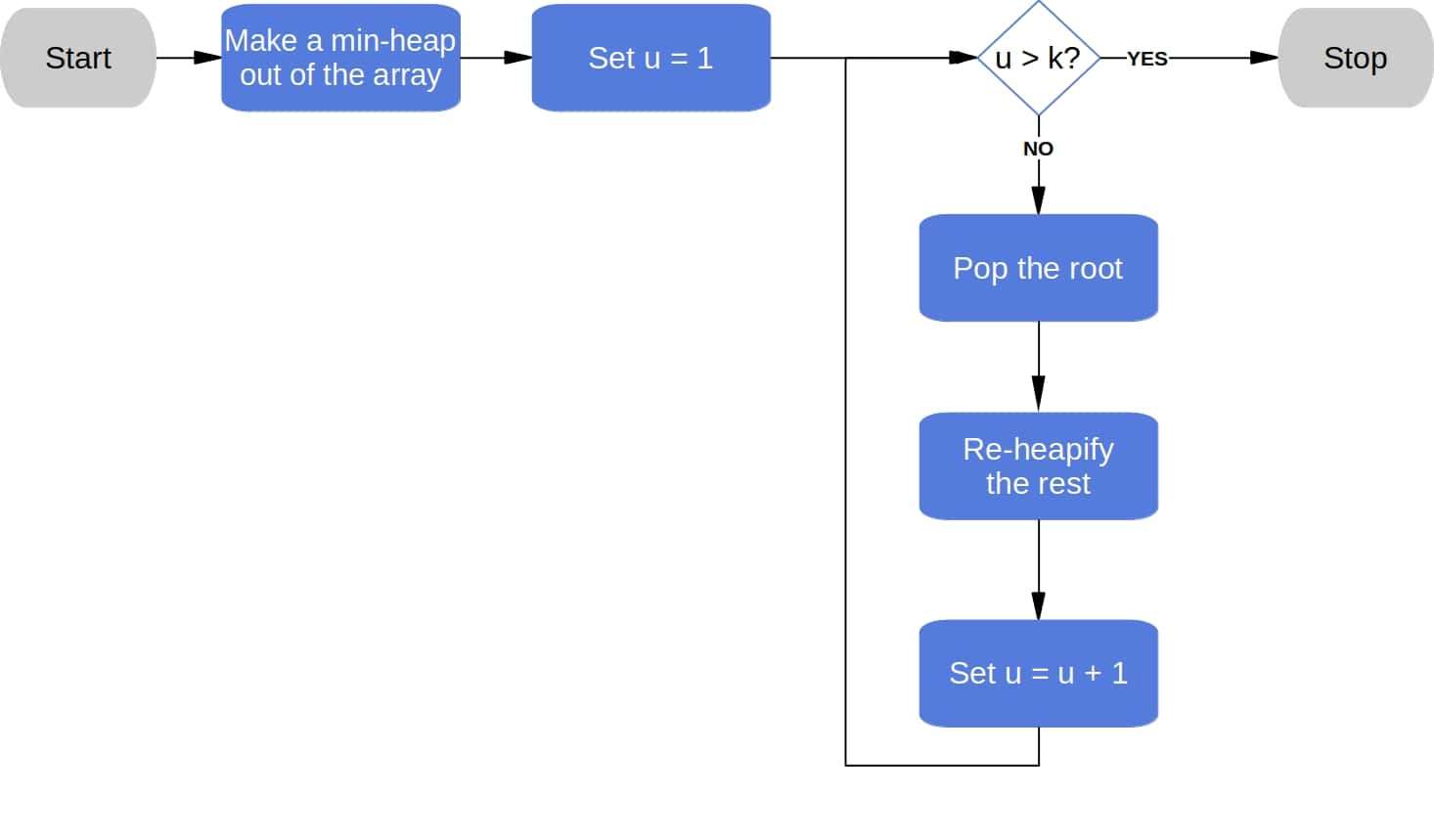
Using Floyd’s algorithm, we can build the heap in  time. Popping the root and heapifying the rest takes
time. Popping the root and heapifying the rest takes  time, so such steps can be done in
time, so such steps can be done in  time in total. Hence, the total complexity is:
time in total. Hence, the total complexity is:
![\[O(n+k \log n)\]](/wp-content/ql-cache/quicklatex.com-af536bae3e8520d395959b2fb8c9b24d_l3.svg "Rendered by QuickLaTeX.com")
If is a linear function of (for example,  when we look for the bottom
when we look for the bottom  ), then the complexity becomes
), then the complexity becomes
![\[O(n\log n)\]](/wp-content/ql-cache/quicklatex.com-911d3802b0e32014f43ece6902fbb799_l3.svg "Rendered by QuickLaTeX.com")
which is the lower bound of the complexity of sorting algorithms that use binary comparisons only.
5. The Solution Based on a Max-Heap
We can use a max-heap to solve the problem. A max-heap is like a min-heap, the only difference being that each max-heap’s node is greater than or equal to its children. So, the root of a max-heap contains its maximum.
In the beginning, we take the first elements of the unsorted array and put them into a max-heap. Then, we iterate over the remaining  elements and compare them to the root.
elements and compare them to the root.
If the current element (![\boldsymbol{a[i]}](/wp-content/ql-cache/quicklatex.com-0c7c3aa27609d5acf6969a5d76068630_l3.svg "Rendered by QuickLaTeX.com") ) is lower than the root, then we know that there are at least elements not greater than the root (
) is lower than the root, then we know that there are at least elements not greater than the root ( currently in our heap and the one with which we’ve just compared), so the root can’t be among the smallest numbers. Hence, we replace the root with
currently in our heap and the one with which we’ve just compared), so the root can’t be among the smallest numbers. Hence, we replace the root with ![a[i]](/wp-content/ql-cache/quicklatex.com-42e34b2b8788502423ed7c709a1494a6_l3.svg "Rendered by QuickLaTeX.com") , process the heap to preserve its property, and move to the next element in the array.
, process the heap to preserve its property, and move to the next element in the array.
Otherwise, if ![\boldsymbol{a[i}</strong><strong>]](/wp-content/ql-cache/quicklatex.com-9d7b2e4a9361d9a3500480b159c77736_l3.svg "Rendered by QuickLaTeX.com") is not lower than the root, we know that it’s greater than or equal to at least other numbers in the array, so it can’t be one of the smallest, and we can discard it:
is not lower than the root, we know that it’s greater than or equal to at least other numbers in the array, so it can’t be one of the smallest, and we can discard it:
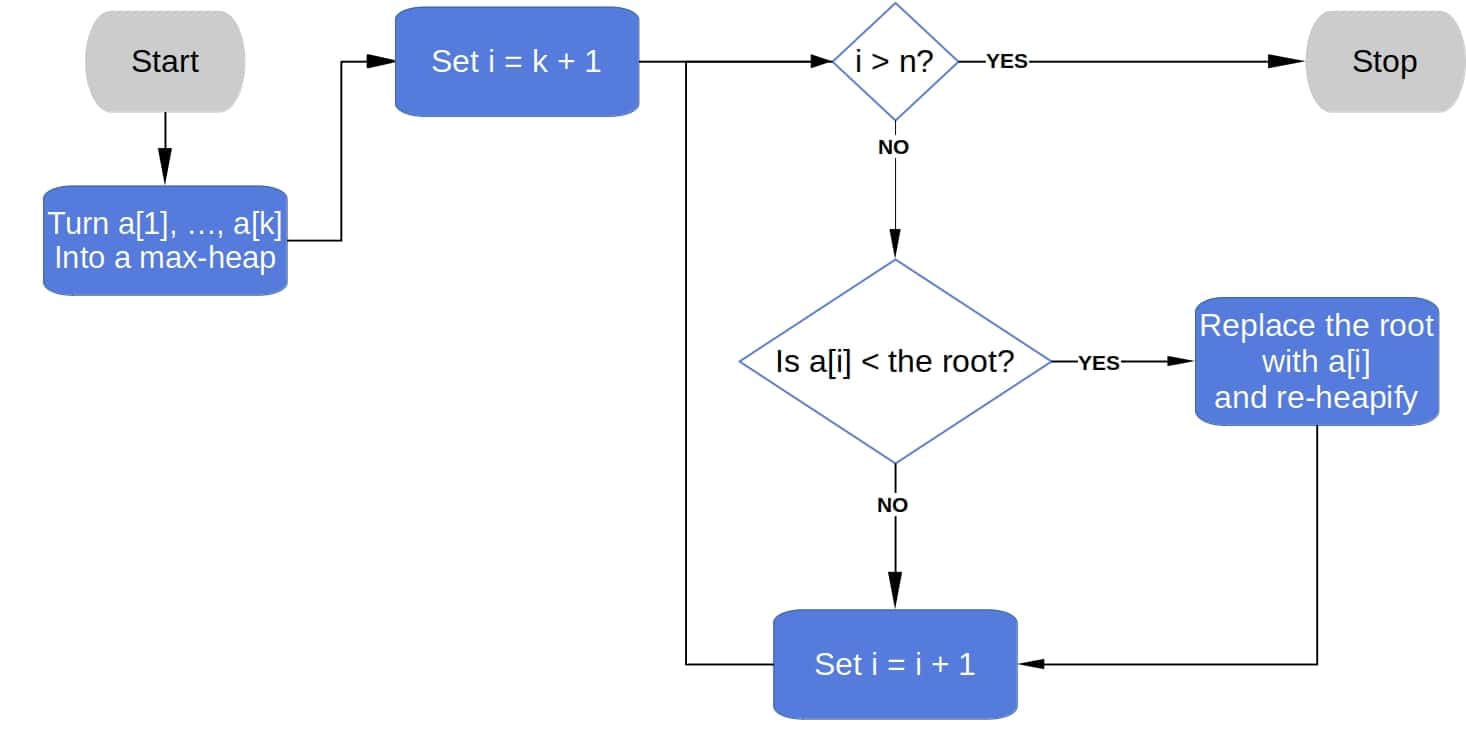
Using Floyd’s algorithm, we can construct the heap in  time. In the worst case, each of the elements initially out of the heap will be lower than the root, so we’ll perform the
time. In the worst case, each of the elements initially out of the heap will be lower than the root, so we’ll perform the  root replacement operation times. As a result, the worst-case complexity is
root replacement operation times. As a result, the worst-case complexity is
![\[O(k+(n-k)\log k)=O(n \log k)\]](/wp-content/ql-cache/quicklatex.com-c044b588738c05cbba4839ca3aeb7b87_l3.svg "Rendered by QuickLaTeX.com")
If is a linear function of , then the complexity is
6. QuickSelSort
This approach combines QuickSelect with QuickSort.
First, we use QuickSelect to find the -th smallest number. It will place it at the -th position in the input array and put the smaller numbers on positions  through but won’t sort them.
through but won’t sort them.
To sort those numbers from the smallest to the largest, we apply QuickSort to ![a[1], a[2], \ldots, a[k-1]](/wp-content/ql-cache/quicklatex.com-f67e0f27a4ed63cd660e0fe1c7401d8f_l3.svg "Rendered by QuickLaTeX.com") . We don’t need to process
. We don’t need to process ![a[k]](/wp-content/ql-cache/quicklatex.com-c83d00b4f0a4bcc5e2fabb31299ec9a8_l3.svg "Rendered by QuickLaTeX.com") with QuickSort because we already know it’s the -th smallest:
with QuickSort because we already know it’s the -th smallest:

Although the worst-case complexity of the approach is
![\[O(n^2)\]](/wp-content/ql-cache/quicklatex.com-eec50530648336ca50b70012b4e93832_l3.svg "Rendered by QuickLaTeX.com")
its average complexity is
![\[O(n+k\log k)\]](/wp-content/ql-cache/quicklatex.com-e6081b1e8e35a69e2fb426e48dc0e18b_l3.svg "Rendered by QuickLaTeX.com")
which is rather good. However, if is a linear function of , then the average complexity turns out to be  .
.
A notable advantage of QuickSelSort is that it uses two algorithms that are available in many libraries and tuned for performance, so we don’t have to implement it from scratch.
7. Partial QuickSort
Partial QuickSort is a modification of the usual QuickSort. The difference is that the former makes recursive calls only on the parts of the array that provably contain the smallest elements.
In the usual QuickSort, we get the subarray ![a[i:j]=a[i,2,\ldots,j]](/wp-content/ql-cache/quicklatex.com-0281994a6ff4a154f4b86faaa52a162c_l3.svg "Rendered by QuickLaTeX.com") , select a pivot and partition
, select a pivot and partition ![a[i:j]](/wp-content/ql-cache/quicklatex.com-95c12dcca8216adf91296ffafce72d8e_l3.svg "Rendered by QuickLaTeX.com") into two smaller subarrays
into two smaller subarrays ![a[i:(p-1)]](/wp-content/ql-cache/quicklatex.com-be39dc04f63297f6532dd771c2d8d619_l3.svg "Rendered by QuickLaTeX.com") and
and ![a[(p+1):j]](/wp-content/ql-cache/quicklatex.com-326603faa9895e9bc93ec709efd49525_l3.svg "Rendered by QuickLaTeX.com") . Since the goal of QuickSort is to sort the whole array, we must make two recursive calls: one for the left and the other for the right subarrays.
. Since the goal of QuickSort is to sort the whole array, we must make two recursive calls: one for the left and the other for the right subarrays.
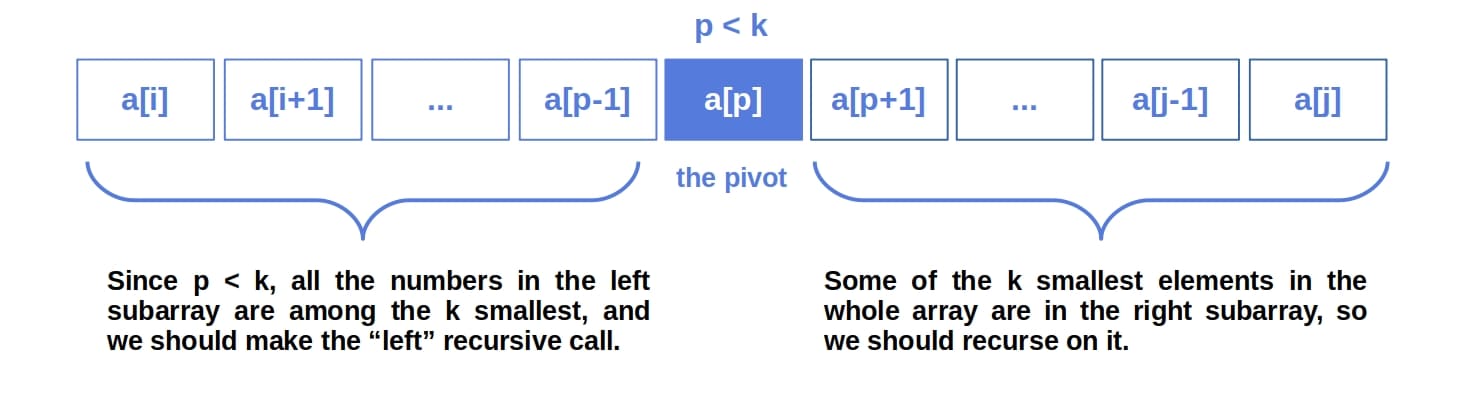
In contrast, Partial QuickSort doesn’t always sort the right subarray.
If  , then Partial QuickSort completely ignores the right subarray since none of the smallest numbers is in it. All the numbers we’re after are in the left subarray, so we make the recursive call only on .
, then Partial QuickSort completely ignores the right subarray since none of the smallest numbers is in it. All the numbers we’re after are in the left subarray, so we make the recursive call only on .
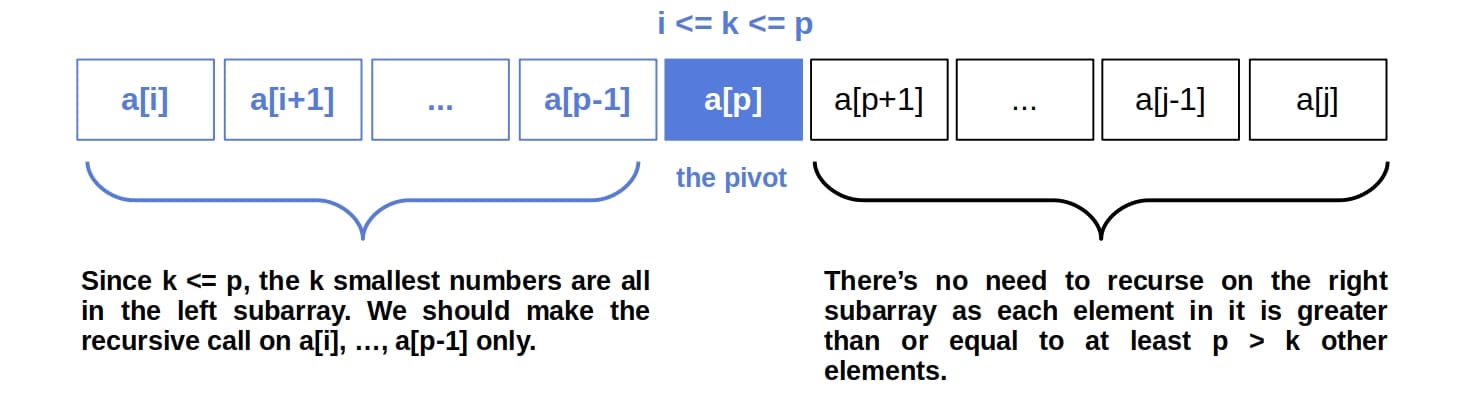
If  , then some of the sought numbers are in
, then some of the sought numbers are in ![a[(p+1):i]](/wp-content/ql-cache/quicklatex.com-5bfd699d89d117ac448f9a1654c53fb3_l3.svg "Rendered by QuickLaTeX.com") , so we have to make a recursive call on it as well:
, so we have to make a recursive call on it as well:
algorithm PartialQuickSort(a[i:j], k):
// INPUT
// a[i:j] = the subarray a[i], a[i+1], ..., a[j] of an n-element array a
// k = an integer (1 <= k <= n, 1 <= i <= j <= n)
// OUTPUT
// a is partially sorted so that a[i:k] contains the k-i+1 smallest numbers
// originally in a[i:j] if k > i.
// If k = i, the array is left unchanged. Recursive calls are made only if k ≥ i.
// In the very first call, i=1 and j=n.
if i < j:
p <- randomly select the index of the pivot element (p in {i, i+1, ..., j})
p <- partition a[i:j] and return the new index of the pivot element
PartialQuickSort(a[i:p-1], k)
if p + 1 <= k:
PartialQuickSort(a[p+1:j], k)
return aIf we select the pivot randomly, the worst-case complexity of Partial QuickSort will be  , and the expected complexity
, and the expected complexity  , just as it’s the case with QuickSelSort. However, partial QuickSort makes fewer comparisons on average.
, just as it’s the case with QuickSelSort. However, partial QuickSort makes fewer comparisons on average.
8. Partial QuickSort with Median of Medians
There’s a way to reduce the worst-case time complexity of Partial QuickSort to . We can achieve that by choosing the pivot element with an algorithm known as Median of Medians.
8.1. Median of Medians
The QuickSort and Partial QuickSelect algorithms show the best asymptotic performance if we reduce the array size by a constant factor before the recursive calls, as the size of the array to process will drop exponentially with the recursion depth.
The Median of Medians (MoM) is a pivot selection algorithm that does precisely so.
MoM returns an element between the bottom  and the top of the input array. Therefore, the returned pivot splits the input array in a ratio between
and the top of the input array. Therefore, the returned pivot splits the input array in a ratio between  and
and  . In the worst case, we reduce the size of the input by a factor of
. In the worst case, we reduce the size of the input by a factor of  . Since that’s a reduction by a known constant, the input size drops exponentially.
. Since that’s a reduction by a known constant, the input size drops exponentially.
8.2. Complexity Analysis
MoM runs in time. As Partial QuickSort does comparisons in each call, the overhead caused by MoM doesn’t change the asymptotic complexity of the call. However, the worst-case time complexity reduces to
That’s the average-case complexity of the generic version of Partial QuickSort.
9. Hybrid Partial QuickSort
Even though Partial QuickSort with MoM has an worst-case time complexity, it runs slower than the asymptotically inferior version of Partial QuickSort on most arrays in practice. MoM improves the worst-case complexity but makes the algorithm run slower on most inputs due to the additional overhead.
There’s a way to keep the practical efficiency and reduce the worst-case complexity at the same time. We draw inspiration from IntroSelect.
The idea is to start with the usual Partial QuickSort, which chooses pivots at random. We assume that the input at hand won’t cause the algorithm’s worst-case behavior and that it’s safe to use random selection. A good deal of time, we’ll be right. The average–case model will apply to most input arrays. However, if we notice that random selection results in inefficient partitioning, we fall back on MoM to avoid the worst-case and have it instead.
We can switch to MoM with two simple rules:
- We track the input array sizes in all the recursive calls. If any
 consecutive calls do not halve the input’s length, where is a constant set in advance, then we switch to MoM.
consecutive calls do not halve the input’s length, where is a constant set in advance, then we switch to MoM. - We track the sum of the input array sizes in recursive calls. If we notice that the sum in a call exceeds
 , where
, where  , then we switch to MoM.
, then we switch to MoM.
These rules limit the recursion depth to  ensuring that the worst-case complexity is . In addition, they’ll keep the algorithm efficient on most inputs. Let’s see how the second strategy works:
ensuring that the worst-case complexity is . In addition, they’ll keep the algorithm efficient on most inputs. Let’s see how the second strategy works:
algorithm HybridPartialQuickSort(a, i, j, k, m, S, selection):
// INPUT
// a = the n-element array
// i = start index of the subarray
// j = end index of the subarray
// k = an integer (1 <= k <= n, 1 <= i <= j <= n)
// m = a constant > 1
// S = the sum of sizes of the inputs to the previous calls in the recursion tree
// selection = the pivot selection strategy (Random by default)
// OUTPUT
// a is partially sorted so that a[i:k] contains the k-i+1 smallest numbers
// originally in a[i:j] if k > i.
// If k = i, the array is left unchanged.
// We make recursive calls only if k >= i. In the very first call, i=1 and j=n.
if i < j:
if selection = Random and S >= m * n:
selection <- MoM
if selection = Random:
p <- randomly select the index of the pivot element (p in {i, i+1, ..., j})
else:
p <- select the index of the pivot element using MoM
p <- partition a[i:j] and return the new index of the pivot element
HybridPartialQuickSort(a, i, p-1, k, m, S + (p-i), selection)
if p + 1 ≤ k:
HybridPartialQuickSort(a, p + 1, j, k, m, S + (j-p), selection)
return a10. Complexity Comparison
| Method | Time Complexity | |
|---|---|---|
| The Worst Case | The Average Case | |
| Min-Heap |  |
 |
| Max-Heap |  |
 |
| QuickSelSort | |
|
| Partial QuickSort | |
|
| Partial QuickSort with MoM | |
|
| Hybrid Partial QuickSort |  |
 |
We see that all the methods based on QuickSort and QuickSelect have the same average–case time complexity of . However, QuickSelSort and Partial QuickSort have an worst-case time complexity. Though asymptotically equivalent, the latter is more efficient in practice.
If we use MoM to choose the pivot in Partial QuickSort, we reduce the worst-case complexity to , but end up with an inefficient algorithm because of the overhead caused by MoM. Hybrid Partial QuickSort has the same asymptotic complexity as Partial QuickSort with MoM. But, it’s faster in practice because it uses MoM only when random selection results in inefficient partitioning.
Heaps offer interesting alternatives. However, their performance in practice depends on how much is larger than .
If is a linear function of , all the approaches become log-linear in in the average case. Partial QuickSort with MoM, Hybrid Partial QuickSort, and the heap-based solutions become in the worst case as well.
11. Other Approaches
Instead of QuickSort, we can adapt other sorting algorithms, such as MergeSort.
We can also base our solutions on the Floyd–Rivest selection algorithm. It finds the -th smallest element in an array just as QuickSelect but is faster on average.
12. Conclusion
In this tutorial, we showed several ways to find the smallest numbers in an array. We based most of our solutions on QuickSort but also presented two heap-inspired approaches and mentioned other algorithms that we can adapt to solve the problem.