

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll discuss image recognition based on one-shot learning. We’ll talk about the problems with other approaches that one-shot learning solves and present how it works.
2. What Do We Use One-Short Learning For?
Image recognition is a sub-field of computer vision. It’s a set of technologies for identifying, analyzing, and interpreting images.
It uses neural networks trained on a labeled dataset. One of the main problems with image-recognition algorithms is that we usually don’t have many annotated images for training our neural networks.
For example, that’s the case with facial-recognition systems at international airports. We need multiple images of anyone who might pass through that airport, which can add up to billions. Aside from the fact that collecting such a dataset is next to impossible, a database of faces would be a nightmare from a legal perspective.
3. One-Shot Learning
One-shot learning comes to solve this problem as a classification problem by transforming it into a difference and similarity evaluation problem.
It’s based on a unique type of convolutional neural networks (CNNs), called Siamese Neural Networks (SNNs).
To use a larger dataset, we form pairs of the original input images. We set the new target variable to 1 if the images in the pair belong to the same class or 0 if they don’t. Then, we train our model on the new dataset that is bigger than the initial one.
3.1. Siamese Neural Networks (SNNs)
During training, a traditional CNN modifies its parameters to accurately classify each image. SNN is a method used to deal with one-shot learning. It compares a learned characteristic vector for the known and candidate examples.
We train a Siamese network to measure the separation between features in two input photos:
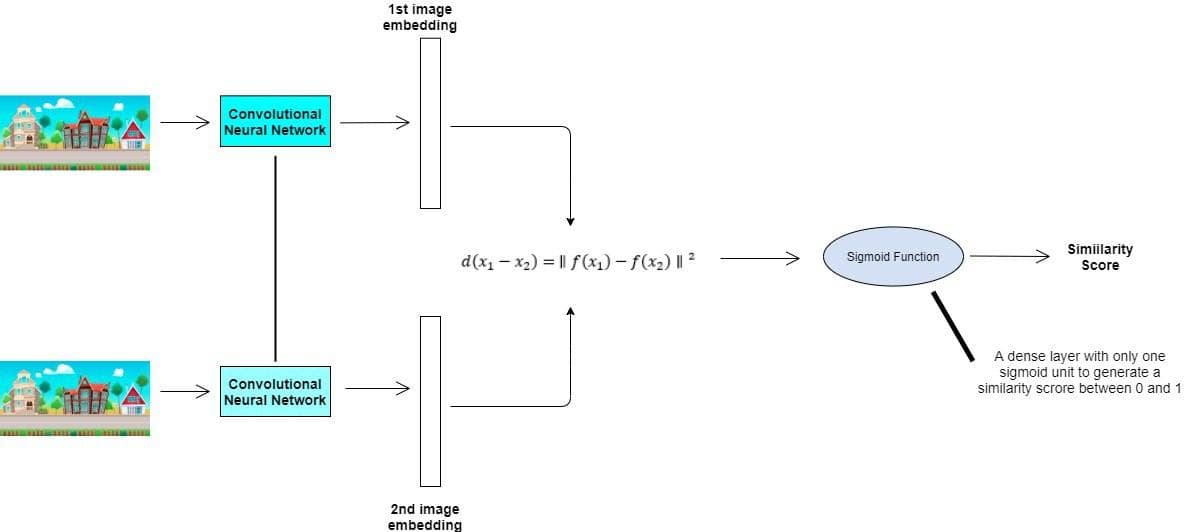
In the image above, the two CNNs are two copies of the same network. They have the same parameters and are called Siamese Networks.
Let’s say we feed them two input images  and
and  . They process and and output fixed-length characteristics vectors
. They process and and output fixed-length characteristics vectors  and
and  .
.
The underlying assumption is that if and are similar, so will and be.
3.2. Loss Functions
Siamese networks often use similarity scores produced by comparison functions.
The triplet loss is a common choice. In the triplet-loss function, we have three arguments. Those are the negative, the positive, and the anchor:
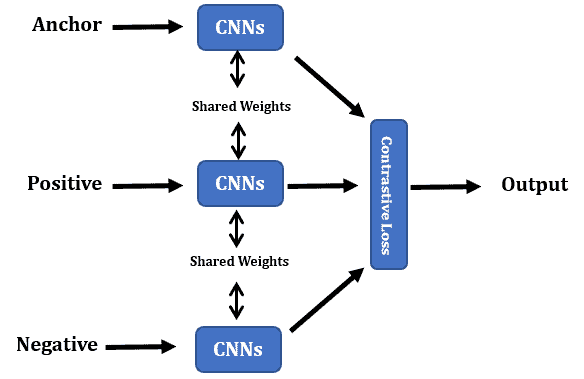
The goal is to minimize the distance between the anchor and the positive object and maximize the one between the anchor and the negative embedding:
![\[\sum_i^b[||f(x_a^i)-f(x_p^i)||_2^2 - ||f(x_a^i)-f(x_n^i)||_2^2 + \alpha]_+\]](/wp-content/ql-cache/quicklatex.com-db2dc1ee06ce62ea92a30968f626435f_l3.svg "Rendered by QuickLaTeX.com")
 is the mini-batch size,
is the mini-batch size,  is the
is the  triplet in the mini-batch (in which
triplet in the mini-batch (in which  is the anchor,
is the anchor,  is the negative, and
is the negative, and  is the positive object),
is the positive object), ![[z]_+:=max(z,0)](/wp-content/ql-cache/quicklatex.com-2244c7a6dcb434b2585312510b6b4b3f_l3.svg "Rendered by QuickLaTeX.com") , and
, and  denotes the
denotes the  norm.
norm.  is the model’s output.
is the model’s output.
The contrastive loss operates with pairs of samples (the anchor and the positive or the anchor and the negative):
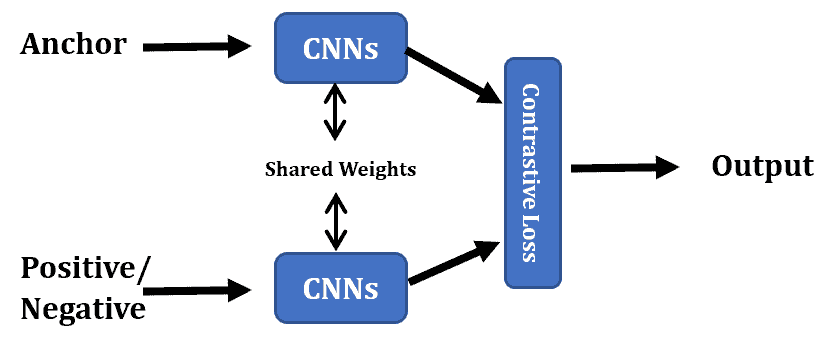
If the samples are the anchor and the positive object, the loss should be minimized, and vice versa. In other words, the contrastive loss works like the triplet loss, but sequentially rather than simultaneously:
![\[\sum_i^b[(1-y_i)||f(x_1^i)-f(x_2^i)||_2^2 +y [-||f(x_1^i)-f(x_2^i)||_2^2 + \alpha]_+]\]](/wp-content/ql-cache/quicklatex.com-7343e6751b41e4cd8e1a1d31b777afc2_l3.svg "Rendered by QuickLaTeX.com")
The variable  is zero if the pair
is zero if the pair  is (anchor, positive) and 1 if it’s (anchor, negative).
is (anchor, positive) and 1 if it’s (anchor, negative).
3.3. Implementation of One-Shot Learning
One-shot learning has five steps:
First, we need to collect and load the images into tensors. Later, we’ll use these tensors to feed the model in batches.
After loading data, we should map the problem into the binary classification task. We do this by creating data image pairs and target variables.
One-shot models follow the SNN architecture. We train, validate, and test them in the same way as we do with other machine-learning models.
4. Applications of One-Shot Learning
One-shot learning is useful for computer vision, especially for self-driving cars and drones to detect objects in the environment.
It’s also essential in tasks where we have several classes but fewer examples of each class, such as face recognition and signature verification.
In addition to airport control, law enforcement agencies can use facial recognition based on one-shot learning to hunt down terrorists in crowded places. Based on input from security cameras, one-shot learning can identify people in crowds.
One-shot learning also has applications in health care, IoT, mathematics, material science, and so on.
5. Benefits and Challenges of One-Shot Learning
The one-shot learning algorithm’s main benefit is that it classifies images based on how similar they are rather than by examining their many different aspects. With less time and cost spent on computation, the model can be trained faster.
On the other hand, one-shot learning is very prone to variations in images. For instance, if the person has a hat, sunglasses, scarf, or any other accessory that can obscure their face, the accuracy of image detection may suffer dramatically.
6. Conclusion
In this article, we talked about one-shot learning. It’s an excellent method for image recognition when we have fewer input data.
It uses Siamese networks, which can employ triplet or contrastive loss functions.