

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: February 28, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In some machine learning applications, we’re interested in defining a sequence of steps to solve our problem. Let’s consider the example of a robot trying to find the maze exit with several obstacles and walls.
The focus of our model should be how to classify a whole sequence of actions from the initial state that brings the robot to the desired state outside of the maze.
In Machine Learning, this type of problem is usually addressed by the Reinforcement Learning (RL) subfield that takes advantage of the Markov decision process to model part of its architecture. One of the challenges of RL is to find an optimal policy to solve our task.
In this tutorial, we’ll focus on the basics of Markov Models to finally explain why it makes sense to use an algorithm called Value Iteration to find this optimal solution.
To model the dependency that exists between our samples, we use Markov Models. In this case, the input of our model will be sequences of actions that are generated by a parametric random process.
In this article, our notation will consider that a system with  possible states
possible states  will be at a time
will be at a time  in a state
in a state  . So, the equality
. So, the equality  indicates that at the time
indicates that at the time  , the system will be at the state
, the system will be at the state  .
.
We should highlight that the subscript  is referred to as time, but it could be other dimensions, such as space.
is referred to as time, but it could be other dimensions, such as space.
But how can we put together the relationship between all possible states in our system? The answer is to apply the Markov Modelling strategy.
If we are at a state  at the time , we can go to state
at the time , we can go to state  at the time
at the time  with a given or calculated probability that depends on previous states:
with a given or calculated probability that depends on previous states:
(1) 
To make our model slightly simpler, we can consider that only the immediately previous state influences the next state instead of all preceding states. Only the current state is relevant to define the future state, and we have a first-order Markov model:
(2) 
To simplify our model a little more we remove the time dependency and we define that from a state we’ll go to a state by the means of a transition probability:
(3) 
One of the easiest ways for us to understand these concepts is to visualize a Markov Model with two states connected by four transitions:
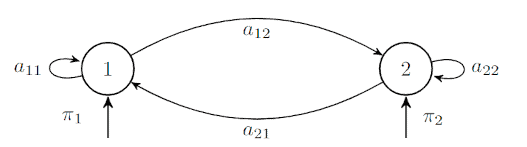
The variable  represents the probability of starting at state
represents the probability of starting at state  . As we removed the time dependency from our model, at any moment, the transition probability of going from state
. As we removed the time dependency from our model, at any moment, the transition probability of going from state  to
to  will be equal to
will be equal to  regardless of the value of .
regardless of the value of .
Moreover, the transition probabilities for a given state should satisfy one condition:
(4) 
For the case we have an equivalent condition, since the sum of all possible initial states should be equal to  :
:
(5) 
Lastly, if we know all states , our output will be the sequence of the states from an initial to a final state, and we’ll call this sequence observation sequence  . The probability of a sequence can be calculated:
. The probability of a sequence can be calculated:
(6) 
In which  represents the sum of initial probabilities and
represents the sum of initial probabilities and  is the vector of transition probabilities.
is the vector of transition probabilities.  represents the probability of start at state
represents the probability of start at state  . While
. While  represents the probability of reach state
represents the probability of reach state  from .
from .
To illustrate all this theory, let’s consider  and
and  with defined values for the transition probabilities:
with defined values for the transition probabilities:
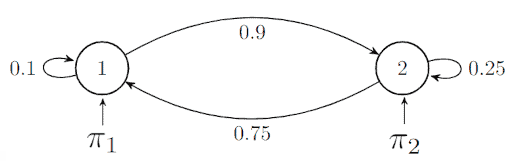
We’ll consider the observation sequence  . The probability of this sequence can be calculated:
. The probability of this sequence can be calculated:
(7) 
After we replace the defined values:
(8) 
In the previous example, all states were known, so we call them observable. When the states are not observable, we have a hidden Markov model (HMM).
To define the probabilities of a state, we first need to visit this state and then write down the probability of the observation. We consider a good HMM model one that correctly uses real-world data to create a model to simulate the source.
It is crucial that we remember that in this type of model, we have two sources of randomness: the observation in a state and the movement from one state to another.
We usually have two main problems in HMM:
 , we’re interested in calculating the probability
, we’re interested in calculating the probability  , which means the probability of any observation sequence
, which means the probability of any observation sequence As we stated in the introduction of this article, some problems in Machine Learning should have as a solution a sequence of actions instead of a numeric value or label.
In Reinforcement Learning, we have an agency responsible for the decision-making to select an action in an environment.
At any given state, the agent will take an action, and the environment will return a reward or penalty. A sequence of actions is called policy, and the primary goal of an RL problem is to find the optimal policy to maximize the total reward.
If we return to the initial example of a robot trying to find the exit of a maze, the robot would be the learner agent, and the environment would be the labyrinth:
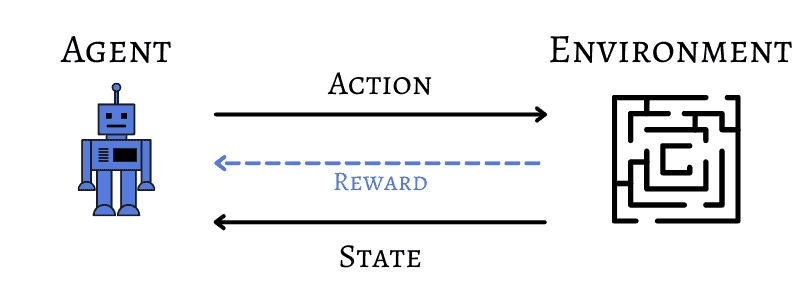
From this point, we can make an analogy with the Markov model since the solution for this problem is a sequence of actions.
A Markov Decision Process is used to model the agent, considering that the agent itself generates a series of actions. In the real world, we can have observable, hidden, or partially observed states, depending on the application.
In our explanation, we’ll consider that the agent will be at a state  in a given discrete-time . The variable
in a given discrete-time . The variable  will represent all the possible states. The available actions will be represented as
will represent all the possible states. The available actions will be represented as  , and after an action is taken and the agent goes from to
, and after an action is taken and the agent goes from to  a reward
a reward  is computed.
is computed.
As we defined before, we have here a first-order Markov model since the next state and reward depend only on the current state and action.
From now on, we’ll consider that the policy  defines the mapping of states to actions
defines the mapping of states to actions  . So, if we’re at a state , the policy will indicate the action to be taken.
. So, if we’re at a state , the policy will indicate the action to be taken.
The value of a policy referred to as  is the expected value after all the rewards of a policy are summed starting from . If we put into our mathematical model:
is the expected value after all the rewards of a policy are summed starting from . If we put into our mathematical model:
(9) ![\begin{equation*} V^{\pi}(s_{t})= E[r_{t+1}+r_{t+2}+ \ldots + r_{t+T}]= E\left[ \sum_{i=1}^{T} r_{t+1} \right] \end{equation*}](/wp-content/ql-cache/quicklatex.com-5a81cf626122ca84e83be34a9dad59da_l3.svg "Rendered by QuickLaTeX.com")
We should highlight that the above equation only works when we have a defined number of steps  to take. In case we don’t have this value, we have an infinite-horizon model that will penalize future rewards by means of a discount rate
to take. In case we don’t have this value, we have an infinite-horizon model that will penalize future rewards by means of a discount rate  :
:
(10) ![\begin{equation*} V^{\pi}(s_{t})= E[r_{t+1}+\gammar_{t+2}+ \gamma^{2}r_{t+3} + \ldots = E\left[ \sum_{i=1}^{\infty} \gamma^{i-1}r_{t+i} \right] \end{equation*}](/wp-content/ql-cache/quicklatex.com-3aef3c4c0c0206a6bfcffe9561ce2793_l3.svg "Rendered by QuickLaTeX.com")
Our main goal is to find the optimal policy  that will lead our cumulative reward to its maximum value:
that will lead our cumulative reward to its maximum value:
(11) 
We can also use a pair of state and action to indicate the impact of taking action  being at the state . We leave the use of
being at the state . We leave the use of  to simply indicate the performance of being at state .
to simply indicate the performance of being at state .
We start from the knowledge that the value of a state is equal to the value of the best possible action:
(12) 
(13) ![\begin{equation*} V^{*}(s_{t}) = max \left( E[r_{t+1}]+\gamma \sum_{s_{t+1}}^{} P(s_{t+1}|s_{t},a_{t})V^{*}(s_{t+1}) \right) \end{equation*}](/wp-content/ql-cache/quicklatex.com-d843841d8a3510078ab21cab45136fcb_l3.svg "Rendered by QuickLaTeX.com")
This represents the expected cumulative reward  considering that we move with probability
considering that we move with probability  .
.
If we use the state-action pair notation, we have:
(14) ![\begin{equation*} Q^{*}(s_{t},a_{t})=E[r_{t+1}]+ \gamma \sum_{s_{t+1}} P(s_{t+1}|s_{t},a_{t}) max \: Q^{*}(s_{t+1},a_{t+1}) \end{equation*}](/wp-content/ql-cache/quicklatex.com-dc4fc4b71d77b737583fac1e100ffcb2_l3.svg "Rendered by QuickLaTeX.com")
Finally, to find our optimal policy for a given scenario, we can use the previously defined value function and an algorithm called value iteration, which is an algorithm that guarantees the convergence of the model.
The algorithm is iterative, and it will continue to execute until the maximum difference between two consecutive iterations  , and
, and  is less than a threshold
is less than a threshold  :
:
Now we’ll see a simple example of the value iteration algorithm simulating an environment.
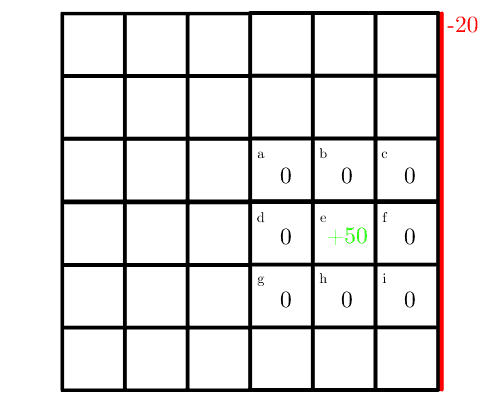
Our full map is a  grid, but for the sake of simplicity, we’ll consider a small part of the maze consisting of a
grid, but for the sake of simplicity, we’ll consider a small part of the maze consisting of a  grid with a reward of
grid with a reward of  in the center with their values initialized to zero.
in the center with their values initialized to zero.
Our robot can only take four actions: move up, down, left or right, and if it hits the wall to the right, it receives a penalty of  :
:
As we’re simulating a stochastic model, there are probabilities associated with the actions. In this case, there is a  chance of the robot actually going in the defined direction and a
chance of the robot actually going in the defined direction and a  chance for the other three options of movement.
chance for the other three options of movement.
So if the agent decides to go top, there is a 70% chance of going top and a 10% chance of going down, right or left, each. The robot only gets the reward when the action is completed, not during the transition.
In the first iteration, each cell receives its immediate reward. As the optimal for the cell  is going down with a probability of hitting the wall, we can calculate the immediate reward as
is going down with a probability of hitting the wall, we can calculate the immediate reward as  , and the map becomes:
, and the map becomes:
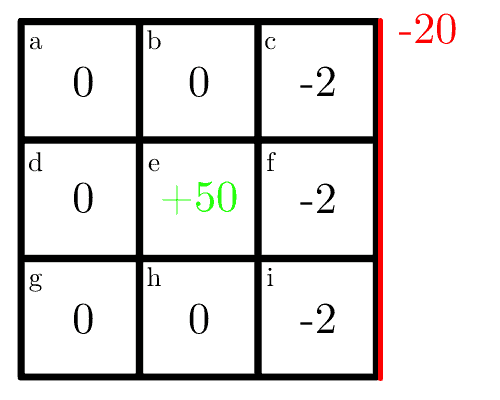
For the next steps, we’ll use a discount rate  . For the second iteration, we’ll consider first the cell
. For the second iteration, we’ll consider first the cell  , and we’ll calculate the value of going taking the optimal action, which is going left:
, and we’ll calculate the value of going taking the optimal action, which is going left:
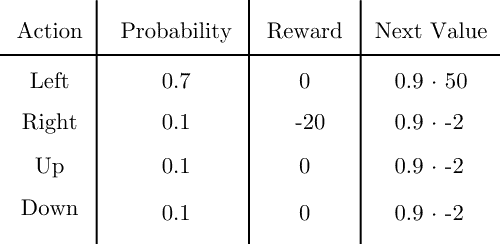
The state value will be the sum of the reward and the next value multiplied by the probability for all actions:
(15) 
Similarly, to cell  we observe that the optimal action is to go right and all other directions give a expected reward of zero, so the state value is simply:
we observe that the optimal action is to go right and all other directions give a expected reward of zero, so the state value is simply:
(16) 
After we calculate for all cells, the map becomes:
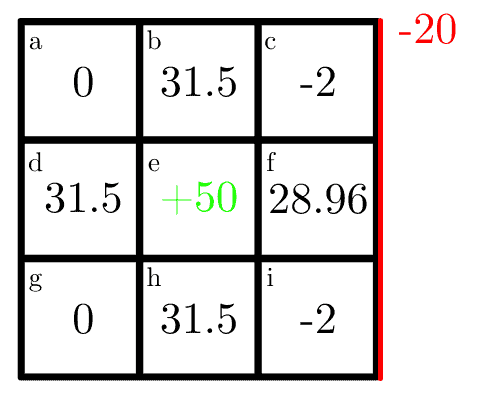
We only conducted two iterations, but the algorithm continues until the desired number of iterations of the threshold is achieved.
In this article, we discussed how we could implement a dynamic programming algorithm to find the optimal policy of an RL problem, namely the value iteration strategy.
This is an extremely relevant topic to be addressed since the task of maximizing the reward in this type of model is the core of real-world applications. Since this algorithm is guaranteed to find the optimal values and to converge, it should be considered when implementing our solution.
