

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about downstream tasks in machine learning.
A downstream task depends on the output of a previous task or process. It involves applying the pre-trained model‘s knowledge to a new problem. The output of the previous task serves as input to the downstream task, and the model can only perform the downstream task once completing the previous one.
The idea of pre-training models on upstream tasks and fine-tuning on downstream tasks is also known as transfer learning. The goal of transfer learning is to use the information gained from pre-training a model on a large dataset to enhance the performance of the same or a related model on a different, more specific job or a smaller dataset:
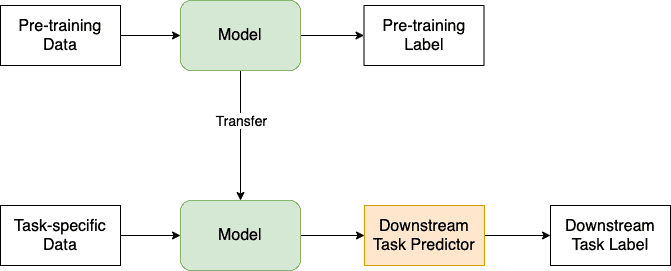
Downstream tasks allow us to use pre-trained models for various applications. By fine-tuning the models on specific downstream tasks, we can improve their performance and make them more useful for other real-world applications.
A benefit of this approach is that we don’t need to construct new models from scratch. Instead, we can adjust the existing quality models. That produces leading results on many tasks.
In the fine-tuning process, we first use the parameters of the pre-trained model as the initial values. Then, we adjust the parameter based on the gradient of the error to optimize the model’s performance on the new task. Once the model has been fine-tuned, we can use it to make predictions or perform other tasks related to the downstream task:

In neural networks, we can apply backpropagation to update the weights/parameters in the networks.
We adapt the general knowledge learned during pre-training to solve specific tasks by fine-tuning the pre-trained model or using its outputs as input.
For example, in the case of large language models like GPT and BERT, we first train our model on large amounts of general text data to learn the language. Then, we fine-tune the model to perform specific downstream tasks:
In image classification, a pre-trained convolutional neural network (CNN) can be used as a feature extractor to extract features from input images. Then, we use these features in downstream tasks to:
Transfer learning can be computationally expensive, particularly if the target dataset or the pre-trained model is large and complex.
Additionally, transfer learning works best when the source and target activities are similar or overlap in some way. This is intuitive since we don’t expect a model trained to recognize objects in an image to be easily adapted to handle textual data. So, transfer learning might not work well if the pre-trained and downstream tasks are dissimilar.
In this article, we explain downstream tasks in machine learning.
A downstream task is a task that depends on the output of a previous task or process. This idea is based on transfer learning, which allows us to use pre-trained models to improve performance on specific tasks. By fine-tuning the models on the downstream tasks, we can make the models more effective for real-world applications.