Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: May 23, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Dijkstra’s algorithm is used to find the shortest path from a starting node to a target node in a weighted graph. The algorithm exists in many variations, which were originally used to find the shortest path between two given nodes. Now they’re more commonly used to find the shortest path from the source to all other nodes in the graph, producing a shortest path tree.
In this tutorial, we’ll learn the concept of Dijkstra’s algorithm to understand how it works. At the end of this tutorial, we’ll calculate the time complexity and compare the running time between different implementations.
2. The Algorithm
The algorithm, published in 1959 and named after its creator, Dutch computer scientist Edsger Dijkstra, can be applied to a weighted graph. The algorithm finds the shortest path tree from a single source node by building a set of nodes with minimum distances from the source.
It’s important to note the following points:
Dijkstra’s algorithm makes use of breadth-first search (BFS) to solve a single source problem. However, unlike the original BFS, it uses a priority queue instead of a normal first-in-first-out queue. Each item’s priority is the cost of reaching it from the source.
Before going into the algorithm, let’s briefly review some important definitions.
The graph has the following:
 or
or  , ) denotes an edge, and
, ) denotes an edge, and  denotes its weight
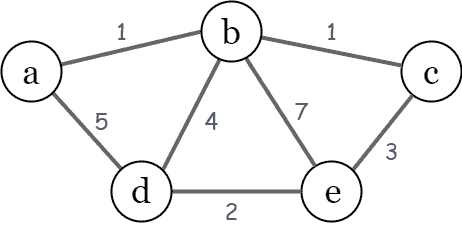
denotes its weightThe following example illustrates an undirected graph with the weight for each edge:
To implement Dijkstra’s algorithm, we need to initialize three values:
 – an array of the minimum distances from the source node
– an array of the minimum distances from the source node  to each node in the graph. At the beginning,
to each node in the graph. At the beginning,  , and for all other nodes ,
, and for all other nodes ,  . The array will be recalculated and finalized when the shortest distance to every node is found.
. The array will be recalculated and finalized when the shortest distance to every node is found. – a priority queue of all nodes in the graph. At the end of the progress, will be empty.
– a priority queue of all nodes in the graph. At the end of the progress, will be empty. – a set to indicate which nodes have been visited by the algorithm. At the end of the progress, will contain all the nodes of the graph.
– a set to indicate which nodes have been visited by the algorithm. At the end of the progress, will contain all the nodes of the graph.The algorithm proceeds as follows:
with the smallest  from . In the first run, source node will be chosen because in the initialization. to , to indicate that has been visited. values for each adjacent node of the current node as follow: (1) if
from . In the first run, source node will be chosen because in the initialization. to , to indicate that has been visited. values for each adjacent node of the current node as follow: (1) if  , so update
, so update  to the new minimal distance value, (2) otherwise no updates are made to the . is empty, or in other words, when contains all nodes, which means every node has been visited.
to the new minimal distance value, (2) otherwise no updates are made to the . is empty, or in other words, when contains all nodes, which means every node has been visited.Let’s go through an example before coding it with the pseudocodes.
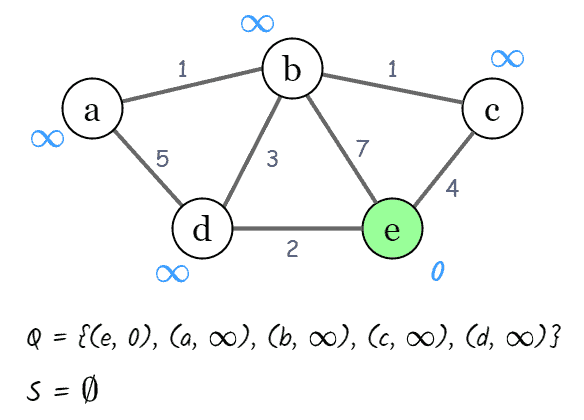
Given the following undirected graph, we’ll calculate the shortest path between the source node  and the other nodes in our graph. To begin, we mark
and the other nodes in our graph. To begin, we mark  ; for the rest of the nodes, the value will be
; for the rest of the nodes, the value will be  as we haven’t visited them yet:
as we haven’t visited them yet:
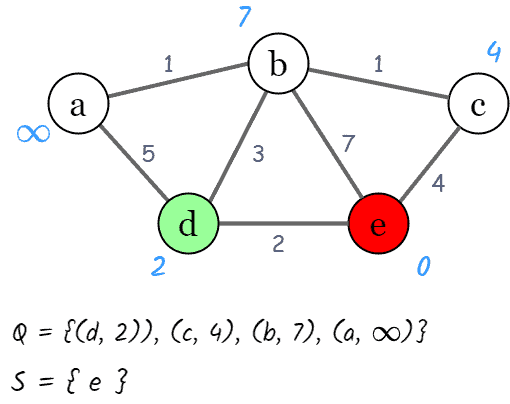
At this step, we pop a node with the minimal distance (i.e., node ) from as the current node, and mark the node as visited (add node to ). Next, we check the neighbors of our current node ( ,
,  , and
, and  ) in no specific order.
) in no specific order.
At the node , we have  , so we update
, so we update  . Similarly, we update
. Similarly, we update  and
and  . In addition, we update the priority queue after recalculating the distances of these nodes:
. In addition, we update the priority queue after recalculating the distances of these nodes:
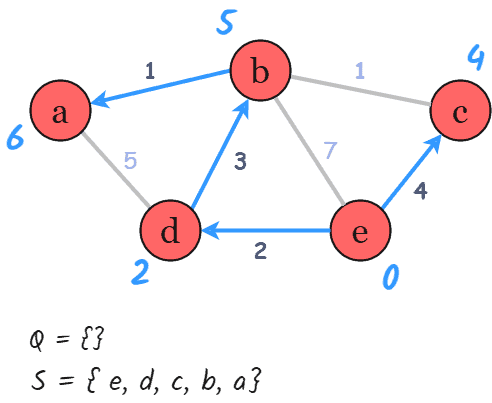
Now we need to pick a new current node by popping from the priority queue . That node will be un-visited with the smallest minimum distance. In this case, the new current node is with . Then we repeat adjacent node distance calculations.
After repeating these steps until is empty, we reach the final result of the shortest-path tree:
The following pseudocode shows the details of Dijkstra’s algorithm:
algorithm Dijkstra(G, source):
// INPUT
// G = the input graph (G = (V, E))
// source = the source node
// Initialization
for v in V
initialize dist[v] = infinity
dist[source] <- 0
for v in V:
add v to Q
S <- empty set
// The main loop for the algorithm
while Q is not empty:
v <- vertex in Q with min dist[v]
remove v from Q
add v to S
for neighbour u of v:
if u is in S:
continue // if u is visited then ignore it
alt <- dist[v] + weight(v, u)
if alt < dist[u]:
dist[u] <- alt // update distance of u
update Q
return distFor a more in-depth explanation of Dijkstra’s algorithm using pseudocodes, we can read an Overview of Dijkstra’s Algorithm. Then we can learn how to implement Dijkstra Shortest Path Algorithm in Java.
There are multiple ways we can implement this algorithm. Each way utilizes different data structures to store the graph, as well as the priority queue. Thus, the differences between these implementations leads to different time complexities.
In this section, we’ll discuss the time complexity of two main cases for Dijkstra’s implementations.
This case happens when:
 is represented as an adjacency matrix. Here
is represented as an adjacency matrix. Here ![w[u, v]](/wp-content/ql-cache/quicklatex.com-599fa2754b22141e016c034721bd750c_l3.svg "Rendered by QuickLaTeX.com") stores the weight of edge
stores the weight of edge  . is represented as an unordered list.
. is represented as an unordered list.Let  and
and  be the number of edges and vertices in the graph, respectively. Then the time complexity is calculated:
be the number of edges and vertices in the graph, respectively. Then the time complexity is calculated:
vertices to takes  time. takes time, and we only need
time. takes time, and we only need  to recalculate
to recalculate ![dist[u]](/wp-content/ql-cache/quicklatex.com-25f0380a6ddb69d7888c9b0ffebe74da_l3.svg "Rendered by QuickLaTeX.com") and update . Since we use an adjacency matrix here, we’ll need to loop for vertices to update the array., as one vertex is deleted from per loop.
and update . Since we use an adjacency matrix here, we’ll need to loop for vertices to update the array., as one vertex is deleted from per loop. .
.This case is valid when:
is represented as an adjacency list. is represented as a binary heap or a Fibonacci heap.First, we’ll discuss the time complexity using a binary heap. In this case, the time complexity is:
time to construct the initial priority queue of vertices. values over the course of a run of the algorithm takes  time., as one vertex is removed from per loop.) and update an element (recalculate ) in
time., as one vertex is removed from per loop.) and update an element (recalculate ) in  time.
time. , which is
, which is  , since
, since  as
as  is a connected graph.
is a connected graph.For a more in-depth overview and implementation of the binary heap, we can read the article that explains Priority Queue.
Next we’ll calculate the time complexity using a Fibonacci heap. The Fibonacci heap allows us to insert a new element in and extract the node with minimal in  . Therefore, the time complexity will be:
. Therefore, the time complexity will be:
, as one vertex is removed from per loop. values for a run of the algorithm takes time. Since each priority value update takes time, the total of all calculation and priority value updates takes  time.
time. .
.Overall, the Fibonacci heap-based implementation will run at the fastest speed. Conversely, the slowest version will be the unordered list-based priority queue version. However, if the graph is well-connected (i.e., having a huge number of edges, aka, having high density), there is not much difference between these three implementations.
For a detailed comparison of the running time with different implementations, we can read the experimenting with Dijkstra’s algorithm article.
For example, the following figure illustrates the running time comparison between six variants when the number of nodes is increasing:
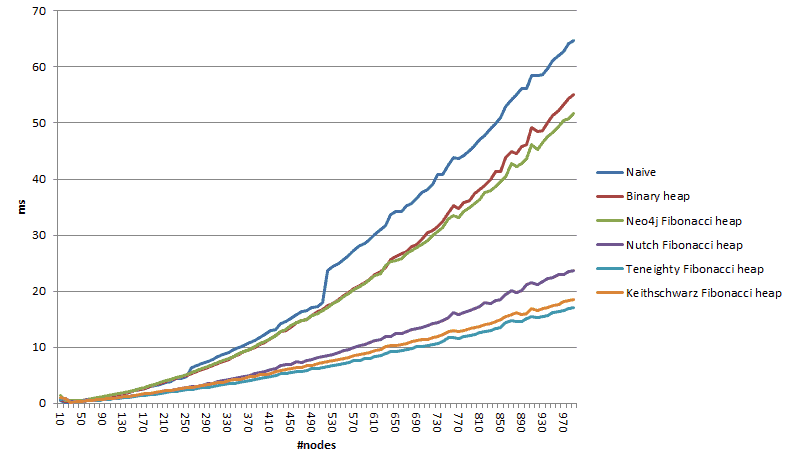
In this article, we discussed Dijkstra’s algorithm, a popular shortest path algorithm on the graph.
First, we learned the definition and the process of a priority queue. Then we explored an example to better understand how the algorithm works.
Finally, we examined and compared the complexity of the algorithm in three different implementations.