

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll study coroutines.
Coroutines are cooperative-programming constructs that almost all languages provide for concurrent execution.
At the software level, we can use processes, threads, and coroutines to achieve concurrency and solve multiple tasks faster than sequentially.
The drawback of multiprocessing is that processes are heavy-weight constructs. For each process, the OS uses mutually exclusive address space for security and separation. Further, it takes a lot of time to switch from one process to another because each requires a full set of resources (such as stack, heap, data, instructions to execute, and so on). Additionally, creating a new process is also an expensive operation, both in terms of time and OS resources. Also, we find inter-process communication much harder and slower as compared to inter-thread communication.
So, threads address those issues by providing a lightweight alternative to processes. However, coroutines are another option. A coroutine takes fewer resources, is managed at the user level, and has minimal context-switching time as compared to a thread.
We can define a coroutine as a function or a method in the program that cooperates with other coroutines. Cooperation refers to giving control voluntarily instead of being preempted like a process or a thread. Coroutines work at the user level, so we don’t need synchronization primitives (mutexes, semaphores, locks and so on).
Coroutines differ from a thread as they have no stack. That is why coroutines are lightweight as compared to both processes and threads. Further, coroutines are user-level constructs. So, they don’t make operating system calls and don’t run on a kernel thread. Instead, we run coroutines in a single user thread until they return the control flow to some other function or finish execution and return to the caller:
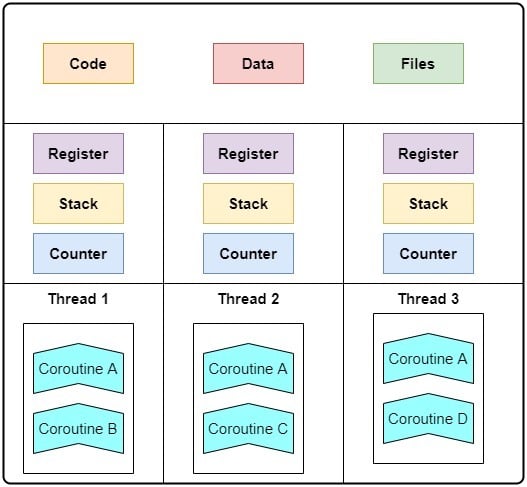
As we see, a coroutine can be invoked by multiple threads.
Coroutines achieve cooperative multitasking by releasing the CPU voluntarily.
Each coroutine can pause itself in favor of another one when that’s the best thing to do for the set of tasks at hand. So, coroutines switch by cooperating, not competing with each other.
Let’s say we have a microservice that takes user inputs, processes them, queries the database for relevant data, and finally uses the database response to send back some response to the user.
Now, reading/writing the database is a blocking operation. So the database handling coroutine can give control back to the main process instead of waiting for the database response. The main process can handle another user’s request at that time or do something else by calling another coroutine.
We call this coroutine cooperation. Here, all tasks cooperate to execute the complete workflow as fast as possible.
The coroutines are governed by a cooperative scheduler that starts them. Then, they aren’t forced to give control back like threads are. Instead, they voluntarily give it back. Developers can set switching points wherein coroutines can release control to other components of the application. Thus, they can boost concurrency and avoid callbacks.
In other words, coroutines can make our application cooperatively multitask by pausing and resuming control at predefined set points.
Let’s cement our understanding with an example.
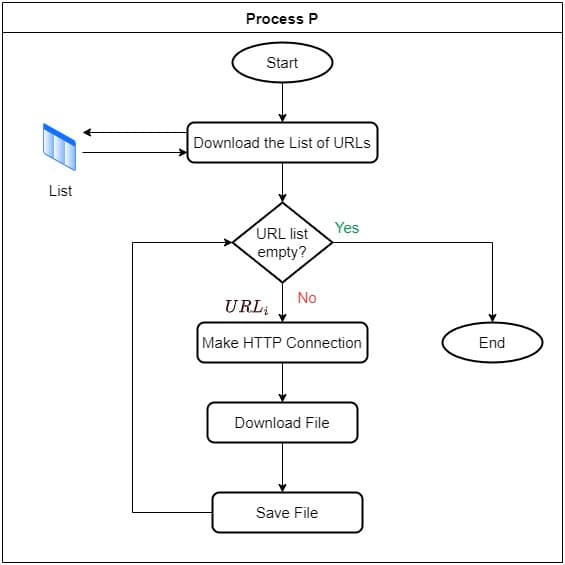
Let’s consider an application that does the following tasks in this order:
 URLs from a text file.
URLs from a text file.Now, we consider the case where we don’t use any thread or coroutines. So, here we create a process  that does all work sequentially. This means that it first reads the list and then iterates over URLs. In each iteration, it makes an HTTP connection for the URL at hand, downloads the video file as binary data, and stores it on the disk. This will be very inefficient since, for every URL, the code will block until it downloads the corresponding file:
that does all work sequentially. This means that it first reads the list and then iterates over URLs. In each iteration, it makes an HTTP connection for the URL at hand, downloads the video file as binary data, and stores it on the disk. This will be very inefficient since, for every URL, the code will block until it downloads the corresponding file:
Next, let’s use threads to solve it. So, in our process , we first read all URLs and then iterate over them with  threads:
threads:  . Each gets half of the URLs to process. For each URL it’s responsible for, it will take it as input, make an HTTP connection, download the video file, and store it on the disk:
. Each gets half of the URLs to process. For each URL it’s responsible for, it will take it as input, make an HTTP connection, download the video file, and store it on the disk:
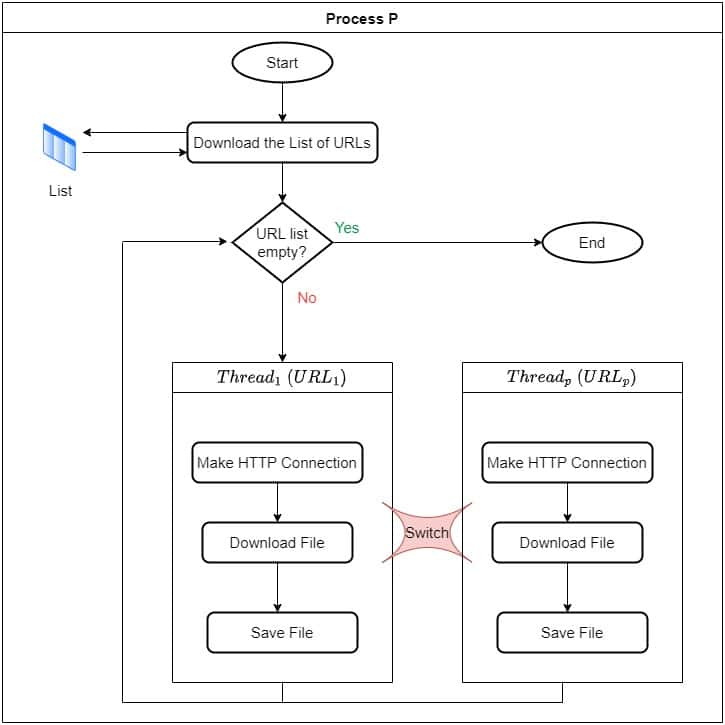
This is nonblocking and concurrent since the operating system will switch threads when they go to the suspended state. However, this approach will suffer from context switching and will involve system calls.
Last but not least, we use coroutines to solve it. So our main process will carry the first task in its main thread and then call coroutine  for times. At each iteration
for times. At each iteration  , the coroutine will take as input the
, the coroutine will take as input the  , then makes an HTTP connection to it, and download the file at a predefined location on the disk:
, then makes an HTTP connection to it, and download the file at a predefined location on the disk:
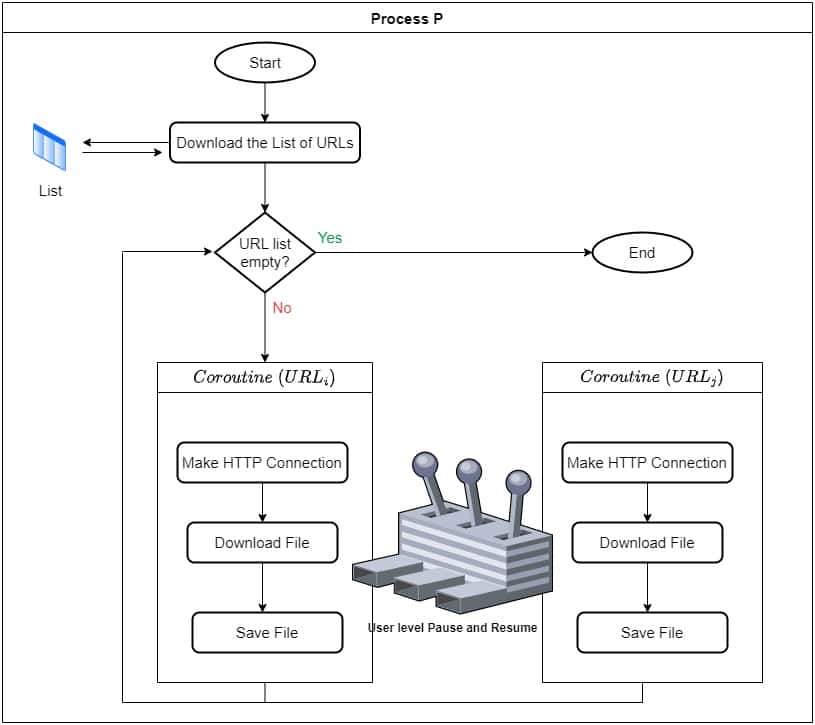
All coroutines will cooperatively execute the same steps for a different URL. So, they’ll pause and release control when they get started waiting for input. This way, we’ll run the code concurrently without any blocking and faster compared to threads and processes.
In this section, we enumerate some key benefits of coroutines.
Coroutines help us break a long blocking call into an asynchronous call. A blocking function is a method that returns only on error or completion. So, to avoid that, we can use coroutines.
With coroutines, our main process will start a coroutine to execute the blocking task and then continue to process further requests.
Irrespective of the nature of the system (uniprocessor or multiprocessor), the operating system ensures that there is only one coroutine running at any given point in time. Furthermore, each coroutine works in the non-blocking mode. Thus, the coroutines are non-preemptive meaning that a running coroutine gives up CPU voluntarily.
Coroutine boosts concurrency and provides a low-cost alternative to multithreading.
Since every coroutine is a function, it uses the system stack to store its context. It doesn’t incur spawn and kill costs and is handled at the user level. Although we could achieve the same results with threads, they are managed by the OS, use more resources, and incur costs at starting and exiting operations.
Coroutines come with mutual exclusivity. For instance, if process A has two coroutines, coroutine_1, and coroutine_2, then coroutine_1 will not interfere with coroutine_2 in terms of its memory, CPU, or any other resource.
If corotuine_1 has to wait for a resource or some other module’s result, then it will pause itself to give control to coroutine_2 instead of blocking it.
Coroutines decrease the overall execution time. This is so because they make the entire code non-blocking by voluntarily giving CPU to other coroutines.
They are not preempted using kernel calls, and there is no context-switching overhead.
A coroutine causes fewer memory leaks due to the use of structured concurrency. Structured concurrency means that any independent execution unit (say thread) is encapsulated with explicit entry and exit points. This ensures that we have perfect control of the workflow. And all units complete before exiting. The encapsulation passes the results and errors of executing units back to the parent process that can handle them in its scope.
Coroutines are designed to run asynchronous or concurrent tasks so that their tasks are guaranteed to be completed within the lifetime of the caller. Thus, no child operation is executed beyond the scope of a parent scope.
Furthermore, we can cancel coroutines without incurring a high computational cost. The coroutine library propagates cancellation through the chain of all coroutines from the caller.
Coroutines provide a viable alternative to callbacks.
Both coroutines and callbacks offer concurrency. The application usually registers callback functions that the operating system shall call in response to some event. So, a callback function is simply a function that we pass to another function as an argument. It is then invoked inside the outer function to respond to external or interval events.
When writing a callback, the developer wants the software to respond to some event but can’t predict the frequency of that event occurring. Further, it’s difficult to handle exceptions in a callback, and they are hard to understand and debug.
Coroutines solve problems of callbacks by asynchronously and cooperatively executing the code. We can set some checkpoints (like system calls, read/write files, and doing floating point operations) in our coroutine to pause and resume. This way, we can work with even those languages that don’t support exception handling in callbacks.
In this article, we have gone through coroutines. Coroutines are cooperative-programming constructs that provide a very high level of concurrency with very little overhead and less switch-over time.
Out of the processes, threads, and coroutines, we find coroutines the most lightweight. We don’t incur any cost to create it. Additionally, a coroutine is multi-entrant: this means any thread can enter it (invoke it) at any point in time. So, they are best suited for systems that demand high performance but are low on computing resources.