

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
When selecting a database system, we’ll often see them described as ACID or BASE.
In this tutorial, we’re going to see what BASE means so we can better understand how it affects our choice of database systems and thus our applications.
2. CAP Theorem
CAP Theorem – also known as Brewer’s Theorem, after Eric Brewer, who developed it – is a computer science theory describing guarantees about how distributed database systems can operate. It states that any database system can never guarantee all three of the following:
- Consistency – This means that every attempt to read data from the database will return the results of every write operation that has successfully completed before the read operation started. If the database is considered to be consistent, once any client has successfully written data to the database, then it’s guaranteed that all clients will immediately be able to read it back out again.
- Availability – This means that every request that the database receives is guaranteed to produce a response. If the database is considered to be available, as long as it’s possible to communicate with the server, then it’s guaranteed that the client will receive a response to the query.
- Partition Tolerance – This means that the database is still fully usable even in the presence of network partitions. This means that not only can all clients make queries, but those queries will operate the same as if the network was intact.
CAP theorem is typically described using the following triangle:
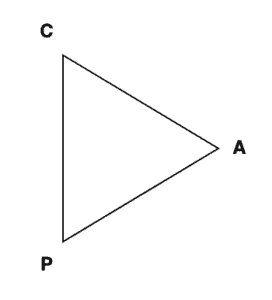
where any distributed database system will always be described as a position on this triangle.
This means that it’s never possible for a distributed database system to achieve all three of these guarantees – the best we can ever do is to achieve two of them:
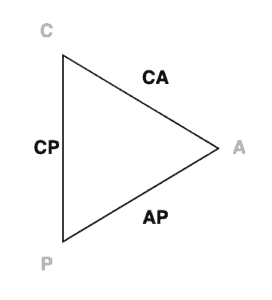
It’s important to note that the CAP theorem only applies to distributed databases. It’s impossible for a database with a single node to ever suffer from network partitioning – by definition, if the database only has a single node, then a network partition can’t exist between them.
As such, a non-distributed database can simply ignore partition tolerance – since it’s irrelevant – and strive to achieve the other two guarantees. Only in a distributed database, where there are multiple nodes, do all three of the guarantees have enough meaning for the CAP theorem to be relevant.
However, a distributed database can’t ignore partition tolerance. As such, they get to choose between Consistency or Availability.
3. What Does BASE Mean?
BASE is a database model that is popular in NoSQL database systems. It describes a database system that emphasizes availability at the cost of immediate consistency. In particular, these databases are:
- Basically Available – the database ensures that all data is available by ensuring that it’s stored across multiple nodes. This means that even if some nodes are unavailable, it’s much more likely that all of the data can still be accessed, but at the cost that it takes a non-zero amount of time for the data to spread across the nodes
- Soft-state – because the same data is stored across multiple nodes, and because this data may take time to get to every node, this means that the database can’t strongly enforce data integrity. Instead, it’s assumed that the client application will be doing this
- Eventually consistent – because the data is stored across multiple nodes, there is no guarantee that reading from one node will immediately reflect writes to another node. These reads will be consistent in time but not immediately
In total, this describes a system that will do its best to guarantee that all queries will get a successful result, but at the cost that this result might at times reflect a slightly stale version of the data.
What this looks like in reality will vary between different database systems. In general, we can probably expect that all data is stored on a number of different database nodes. This will then mean that every time data is updated, the changes will eventually propagate to all the appropriate nodes. This in turn means that all reads are highly likely to either hit a node that has a copy of the data already or else have access to another node that does.
However, this has the effect that there is a window of time between data being written to the original node and propagating to others. That means it’s possible for a read operation to come to a node that has a stale version of the data – because the newly updated version hasn’t propagated to it yet.
It’s the responsibility of the database system to balance all of this. The more widespread the data is stored, the more highly available it is but, the more likely it is that a read operation will get a stale copy of the data. If every node has a copy of the data then read operations will always succeed but it takes longer for changes to propagate. Alternatively, if only one node has a copy of the data, then propagation is instant, but network partitions can make reading that data impossible.
4. How Does BASE Relate to CAP?
Now that we understand CAP Theorem and BASE database systems, how do these relate to each other?
BASE systems are considered to be AP on our triangle:
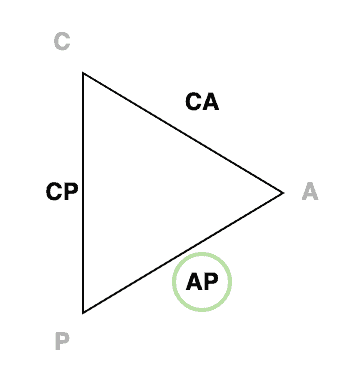
These systems emphasize availability and partition tolerance at the cost of consistency. Instead, they rely on being eventually consistent – our trade-off for achieving the other traits.
This puts much more emphasis on the client application to maintain data integrity and comes with the cost that the client needs to handle the fact that the database may not always show the latest version of any changes at all times. However, these costs are balanced against the fact that the database is highly available and very tolerant to network effects, which can make them very powerful for large-scale, distributed applications.
5. Examples of BASE Database Systems
Many NoSQL database systems can be considered to be BASE. These are often designed to work well for large-scale, distributed systems, which in turn means that partition tolerance becomes critical, and consistency is often considered an acceptable trade-off in favour of availability.
Examples of such systems include, but are not limited to MongoDB, Redis, and Cassandra. These databases all work well in large-scale, distributed applications, ensuring that the application is more reliably available even though the underlying data might occasionally be slightly stale.
6. Summary
We’ve seen here an introduction to the CAP theorem, what BASE means in terms of database systems and how they relate to each other. This can help to select the best database system for building our applications by understanding what guarantees we get from the database and what compromises we need to make to get there.