

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll explain confidence intervals and how to construct them.
Let’s introduce them with an example.
Let’s say we want to check if volleyball or basketball has a greater influence on people’s heights. The only way to be sure about the answer is to measure the heights of all professional and amateur volleyball and basketball players worldwide, but that’s impossible.
Instead, we can visit local sports clubs and measure their players’ heights. That way, we get two samples of measurements. For instance (centimeters):
![\[Volleyball = \begin{bmatrix}187 & 190 & 184 & 175 & 200 \\ 195 & 191 & 188 & 179 & 185 \\ 199 & 198 & 205 & 188 & 183 \\ 190 & 192 & 193 & 185 & 190 \end{bmatrix} \qquad Basketball = \begin{bmatrix}193 & 195 & 196 & 190 & 185 \\ 188 & 187 & 185 & 189 & 198 \\ 200 & 185 & 194 & 210 & 197 \\ 202 & 199 & 204 & 192 & 189 \end{bmatrix}\]](/wp-content/ql-cache/quicklatex.com-22fd519b4a03fa2c39b23e5a7ffcc925_l3.svg "Rendered by QuickLaTeX.com")
The mean heights in the sample are:
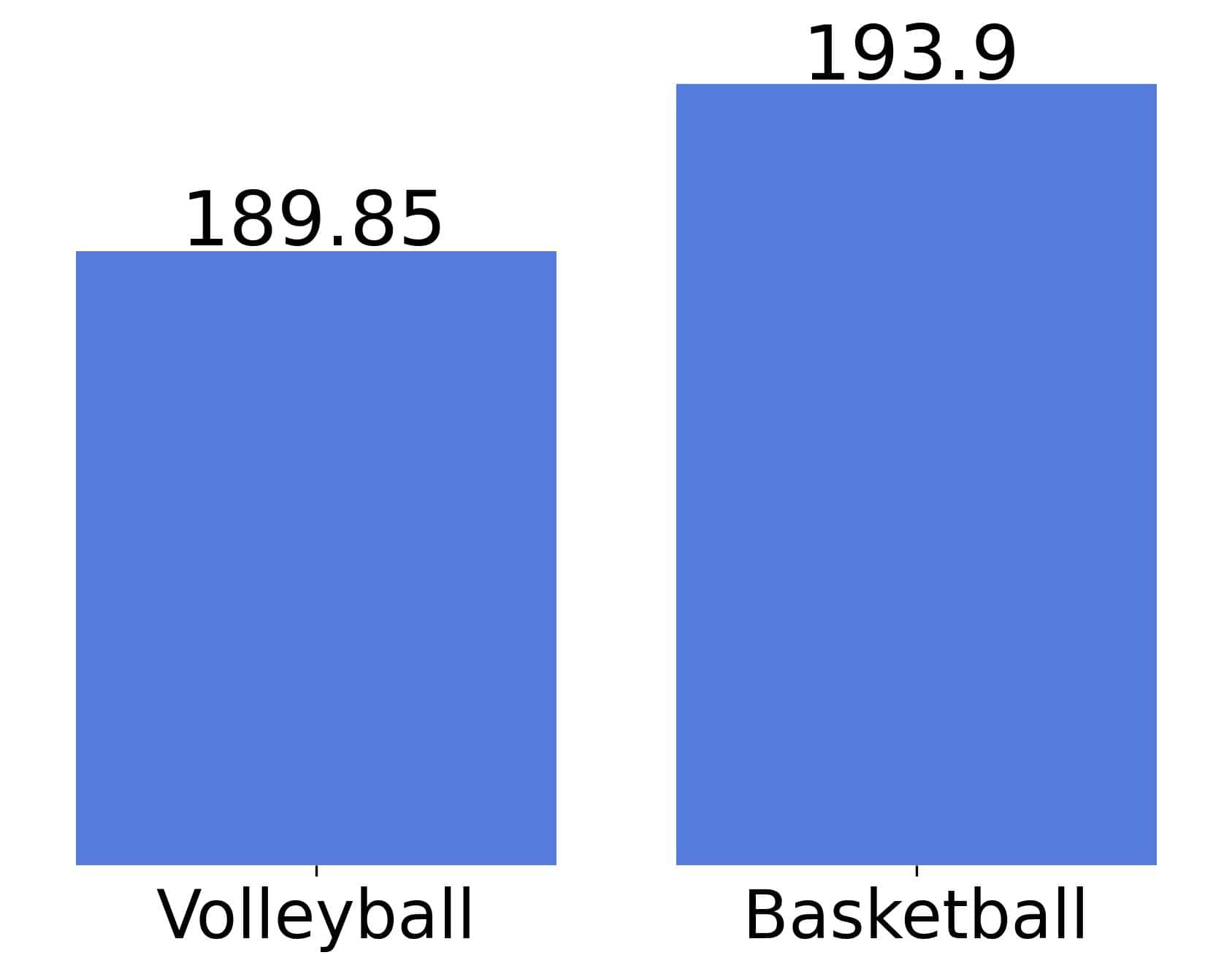
Would it be justified to claim that basketball players will grow taller than those who prefer volleyball? The caveat is that we could have gotten different results had our samples been different. That’s why it isn’t sufficient to compute sample means and proportions. We also have to quantify their uncertainty.
Confidence intervals do just that: they show us the range of plausible values of a population parameter given the one we calculated using a (much smaller) sample.
Let’s start with an informal definition.
Let  be the unknown value of a numeric parameter, population-wise. For instance, the average height of volleyball and basketball players or the proportion of a presidential candidate’s voters in a country’s electorate.
be the unknown value of a numeric parameter, population-wise. For instance, the average height of volleyball and basketball players or the proportion of a presidential candidate’s voters in a country’s electorate.
We can estimate only by analyzing samples. So, let  be a sample, and
be a sample, and  the value calculated using
the value calculated using  .
.
A confidence interval for , given , is a range of values ![[L, U] \ni \theta(S)](/wp-content/ql-cache/quicklatex.com-a4b28889c24e2c9189f346063d1707fb_l3.svg "Rendered by QuickLaTeX.com") obtained through a procedure with a predefined coverage (or confidence). The confidence expresses the probability that an interval (produced by the procedure) contains the exact value of the parameter.
obtained through a procedure with a predefined coverage (or confidence). The confidence expresses the probability that an interval (produced by the procedure) contains the exact value of the parameter.
Let’s step back for a second. Why do we say that confidence is a characteristic of the procedure and not a specific interval?
That’s because confidence intervals are a tool of frequentist statistics. We differentiate between random and specific (or realized) samples in it.
A specific sample contains specific values; examples are the samples of volleyball and basketball players’ heights.
In contrast, a random sample comprises random variables (denoted as  ). Each variable in a random sample models a possible value that a specific sample can contain.
). Each variable in a random sample models a possible value that a specific sample can contain.
Therefore, specific samples are realizations of the corresponding random samples.
When we apply the formula for to a random sample  , we get a random variable called an estimator. Let’s denote it with
, we get a random variable called an estimator. Let’s denote it with  . For the average value, is:
. For the average value, is:
![\[\frac{1}{n}\sum_{i=1}^{n} X_i\]](/wp-content/ql-cache/quicklatex.com-6532f7277ee7b49a66e28627678c7069_l3.svg "Rendered by QuickLaTeX.com")
In contrast, applying the formula for to a realized sample  results in a specific sample value we’ll denote as
results in a specific sample value we’ll denote as  . In our example with heights, the means 189.95 and 193.9 are sample values (means), i.e., realizations of the estimator.
. In our example with heights, the means 189.95 and 193.9 are sample values (means), i.e., realizations of the estimator.
Now, we’re ready for the formal definition.
A confidence interval with the confidence level of  , where
, where  , for the parameter whose true value is , estimator is , and the sample value is , is a range of values
, for the parameter whose true value is , estimator is , and the sample value is , is a range of values ![[L, U]](/wp-content/ql-cache/quicklatex.com-530a7697d83ed51d633d724249a1cb8e_l3.svg "Rendered by QuickLaTeX.com") such that:
such that:
![\[\Pr\left\{ L \leq \theta \leq U \right\} \geq \gamma\]](/wp-content/ql-cache/quicklatex.com-44926d5fb56592430a7310aa340ca70f_l3.svg "Rendered by QuickLaTeX.com")
where:
 and
and  depend on and the distribution of
depend on and the distribution of So, if we apply the procedure outputting 95% CIs to many different samples, approximately 95% will contain the actual value of the parameter of interest.
Since the probability is in the equation only through the random sample, we can ascribe the confidence level  to the procedure outputting the intervals and not to any specific interval it produces.
to the procedure outputting the intervals and not to any specific interval it produces.
In our example, is the mean of  independent and identically distributed random variables. Its standardized form:
independent and identically distributed random variables. Its standardized form:
![\[\frac{\widehat{\theta}-\theta}{s_n/\sqrt{n}}\]](/wp-content/ql-cache/quicklatex.com-12767fe6e9fd90ab58821188c7014561_l3.svg "Rendered by QuickLaTeX.com")
where  is the sample standard deviation (also an estimator), follows the Student’s t distribution with
is the sample standard deviation (also an estimator), follows the Student’s t distribution with  degrees of freedom. Let
degrees of freedom. Let  be its
be its  quantile, i.e.:
quantile, i.e.:
![\[\Pr \left\{ \frac{\widehat{\theta}-\theta}{s_n/\sqrt{n}} > t\right\} = \frac{1-\gamma}{2}\]](/wp-content/ql-cache/quicklatex.com-dd7b7690d5f79e5bc0396cd09b709ce4_l3.svg "Rendered by QuickLaTeX.com")
Since the Student’s distribution is symmetric, we also have:
![\[\Pr \left\{ \frac{\widehat{\theta}-\theta}{s_n/\sqrt{n}} < -t \right\} = \frac{1-\gamma}{2}\]](/wp-content/ql-cache/quicklatex.com-4936d19cbc95fa4889f5def6d2c15e94_l3.svg "Rendered by QuickLaTeX.com")
So, the probability for  to fall between
to fall between  and is
and is  :
:
![\[\Pr \left\{ -t < \frac{\widehat{\theta}-\theta}{s_n/\sqrt{n}} < t \right\} = \gamma\]](/wp-content/ql-cache/quicklatex.com-59a0da469de1c4358a1034e56cd291cb_l3.svg "Rendered by QuickLaTeX.com")
Manipulating the expression between the curly braces, we get:
![\[\Pr \left\{ \widehat{\theta} - \frac{t s_n}{\sqrt{n}} < \theta <\widehat{\theta} + \frac{t s_n}{\sqrt{n}} \right\} = \gamma\]](/wp-content/ql-cache/quicklatex.com-45d644129d68ea1fc8fe2c6627d633e2_l3.svg "Rendered by QuickLaTeX.com")
That’s our confidence interval.
We’ll focus on two cases: comparing the parameters of two populations and comparing one population’s parameter to a predefined value.
When we compute the 99% confidence intervals for our height means, we get  for volleyball and
for volleyball and  for basketball:
for basketball:
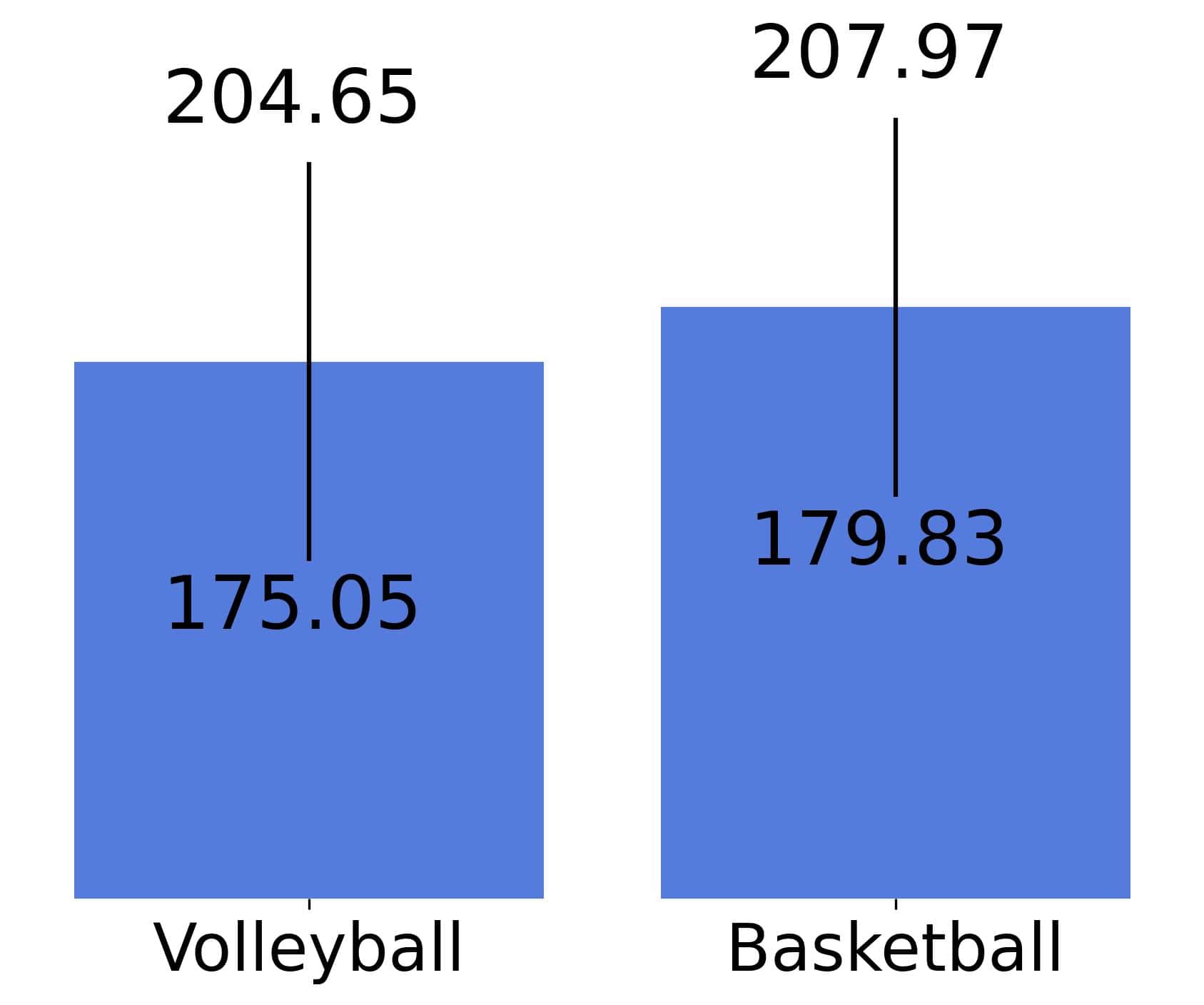
The interpretation is that the data aren’t conclusive. So, we can’t conclude which sport influences growth better by considering only those two samples. There’s a chance that the actual means are the same or close to one another, although the sample means differ.
Another way we can take is to compute the pairwise differences:
![\[\left\{v - b \colon v \in Volleyball, b \in Basketball \right\}\]](/wp-content/ql-cache/quicklatex.com-a971f37dd6ee616f0b59ea1dc6c356e1_l3.svg "Rendered by QuickLaTeX.com")
and check if the confidence interval of the mean difference contains zero. If it does, we can’t rule out that the actual means (in the entire population of volleyball and basketball players) are the same.
This shows an everyday use case of confidence intervals. Usually, there’s a value with a special meaning. For example, the 50% accuracy at guessing binary labels in a balanced set amounts to random classification. So, if the confidence interval of our classifier’s accuracy contains this value, we can’t claim it’s undoubtedly better than a random classifier.
Confidence intervals quantify uncertainty inherent in the sampling procedures, and their confidence level guarantees that they rarely miss the population values. So, it’s justified to use them since they capture the actual values most of the time. The exact meaning of “most of the time” and “rarely” are implied by our choice of .
However, confidence intervals are complex to understand. It isn’t easy to grasp why confidence levels refer to the procedures constructing the intervals rather than the intervals themselves. Further, does it make sense to consider the unseen data (modeled by random samples) to make inferences after observing a specific sample?
The Bayesian school of thought deems this counterintuitive and wrong. Its alternative is what we call credible intervals. Unlike their frequentist counterparts, credible intervals contain the actual values with the predefined probability. However, the nature of that probability is different. For Bayesians, the probability is a degree of belief. For frequentists, it’s the long-term frequency of an event occurring.
Let’s say two intervals don’t overlap or an interval doesn’t contain a value corresponding to a no-effect state (e.g., zero when comparing differences). In that case, we say we have a statistically significant result.
However, statistical significance is not the same as proof beyond doubt. For instance, if the height intervals didn’t overlap, we couldn’t be 100% sure that the population mean heights differ. Sampling is random, so we always have to account for the chance that our conclusions are due to randomness. Mathematically, that’s implied by our confidence being lower than 100%.
Replication is needed to accumulate enough evidence. If many studies analyzed basketball and volleyball players’ heights and got non-overlapping intervals with a mean difference of 2 cm, it would be justified to conclude that these two sports have different effects on height.
However, that wouldn’t mean the finding is scientifically significant or useful. The height difference of 2 cm isn’t that big. There’s hardly anything an 189 cm tall person can do that a 187 cm tall one can’t. So, we have to consider the effect size in addition to statistical significance.
In this article, we talked about confidence intervals. They quantify uncertainty but are easily misinterpreted. The confidence denotes the long-term frequency of intervals containing the actual value, not the probability that our specific interval contains it.