Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Algorithm for Handwriting Recognition
Last updated: March 16, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
There are various applications in computer science, and handwriting recognition is one of them. The handwriting recognition systems are classified into two basic types: online and offline.
In this tutorial, we’ll discuss the methods and techniques used for handwriting text recognition
2. Online Character Recognition Algorithms
Let’s start by understanding the online algorithm for character recognition. This method entails the automated conversion of text as it is typed on a specific digitizer. In this step, a sensor detects pen-tip motions as well as pen-up/pen-down switching to produce a signal. Then, transform the resulting signal into letter codes that may be used in computer and text-processing programs.
Character recognition algorithms are classified into three categories. These categories are often employed in sequence: pre-processing, feature extraction, and classification. The pre-processing aids in the smoothness of feature extraction, while feature extraction is required for successful classification.
2.1. Pre-processing
The goal of this phase of pre-processing is to remove irrelevant information from the incoming data that might interfere with recognition. In short, this is about speed and precision. Pre-processing often includes binarization, sampling, normalization, smoothing, and denoising.
2.2. Feature Extraction
In this phase, we determine the important qualities that distinguish the cases that are independent of one another. The goal of this stage is to emphasize key information for the recognition model. This information might include pen pressure, velocity, or changes in writing direction.
2.3. Classification and Recognition
This is the decision-making phase of the recognition system. Various models are employed to map the extracted characteristics to different classes and, as a result, identify the letters or words that the features represent.
3. Offline Character Recognition Algorithms
Let’s take a look at the offline algorithm for character recognition. The offline approach involves the automatic conversion of the input into letter codes. Then, we use these letter codes in computer and text-processing programs. There are traditional and modern methods for the offline approach.
3.1. Traditional Methods
The traditional method of offline handwriting recognition consists of three steps:
- Character extraction: This implies that the individual characters in the scanned picture must be extracted. The most typical flaw is when connected characters are returned as a single sub-image comprising both characters. This creates a significant issue at the recognition step.
- Character recognition: Following the extraction of individual characters, we use a recognition engine to identify the corresponding computer character.
- Feature extraction: Feature extraction is comparable to neural network recognizers in its operation. However, programmers must choose which properties are relevant to them. As a result, feature extraction is not a completely automated operation.
Here’s an example of the classical processing for text recognition using an image as input:
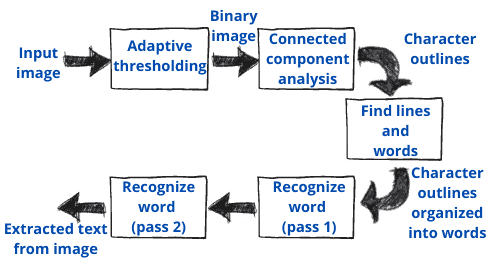
3.2. Modern Methods
Whereas traditional approaches focus on identifying individual characters, modern approaches focus on segmenting all the characters in a segmented line of text. So, these approaches concentrate on machine learning algorithms that can learn visual characteristics rather than the previously employed limited feature engineering.
These modern approaches employ convolutional networks to extract visual information from many overlapping windows of an input. So, the feature extraction is automated and the convolutional network doesn’t need feature engineering. Then, we use a recurrent neural network to generate character probabilities from the visual information. The image below represents an example of a deep learning algorithm:

4. Text Recognition Techniques
The handwriting recognition system requires handling a “stream of data” (a single input is mapped onto multiple outputs) since the number of symbols in output usually varies. For example, we have one input (for example an image as input) and we want to have the group of characters, words, and lines. This means that once we detect a character, the next cannot be a random character. In other words, we are dealing with sequential data.
So, if we try to rephrase this statement it’s like we have one input and a lot of outputs. There are different solutions to develop a “stream of data” for Handwriting recognition:
- Recurrent neural networks (RNNs): The main disadvantage of RNNs is that the previous state is always required for computing the current one. This means that the graphic processor unit (GPU) must focus the majority of its resources on a specific segment of the task rather than spreading to the largest possible scale. This means that training is not well parallelizable.
- Transformers: This method employs an essential notion known as “attention.” As a result, training speed and inference are two of the primary benefits over RNN.
5. Example of Architecture for Handwriting Text Recognition
Let’s take a look at an example of an offline Handwritten Text Recognition (HTR) system that converts text from scanned images into digital text:

5.1. Model Overview
Let’s employ a neural network model for the HTR system. The model consists of convolutional neural network (CNN) layers, recurrent neural network (RNN) layers, and a final Connectionist Temporal Classification (CTC) layer. Here’s an overview of the HTR system:

This function  represents the neural network that maps an image
represents the neural network that maps an image  of size
of size  to a character sequence
to a character sequence  of length
of length  to
to  . So, the text is identified at the character level. Therefore, the model recognizes the words or texts that are not in the training data.
. So, the text is identified at the character level. Therefore, the model recognizes the words or texts that are not in the training data.
5.2. Operation
The HTR system consists of three phases:
- Convolutional Neural Network (CNN) layers: The purpose of this phase is to extract relevant features from the images. This phase consists of five layers and each layer consists of three operations. First, we apply a filter kernel of size
 in the first two layers and
in the first two layers and  in the last three layers. Then, we use the ReLU as the activation function. Finally, we use the pooling layer to summarize the regions of each image.
in the last three layers. Then, we use the ReLU as the activation function. Finally, we use the pooling layer to summarize the regions of each image. - Recurrent Neural Network (RNN) layers: We use the Long Short-Term Memory (LSTM) version of RNNs, which can propagate information over larger distances and has robust training characteristics.
- Connectionist Temporal Classification (CTC) layer: Following the integration of CNN and RNN, the model can be trained with the loss developed by Alex Graves, known as CTC. The CTC receives only the matrix and decodes it into the final text.
6. Conclusion
In this tutorial, we’ve discussed the basic concept of the handwriting recognition algorithm using an example to unlock its mechanism. We’ve also gone over the methods and techniques of a handwriting recognition system.