

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Introduction
In this tutorial, we’re going to have a look at Apache Nutch. We’ll see what it is, what we can do with it, and how to use it.
Apache Nutch is a ready-to-go web crawler that we can use out of the box, and that integrates with other tools from the Apache ecosystem, such as Apache Hadoop and Apache Solr.
2. Setting up Nutch
Before we can start using Nutch, we’ll need to download the latest version. We can find this at https://nutch.apache.org/download/ and just download the latest binary version, which at the time of writing was 1.20. Once downloaded, we need to unzip it into an appropriate directory.
Once unzipped, we need to configure the user agent that Nutch will be using when it accesses other sites. We do this by editing conf/nutch-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>http.agent.name</name>
<value>MyNutchCrawler</value>
</property>
</configuration>This configures Nutch so that all HTTP requests made to retrieve files use a value of MyNutchCrawler for the user agent. Obviously, the exact value to use here will depend on the crawler setup that we’re configuring.
3. Crawling Our First Site
Now that we have Nutch installed, we’re ready to crawl our first URL. The crawling process in Nutch consists of several stages, which allows us a lot of flexibility when necessary.
We manage the entire process using the bin/nutch command-line tool. This tool allows us to execute various parts of the Nutch suite.
3.1. Injecting Seed URLs
Before we can crawl any URLs, we first need to seed some base URLs. We do this by creating some text files containing the URLs and then injecting them into our crawl database using the inject command:
$ mkdir -p urls
$ echo https://www.baeldung.com > urls/seed.txt
$ bin/nutch inject crawl/crawldb urlsThis injects the URL https://www.baeldung.com into our crawl database, which will be crawl/crawldb. Because this is our first URL, this will also create the crawl database from scratch.
Let’s check the URLs that are in our database to make sure:
$ bin/nutch readdb crawl/crawldb -dump crawl/log
$ cat crawl/log/part-r-00000
https://www.baeldung.com/ Version: 7
Status: 1 (db_unfetched)
Fetch time: Sat May 18 09:31:09 BST 2024
Modified time: Thu Jan 01 01:00:00 GMT 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata:
Here, we see that we’ve got a single URL and that it’s never been fetched.
3.2. Generating Crawl Segments
The next step in our crawl process is to generate a segment into which we’ll create the crawl data. This is done using the generate command, telling it where our crawl database is and where to create the segments:
$ bin/nutch generate crawl/crawldb crawl/segments
.....
2024-05-18 09:48:00,281 INFO o.a.n.c.Generator [main] Generator: Partitioning selected urls for politeness.
2024-05-18 09:48:01,288 INFO o.a.n.c.Generator [main] Generator: segment: crawl/segments/20240518100617
2024-05-18 09:48:02,645 INFO o.a.n.c.Generator [main] Generator: finished, elapsed: 3890 msIn this case, we’ve just generated a new segment located in crawl/segments/20240518100617. The segment name is always the current timestamp, meaning they’re always unique and incrementing.
By default, this will generate segment data for every URL that’s ready to fetch, including every URL we’ve never fetched or where the fetch interval has expired.
If desired, we can instead generate data for a limited set of URLs using the -topN parameter. This will then restrict the crawl phase to only fetching that many URLs:
$ bin/nutch generate crawl/crawldb crawl/segments -topN 20At this point, let’s query the segment and see what it looks like:
$ bin/nutch readseg -list crawl/segments/20240518100617
NAME GENERATED FETCHER START FETCHER END FETCHED PARSED
20240518100617 1 ? ? ? ?This tells us that we’ve got one URL but that nothing has yet been fetched.
3.3. Fetching and Parsing URLs
Once we’ve generated our crawl segment, we’re ready to fetch the URLs. We do this using the fetch command, pointing it toward the segment that it needs to fetch:
$ bin/nutch fetch crawl/segments/20240518100617This command will start up the fetcher, running a number of concurrent threads to fetch all of our outstanding URLs.
Let’s query the segment again to see what’s changed:
$ bin/nutch readseg -list crawl/segments/20240518100617
NAME GENERATED FETCHER START FETCHER END FETCHED PARSED
20240518100617 1 2024-05-18T10:11:16 2024-05-18T10:11:16 1 ?Now, we can see that we’ve actually fetched our URL, but we’ve not yet parsed it. We do this with the parse command, again pointing it towards the segment that’s just been fetched:
$ bin/nutch parse crawl/segments/20240518100617Once it’s finished, we’ll query our segment and see that the URLs have now been parsed:
$ bin/nutch readseg -list crawl/segments/20240518100617
NAME GENERATED FETCHER START FETCHER END FETCHED PARSED
20240518100617 1 2024-05-18T10:11:16 2024-05-18T10:11:16 1 13.4. Updating the Crawl Database
The final step in our crawl process is to update our crawl database. Up to this point, we’ve fetched our set of URLs and parsed them but haven’t done anything with that data.
Updating our crawl database will merge our parsed URLs into our database, including the actual page contents, but it will also inject any discovered URLs so that the next crawl round will use them. We achieve this with the updatedb command, pointing to both our crawl database and the segment that we wish to update it from:
$ bin/nutch updatedb crawl/crawldb crawl/segments/20240518100617After we’ve done this, our database is updated with all of our crawl results.
Let’s check it again to see how it’s looking:
$ bin/nutch readdb crawl/crawldb -stats
2024-05-18 10:21:42,675 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics start: crawl/crawldb
2024-05-18 10:21:44,344 INFO o.a.n.c.CrawlDbReader [main] Statistics for CrawlDb: crawl/crawldb
2024-05-18 10:21:44,344 INFO o.a.n.c.CrawlDbReader [main] TOTAL urls: 59
.....
2024-05-18 10:21:44,352 INFO o.a.n.c.CrawlDbReader [main] status 1 (db_unfetched): 58
2024-05-18 10:21:44,352 INFO o.a.n.c.CrawlDbReader [main] status 2 (db_fetched): 1
2024-05-18 10:21:44,352 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics: doneHere, we see that we now have 59 URLs in our database, of which we’ve fetched one, with another 58 we haven’t yet fetched.
3.5. Generating an Inverted Link Database
In addition to updating the crawl database, we can also maintain an inverted link database.
Our crawl data so far includes all of the pages that we’ve crawled, and for each of those, a set of “outlinks” – pages that each of these links out to.
In addition to this, we can also generate a database of “inlinks” – for each of our crawled pages, the set of pages that link to it. We use the invertlinks command for this, pointing to our link database and the segment that we wish to include:
$ bin/nutch invertlinks crawl/linkdb crawl/segments/20240518100617Note that this database of “inlinks” only includes cross-domain links, so it will only contain any links from one page to another that come from a different domain.
3.6. Crawling Again
Now that we’ve crawled one page and discovered 58 new URLs, we can run the entire process again and crawl all of these new pages. We do this by repeating the process that we did before, starting with generating a new segment, and working all the way through to updating our crawl database with it:
$ bin/nutch generate crawl/crawldb crawl/segments
$ bin/nutch fetch crawl/segments/20240518102556
$ bin/nutch parse crawl/segments/20240518102556
$ bin/nutch updatedb crawl/crawldb crawl/segments/20240518102556
$ bin/nutch invertlinks crawl/linkdb crawl/segments/20240518102556Unsurprisingly, this time the fetch process took a lot longer. This is because we’re now fetching a lot more URLs than before.
If we again query the crawl database, we’ll see that we have a lot more data fetched now:
$ bin/nutch readdb crawl/crawldb -stats
2024-05-18 10:33:15,671 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics start: crawl/crawldb
2024-05-18 10:33:17,344 INFO o.a.n.c.CrawlDbReader [main] Statistics for CrawlDb: crawl/crawldb
2024-05-18 10:33:17,344 INFO o.a.n.c.CrawlDbReader [main] TOTAL urls: 900
.....
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 1 (db_unfetched): 841
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 2 (db_fetched): 52
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 3 (db_gone): 1
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 4 (db_redir_temp): 1
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] status 5 (db_redir_perm): 5
2024-05-18 10:33:17,351 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics: doneWe now have 900 total URLs, of which we’ve fetched 52. The reason that only 52 URLs were processed when we had 59 in our list before is that not all of the URLs in our list could be fetched and parsed. Some of them were images, or JSON files, or other resources that Nutch is unable to parse out of the box.
We can now repeat this process as much as we wish, on whatever cadence we wish.
4. Restricting Domains
One issue that we have with the crawler so far is that it will follow any URLs, regardless of where they go. For example, if we dump the list of URLs from our crawl database – that is, URLs that either we have fetched or else that we’re going to on the next round – then we’ll see there are 60 different hosts, including:
- www.baeldung.com
- courses.baeldung.com
- github.com
- www.linkedin.com
Depending on our desired result, this might not be good. If we want a generic web crawler that will scan the entire web, this is ideal. If we want to only scan a single site or a set of sites, then this is problematic.
Usefully, Nutch has a built-in mechanism for exactly this case. We can configure a set of regular expressions to either include or exclude URLs. These are found in the conf/regex-urlfilter.txt file.
Every non-comment line in this file is a regular expression prefixed with either a “-” (meaning exclude) or a “+” (meaning include). If we get to the end of the file without a match, then the URL is excluded.
We’ll see that the very last line is currently “+.“. This will include every single URL that none of the earlier rules excluded.
If we change this line to instead read “+^https?://www\.baeldung\.com“, then this will now only match URLs that start with either http://www.baeldung.com or https://www.baeldung.com.
Note that we can’t retroactively apply these rules. Only crawls that happen after they’re configured are affected. However, if we delete all of our crawl data and start again with these rules in place, after two passes, we end up with:
$ bin/nutch readdb crawl/crawldb -stats
2024-05-18 17:57:34,921 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics start: crawl/crawldb
2024-05-18 17:57:36,595 INFO o.a.n.c.CrawlDbReader [main] Statistics for CrawlDb: crawl/crawldb
2024-05-18 17:57:36,596 INFO o.a.n.c.CrawlDbReader [main] TOTAL urls: 670
.....
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] status 1 (db_unfetched): 613
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] status 2 (db_fetched): 51
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] status 4 (db_redir_temp): 1
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] status 5 (db_redir_perm): 5
2024-05-18 17:57:36,607 INFO o.a.n.c.CrawlDbReader [main] CrawlDb statistics: doneWe get a total of 670 URLs instead of 900. So, we can see that, without this exclusion rule, we’d have had an extra 230 URLs that were outside the site we wanted to crawl.
5. Indexing with Solr
Once we’ve got our crawl data, we need to be able to use it. The obvious approach is to query it with a search engine, and Nutch comes with standard support for integrating with Apache Solr.
First, we need a Solr server to use. If we don’t already have one installed, the Solr quickstart guide will show us how to install one.
Once we’ve got this, we need to create a new Solr collection to index our crawled sites into:
# From the Solr install
$ bin/solr create -c nutchOnce we’ve done this, we need to configure Nutch to know about this. We do this by adding some configuration to our conf/nutch-site.xml file within the Nutch install:
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.solr.store.SolrStore</value>
</property>
<property>
<name>solr.server.url</name>
<value>http://localhost:8983/solr/nutch</value>
</property>The storage.data.store.class setting configures the storage mechanism to use, and the solr.server.url setting configures the URL of the Solr collection we want to index our crawl data into.
At this point, we can index our crawl data using the index command:
# From the Nutch install
bin/nutch index crawl/crawldb/ -linkdb crawl/linkdb/ crawl/segments/20240518100617 -filter -normalize -deleteGone
2024-05-19 11:12:12,502 INFO o.a.n.i.s.SolrIndexWriter [pool-5-thread-1] Indexing 1/1 documents
2024-05-19 11:12:12,502 INFO o.a.n.i.s.SolrIndexWriter [pool-5-thread-1] Deleting 0 documents
2024-05-19 11:12:13,730 INFO o.a.n.i.IndexingJob [main] Indexer: number of documents indexed, deleted, or skipped:
2024-05-19 11:12:13,732 INFO o.a.n.i.IndexingJob [main] Indexer: 1 indexed (add/update)
2024-05-19 11:12:13,732 INFO o.a.n.i.IndexingJob [main] Indexer: finished, elapsed: 2716 msWe need to run this every time we do a crawl, on the segment that we’ve just generated for that crawl.
Once we’ve done this, we can now use Solr to query our index data:
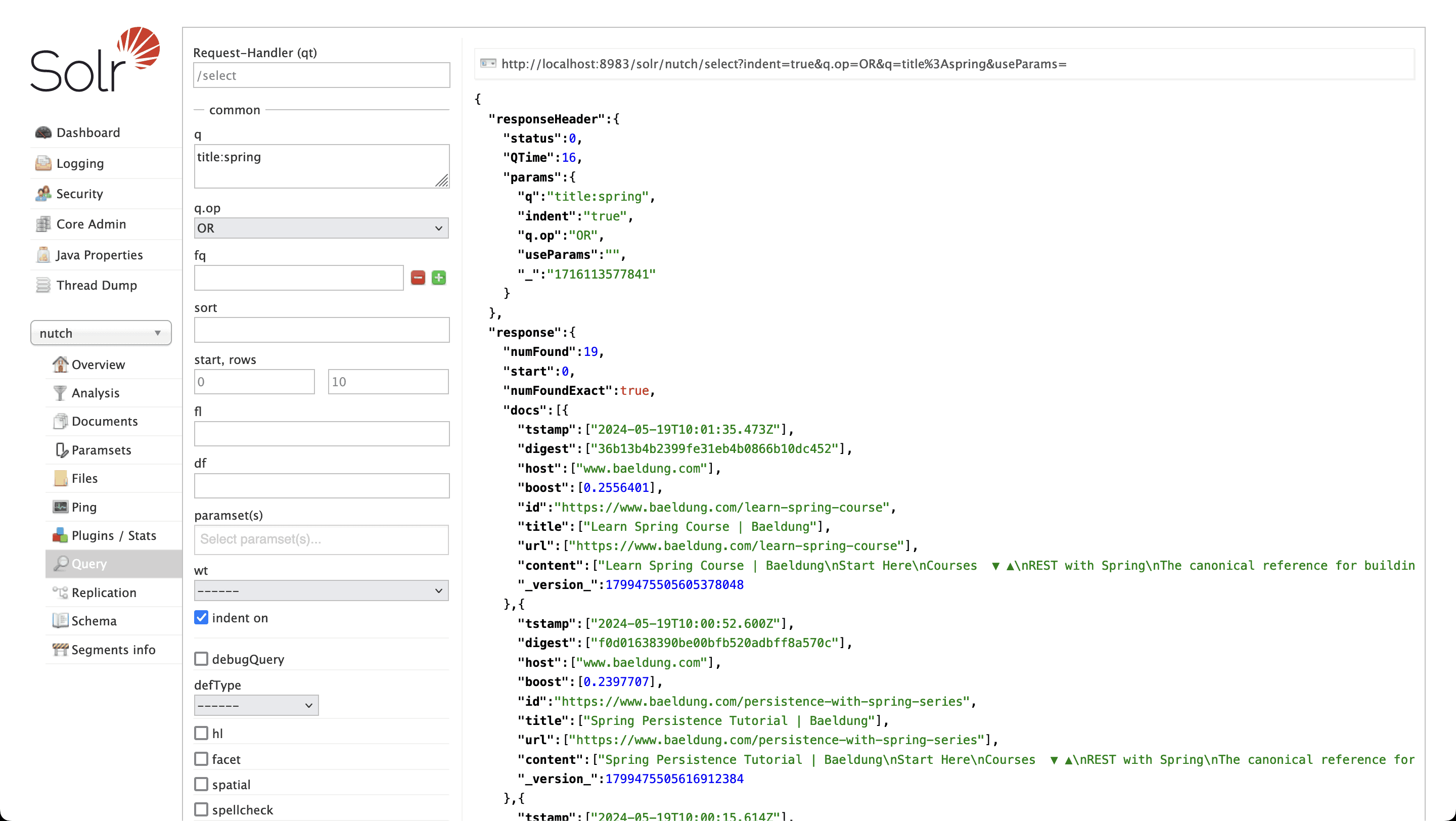
Here, we can see that searching our crawl data for any pages with the title containing “Spring” has returned 19 documents.
6. Automating the Crawl Process
So far, we’ve successfully crawled our site. However, many steps were needed to achieve this result.
Thankfully, Nutch comes with a script that does all of this for us automatically – bin/crawl. We can use this to perform all of our steps in the correct order, get the segment IDs correct every time, and run the process for as many rounds as we want. This can also include injecting seed URLs at the start and sending the results to Solr after each round.
For example, to run the entire process that we’ve just described for two rounds, we can execute:
$ ./bin/crawl -i -s urls crawl 2Let’s break down the command:
- “-i” tells it to index the crawled data in our configured search index.
- “-s urls” tells it where to find our seed URLs.
- “crawl” tells it where to store our crawl data.
- “2” tells it the number of crawl rounds to run.
If we run this on a clean Nutch install – having first configured our conf/nutch-site.xml and conf/regex-urlfilter.txt files – then the end result will be exactly the same as if we ran all of our previous steps by hand.
7. Conclusion
We’ve seen here an introduction to Nutch, how to set it up and crawl our first website, and how to index the data into Solr so that we can search it. However, this only scratches the surface of what we can achieve with Nutch, so why not explore more for yourself?

















