

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss web crawling and web scraping, two concepts of data mining used to understand website data and collect website data. Mainly, we’ll talk about their process and the differences between the two concepts. Finally, we’ll present the benefits, shortcomings, and common use cases of web crawling and scraping.
A web crawler, web spider, or crawler is a program that searches and automatically indexes web content and other data over the web. Web crawlers scan webpages to understand every page of a website to retrieve, update, and index information when users perform search queries.
The goal of a crawler is to understand the content of a website. This allows users to extract information on one or more pages as needed.
Web scraping is the procedure of gathering and examining raw data from the internet. The collection of web data can be done either manually (by copying and pasting information from websites) or automatically with the aid of web scraping tools.
Web scraping aims to convert specific website content into a structured format, such as tables, JSON, databases, and XML representations.
A web crawler gathers URL(s). The crawler retrieves and analyzes the collected URLs. Crawler checks all the pages matching URLs, hyperlinks, all URLs, and meta tags. The crawler saves the indexed data within a database after indexing all the content on each particular page. Additionally, we summarize the crawling process in four steps:
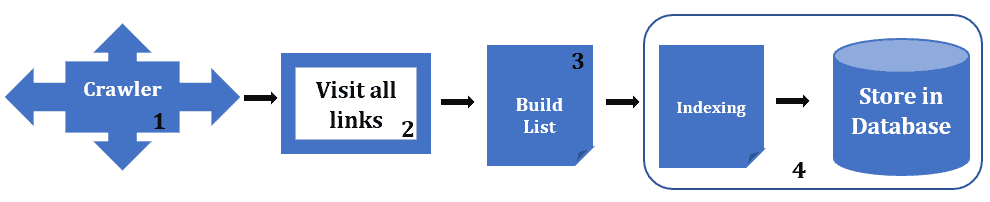
However, when a web crawler retrieves and analyzes a URL, it discovers new links embedded in the page. The crawler then adds these URLs to a queue for later crawling.
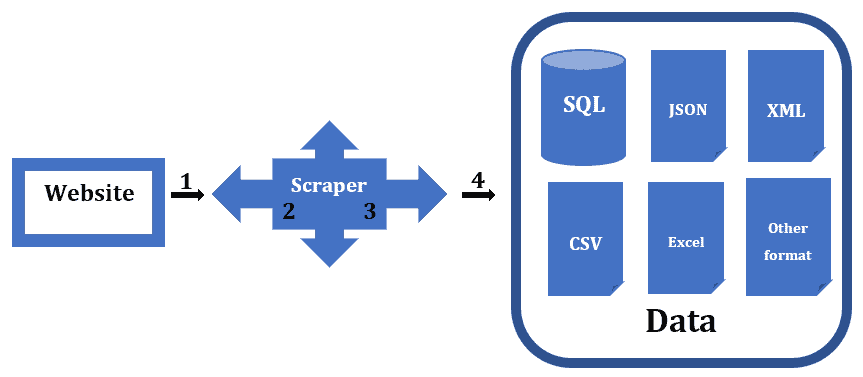
The web scraping procedure must first determine the target website to scrape. The scraper sends a connection request to the target website. By entering the target website in the scraper’s input field and executing it, the scraper extracts the necessary data from the target website. These data download in the intended format.
However, based on the previous paragraph, we use four steps to summarize the scraping process:
Web scraping and web crawling are two related concepts of web mining that mix up. Web scraping is a particular use of web crawling to produce a focused dataset. The following table presents the main difference between the two:
| Web Scraping | Web Crawling | |
|---|---|---|
| Aim | Extracting the information on web pages. | Indexing and finding webpages. |
| Involve | Develop a bot that can stealthily gather data from different websites. | Follow links permanently based on hyperlinks. |
| Use | Analyze webpages. | Understand webpages. |
Speed, data extraction at scale, cost-effectiveness, flexibility and systematic approach, performance reliability and robustness, low maintenance costs, and automatic delivery of structured data are some advantages of web scraping.
However, some shortcomings of web scraping are noticed. Web scraping has a learning curve, needs perpetual maintenance, and can get blocked.
Web crawling has the following advantages: easy to gather data, increases site traffic, keeps track of user activity, and keeps track of important information.
However, despite how simple it may seem, web crawling presents some difficulties: maintaining database freshness, absence of context, non-uniform structures, bandwidth and impact on web servers, and the rise of anti-scraping tools.
Search engines like Google, Yahoo, or Bing utilize a search algorithm (crawler) to display webpages and pertinent information. SEO (Search Engine Optimization) is the set of techniques used to improve the rank of a website on search engine results pages. A crawler is a tool for assessing a site’s position in the search results and performing the necessary improvements for the optimal user experience.
Collecting and analyzing websites is a purpose of web scraping. Many businesses use the website and analyzing methods.
Retail Marketing use web scraping to stay current with the quick changes that are occurring all the time in internet markets. The stock market analysis utilizes to download financial information from online resources. Lead generation is one of the most significant aspects of sales and marketing. Web scraping help to reduce the cost of lead generation by automatically determining what sources we’re going to use.
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.