Introduction to Apache Kafka
Last updated: February 6, 2025

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In this tutorial, we’ll learn the basics of Kafka – the use cases and core concepts anyone should know. We can then find and understand more detailed articles about Kafka.
2. What Is Kafka?
Kafka is an open-source stream processing platform developed by the Apache Software Foundation. We can use it as a messaging system to decouple message producers and consumers, but in comparison to “classical” messaging systems like ActiveMQ, it is designed to handle real-time data streams and provides a distributed, fault-tolerant, and highly scalable architecture for processing and storing data.
Therefore, we can use it in various use cases:
- Real-time data processing and analytics
- Log and event data aggregation
- Monitoring and metrics collection
- Clickstream data analysis
- Fraud detection
- Stream processing in big data pipelines
3. Setup A Local Environment
If we deal with Kafka for the first time, we might like to have a local installation to experience its features. We could get this quickly with the help of Docker.
3.1. Install Kafka
We download an existing image and run a container instance with this command:
docker run -p 9092:9092 -d bashj79/kafka-kraftThis will make the so-called Kafka broker available on the host system at port 9092. Now, we would like to connect to the broker using a Kafka client. There are multiple clients that we can use.
3.2. Use Kafka CLI
The Kafka CLI is part of the installation and is available within the Docker container. We can use it by connecting to the container’s bash.
First, we need to find out the container’s name with this command:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7653830053fa bashj79/kafka-kraft "/bin/start_kafka.sh" 8 weeks ago Up 2 hours 0.0.0.0:9092->9092/tcp awesome_aryabhataIn this sample, the name is awesome_aryabhata. We then connect to the bash using:
docker exec -it awesome_aryabhata /bin/bashNow, we can, for example, create a topic (we’ll clarify this term later) and list all existing topics with this commands:
cd /opt/kafka/bin
# create topic 'my-first-topic'
sh kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-first-topic --partitions 1 --replication-factor 1
# list topics
sh kafka-topics.sh --bootstrap-server localhost:9092 --list
# send messages to the topic
sh kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-first-topic
>Hello World
>The weather is fine
>I love Kafka3.3. Use KafkaIO GUI
The KafkaIO is a GUI application for managing Kafka. We can download it on any supported platform (Mac, Windows, Linux & Unix) and install it quickly. Then, to create a connection we specify the bootstrap servers of the Kafka broker/s:

3.4. Use UI for Apache Kafka (Kafka UI)
The UI for Apache Kafka (Kafka UI) is a web UI, implemented with Spring Boot and React, and provided as a Docker image for a simple installation as a container with the following command:
docker run -it -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true provectuslabs/kafka-uiWe can then open the UI in the browser using http://localhost:8080 and define a cluster, as this picture shows:
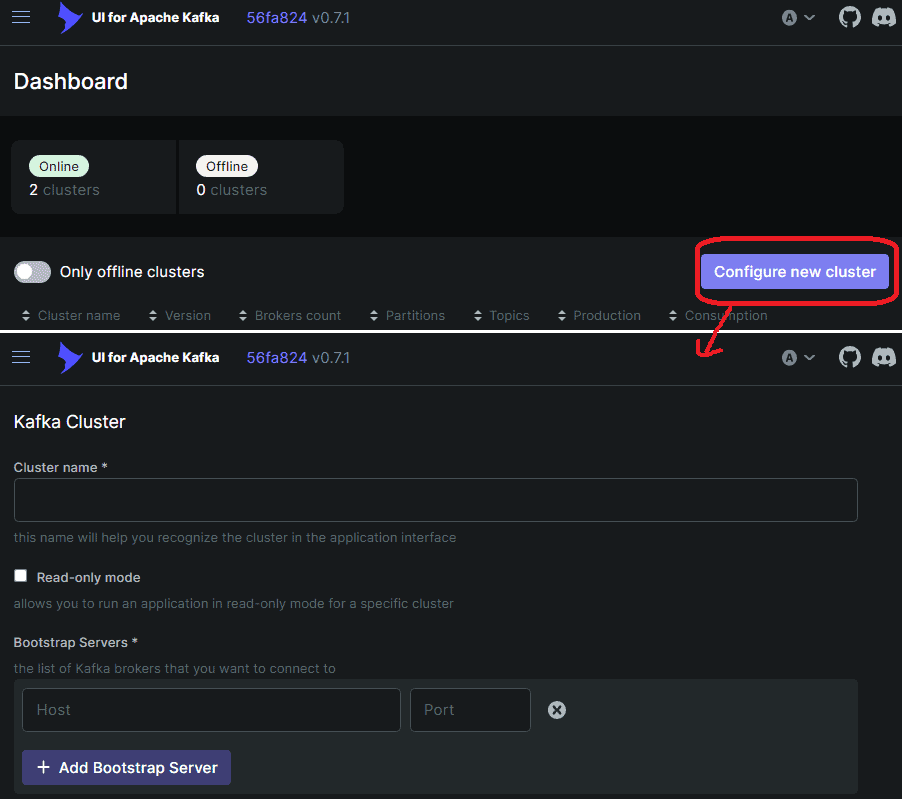
Because the Kafka broker runs in a different container than the Kafka UI’s backend, it will not have access to localhost:9092. We could instead address the host system using host.docker.internal:9092, but this is just the bootstrapping URL.
Unfortunately, Kafka itself will return a response that leads to a redirection to localhost:9092 again, which won’t work. If we do not want to configure Kafka (because this would break with the other clients then), we need to create a port forwarding from the Kafka UI’s container port 9092 to the host systems port 9092. The following sketch illustrates the connections:
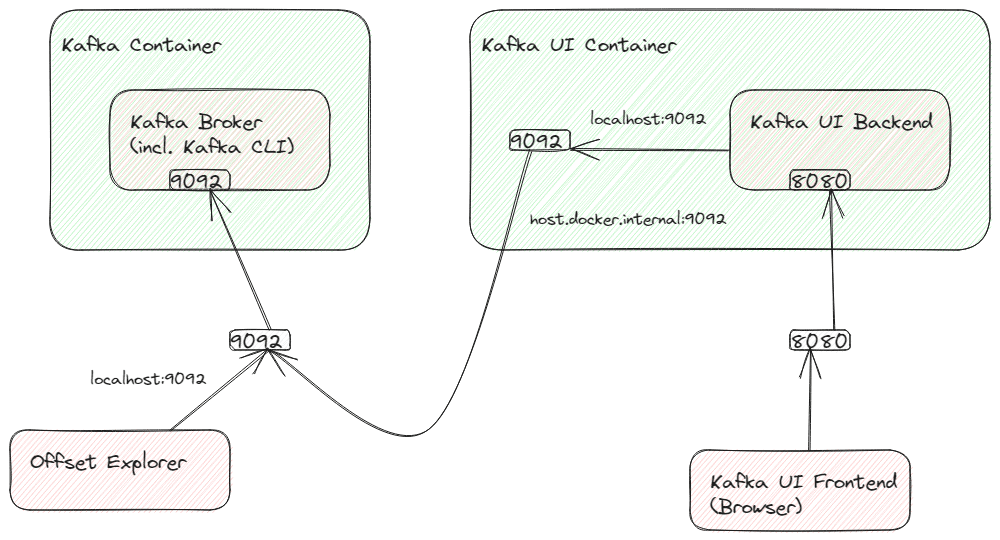
We can setup this container-internal port forwarding, e.g. using socat. We have to install it within the container (Alpine Linux), so we need to connect to the container’s bash with root permissions. So we need these commands, beginning within the host system’s command line:
# Connect to the container's bash (find out the name with 'docker ps')
docker exec -it --user=root <name-of-kafka-ui-container> /bin/sh
# Now, we are connected to the container's bash.
# Let's install 'socat'
apk add socat
# Use socat to create the port forwarding
socat tcp-listen:9092,fork tcp:host.docker.internal:9092
# This will lead to a running process that we don't kill as long as the container's runningAccordingly, we need to run socat each time we start the container. Another possibility would be to provide an extension to the Dockerfile.
Now, we can specify localhost:9092 as the bootstrap server within the Kafka UI and should be able to view and create topics, as shown below:
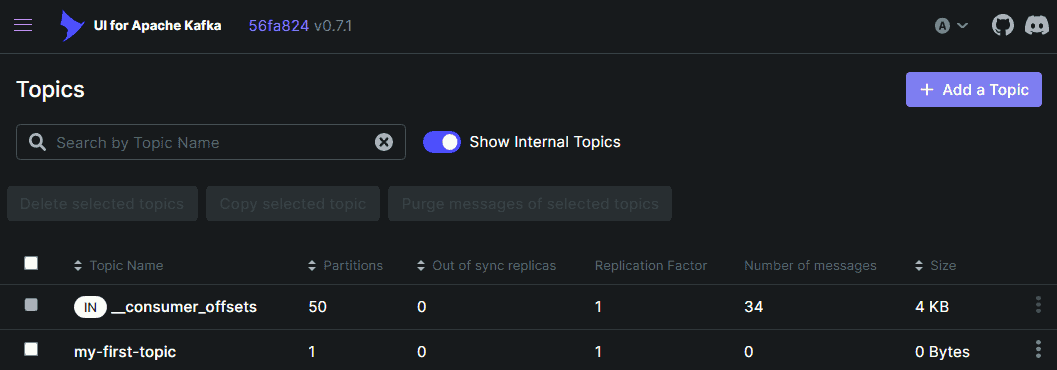
3.5. Use Kafka Java Client
We have to add the following Maven dependency to our project:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.9.0</version>
</dependency>We can then connect to Kafka and consume the messages we produced before:
// specify connection properties
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "MyFirstConsumer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// receive messages that were sent before the consumer started
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// create the consumer using props.
try (final Consumer<Long, String> consumer = new KafkaConsumer<>(props)) {
// subscribe to the topic.
final String topic = "my-first-topic";
consumer.subscribe(Arrays.asList(topic));
// poll messages from the topic and print them to the console
consumer
.poll(Duration.ofMinutes(1))
.forEach(System.out::println);
}Of course, there is an integration for the Kafka Client in Spring.
4. Basic Concept
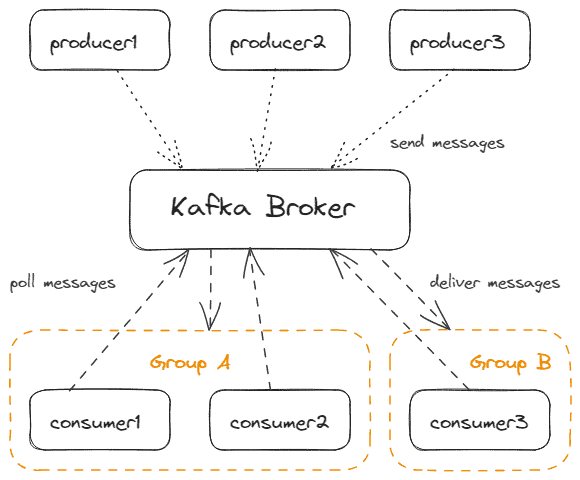
4.1. Producers & Consumers
We can differentiate Kafka clients into consumers and producers. Producers send messages to Kafka, while consumers receive messages from Kafka. They only receive messages by actively polling from Kafka. Kafka itself is acting passively. This allows each consumer to have a unique performance without blocking Kafka.
Of course, there can be multiple producers and multiple consumers at the same time. And, of course, one application can contain both producers and consumers.
Consumers are part of a Consumer Group that Kafka identifies by a simple name. Only one consumer of a consumer group will receive the message. This allows scaling out consumers with the guarantee of only-once message delivery.
The following picture shows multiple producers and consumers working together with Kafka:
4.2. Messages
A message (we can also name it “record” or “event“, depending on the use case) is the fundamental unit of data that Kafka processes. Its payload can be of any binary format as well as text formats like plain text, Avro, XML, or JSON.
Each producer has to specify a serializer to transform the message object into the binary payload format. Each consumer has to specify a corresponding deserializer to transform the payload format back to an object within its JVM. We call these components shortly SerDes. There are built-in SerDes, but we can implement custom SerDes too.
The following picture shows the payload serialization and deserialization process:
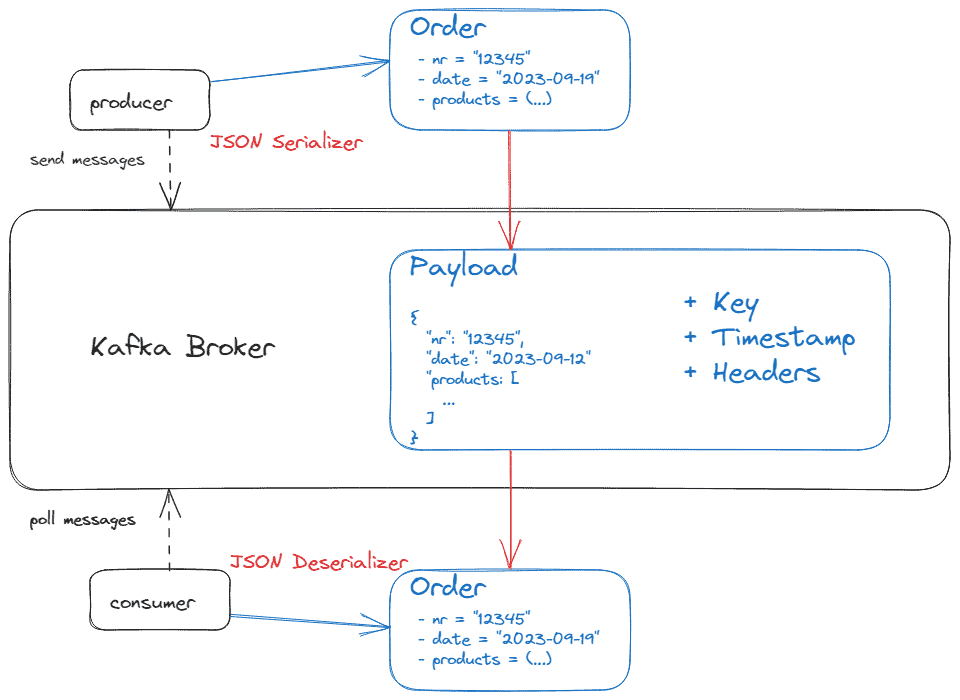
Additionally, a message can have the following optional attributes:
- A key that also can be of any binary format. If we use keys, we also need SerDes. Kafka uses keys for partitioning (we’ll discuss this in more detail in the next chapter).
- A timestamp indicates when the message was produced. Kafka uses timestamps for ordering messages or to implement retention policies.
- We can apply headers to associate metadata with the payload. E.g. Spring adds by default type headers for serialization and deserialization.
4.3. Topics & Partitions
A topic is a logical channel or category to which producers publish messages. Consumers subscribe to a topic to receive messages from in the context of their consumer group.
By default, the retention policy of a topic is 7 days, i.e. after 7 days, Kafka deletes the messages automatically, independent of delivering to consumers or not. We can configure this if necessary.
Topics consist of partitions (at least one). To be exact, messages are stored in one partition of the topic. Within one partition, messages get an order number (offset). This can ensure that messages are delivered to the consumer in the same order as they were stored in the partition. And, by storing the offsets that a consumer group already received, Kafka guarantees only-once delivery.
By dealing with multiple partitions, we can determine that Kafka can provide both ordering guarantees and load balancing over a pool of consumer processes.
One consumer will be assigned to one partition when it subscribes to the topic, e.g. with the Java Kafka client API, as we have already seen:
String topic = "my-first-topic";
consumer.subscribe(Arrays.asList(topic));However, for a consumer, it is possible to choose the partition(s) it wants to poll messages from:
TopicPartition myPartition = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(myPartition));
The disadvantage of this variant is that all group consumers have to use this, so automatically assigning partitions to group consumers won’t work in combination with single consumers that connect to a special partition. Also, rebalancing is not possible in case of architectural changes like adding further consumers to the group.
Ideally, we have as many consumers as partitions, so that every consumer can be assigned to exactly one of the partitions, as shown below:
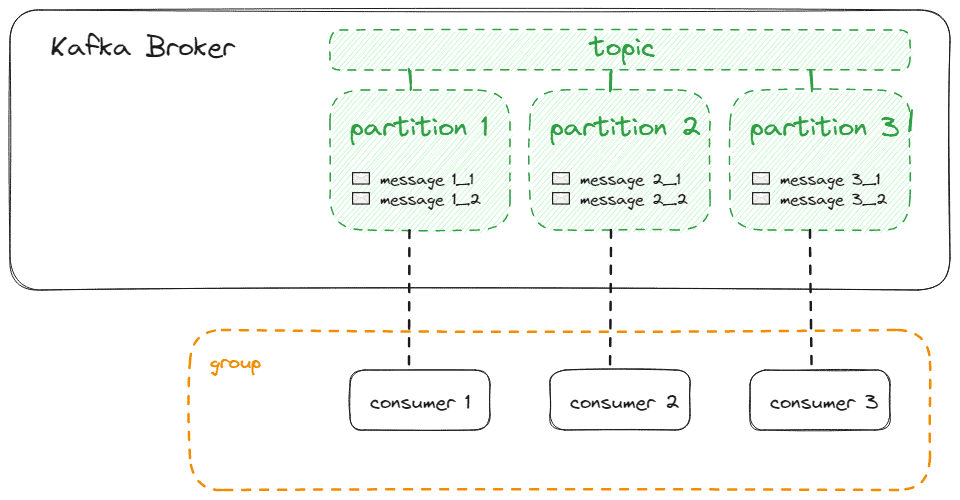
If we have more consumers than partitions, those consumers won’t receive messages from any partition:
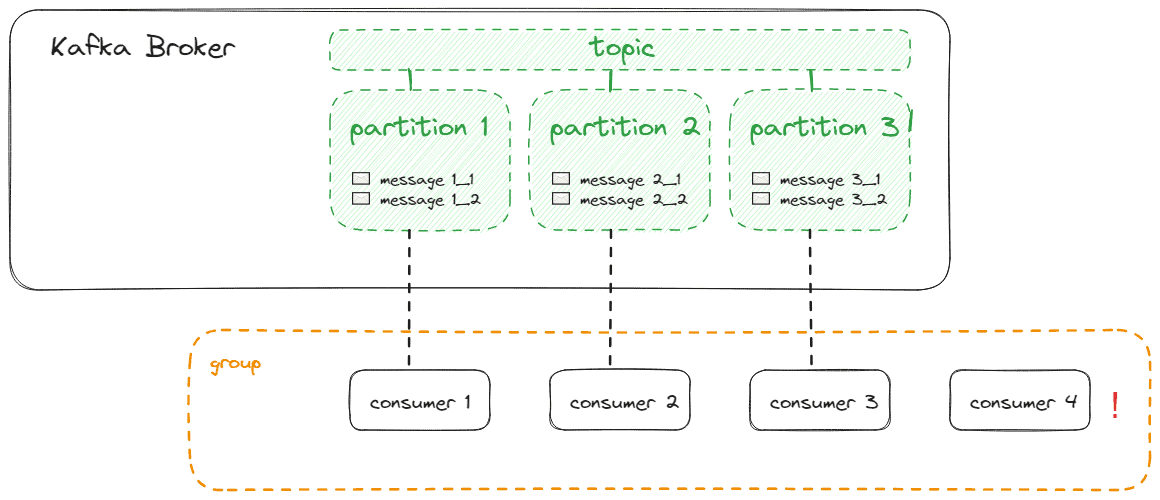
If we have fewer consumers than partitions, consumers will receive messages from multiple partitions, which conflicts with optimal load balancing:
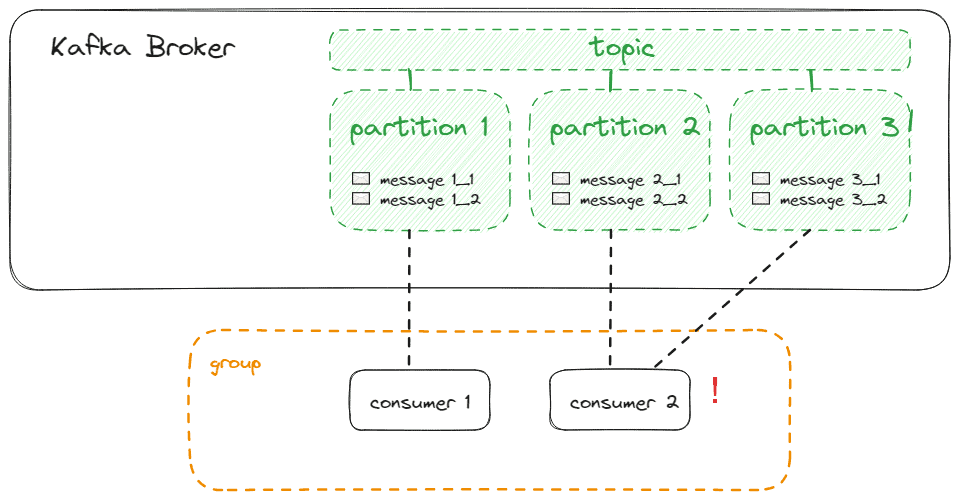
Producers do not necessarily send messages to only one partition. Every produced message is assigned to one partition automatically, following these rules:
- Producers can specify a partition as part of the message. If done so, this has the highest priority
- If the message has a key, partitioning is done by calculating the hash of the key. Keys with the same hash will be stored in the same partition. Ideally, we have at least as many hashes as partitions
- Otherwise, the Sticky Partitioner distributes the messages to partitions
Again, storing messages to the same partition will retain the message ordering, while storing messages to different partitions will lead to disordering but parallel processing.
If the default partitioning does not match our expectations, we can simply implement a custom partitioner. Therefore, we implement the Partitioner interface and register it during the initialization of the producer:
Properties producerProperties = new Properties();
// ...
producerProperties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyCustomPartitioner.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(producerProperties);The following picture shows producers and consumers and their connections to the partitions:
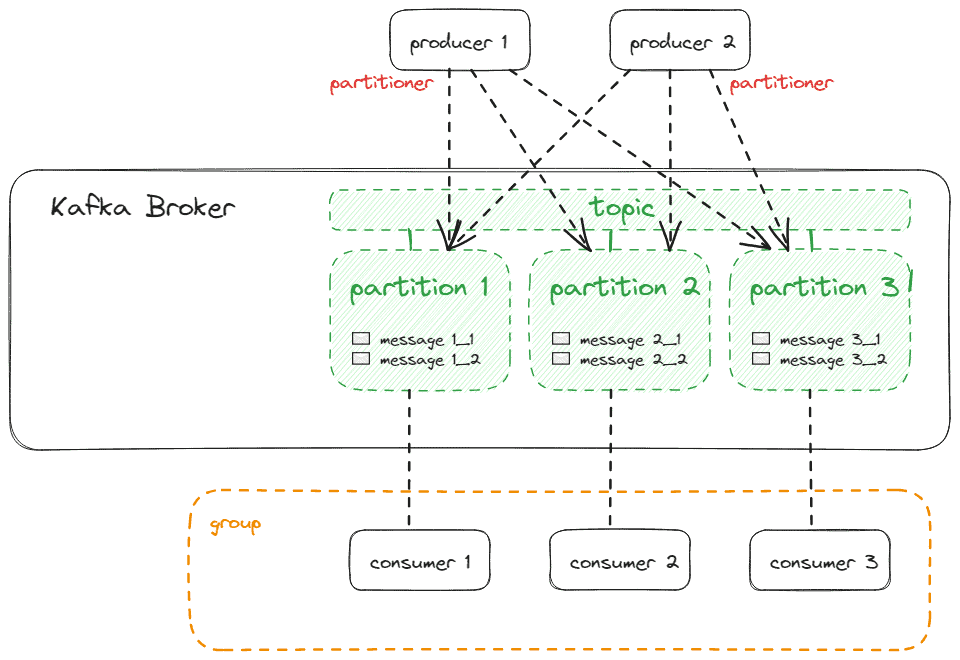
Each producer has its own partitioner, so if we want to ensure that messages are partitioned consistently within the topic, we have to ensure that the partitioners of all producers work the same way, or we should only work with a single producer.
Partitions store messages in the order they arrive at the Kafka broker. Typically, a producer does not send each message as a single request, but it will send multiple messages within a batch. If we need to ensure the order of the messages and only-once delivery within one partition, we need transaction-aware producers and consumers.
4.4. Clusters and Partition Replicas
As we have found out, Kafka uses topic partitions to allow parallel message delivery and load balancing of consumers. But Kafka itself must be scalable and fault-tolerant. So we typically do not use a single Kafka Broker, but a Cluster of multiple brokers. These brokers do not behave completely the same, but each of them is assigned special tasks that the rest of the cluster can then absorb if one broker fails.
To understand this, we need to expand our understanding of topics. When creating a topic, we not only specify the number of partitions but also the number of brokers that jointly manage the partitions using synchronization. We call this the Replication Factor. For example, using the Kafka CLI, we could create a topic with 6 partitions, each of them synchronized on 3 brokers:
sh kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-replicated-topic --partitions 6 --replication-factor 3For example, a replication factor of three means, that the cluster is resilient for up to two replica failures (N-1 resiliency). We have to ensure that we have at least as many brokers as we specify as the replication factor. Otherwise, Kafka does not create the topic until the count of brokers increases.
For better efficiency, replication of a partition only occurs in one direction. Kafka achieves this by declaring one of the brokers as the Partition Leader. Producers only send messages to the partition leader, and the leader then synchronizes with the other brokers. Consumers will also poll from the partition leader because the increasing consumer group’s offset has to be synchronized too.
Partition leading is distributed to multiple brokers. Kafka tries to find different brokers for different partitions. Let’s see an example with four brokers and two partitions with a replication factor of three:
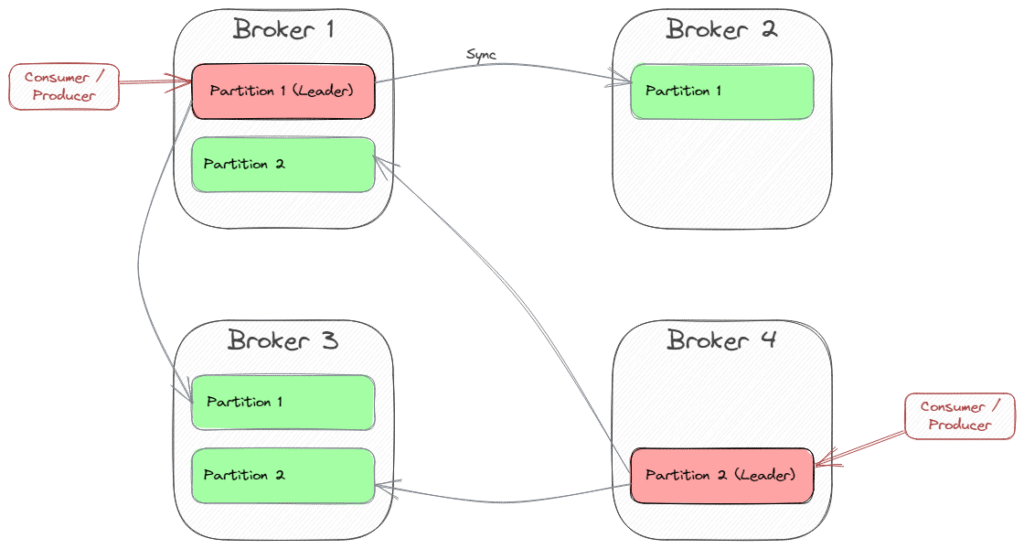
Broker 1 is the leader of Partition 1, and Broker 4 is the leader of Partition 2. So each client will connect to those brokers when sending or polling messages from these partitions. To get information about the partition leaders and other available brokers (metadata), there is a special bootstrapping mechanism. In summary, we can say that every broker can provide the cluster’s metadata, so the client could initialize the connection with each of these brokers, and will redirect to the partition leaders then. That’s why we can specify multiple brokers as bootstrapping servers.
If one partition-leading broker fails, Kafka will declare one of the still-working brokers as the new partition leader. Then, all clients have to connect to the new leader. In our example, if Broker 1 fails, Broker 2 becomes the new leader of Partition 1. Then, the clients that were connected to Broker 1 have to switch to Broker 2.
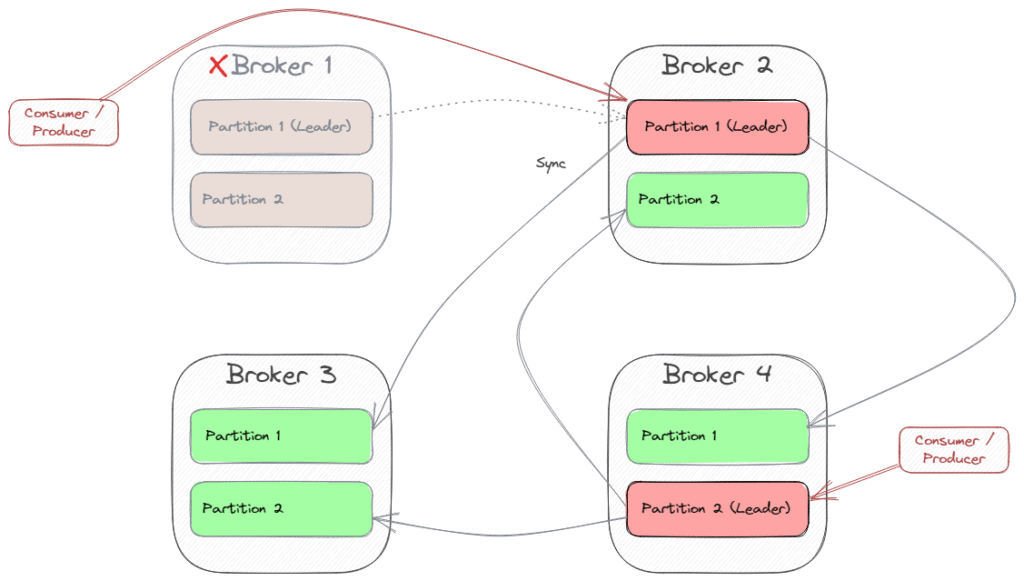
Kafka uses Kraft (in earlier versions: Zookeeper) for the orchestration of all brokers within the cluster.
4.4. Putting All Together
If we put producers and consumers together with a cluster of three brokers that manage a single topic with three partitions and a replication factor of 3, we’ll get this architecture:
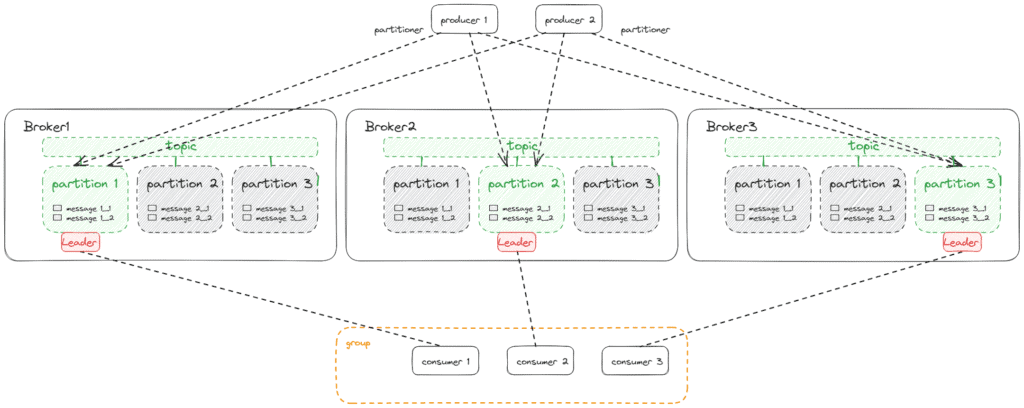
5. Ecosystem
We already know that multiple clients like a CLI, a Java-based client with integration to Spring applications, and multiple GUI tools are available to connect with Kafka. Of course, there are further Client APIs for other programming languages (e.g., C/C++, Python, or Javascript), but those are not part of the Kafka project.
Built on top of these APIs, there are further APIs for special purposes.
5.1. Kafka Connect API
Kafka Connect is an API for exchanging data with third-party systems. There are existing connectors e.g. for AWS S3, JDBC, or even for exchanging data between different Kafka clusters. And of course, we can write custom connectors too.
5.2. Kafka Streams API
Kafka Streams is an API for implementing stream processing applications that get their input from a Kafka topic, and store the result in another Kafka topic.
5.3. KSQL
KSQL is an SQL-like interface built on top of Kafka Streams. It does not require us to develop Java code, but we can declare SQL-like syntax to define stream processing of messages that are exchanged with Kafka. For this, we use the ksqlDB, which connects to the Kafka cluster. We can access ksqlDB with a CLI or with a Java client application.
5.4. Kafka REST Proxy
The Kafka REST proxy provides a RESTful interface to a Kafka cluster. This way, we do not need any Kafka clients and avoid using the native Kafka protocol. It allows web frontends to connect with Kafka and makes it possible to use network components like API gateways or firewalls.
5.5. Kafka Operators for Kubernetes (Strimzi)
Strimzi is an open-source project that provides a way to run Kafka on Kubernetes and OpenShift platforms. It introduces custom Kubernetes resources making it easier to declare and manage Kafka-related resources in a Kubernetes-native way. It follows the Operator Pattern, i.e. operators automate tasks like provisioning, scaling, rolling updates, and monitoring of Kafka clusters.
5.6. Cloud-based Managed Kafka Services
Kafka is available as a managed service on the commonly used cloud platforms: Amazon Managed Streaming for Apache Kafka (MSK), Managed Service – Apache Kafka on Azure, and Google Cloud Managed Service for Apache Kafka.
6. Conclusion
In this article, we have learned that Kafka is designed for high scalability and fault tolerance. Producers collect messages and send them in batches, topics are divided into partitions to allow parallel message delivery and load balancing of consumers, and replication is done over multiple brokers to ensure fault tolerance.

















