Kafka’s Shift from ZooKeeper to Kraft
Last updated: January 28, 2026


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Introduction
Kafka, in its architecture, has recently shifted from ZooKeeper to a quorum-based controller that uses a new consensus protocol called Kafka Raft, shortened as Kraft (pronounced “craft”).
In this tutorial, we’ll examine the reasons why Kafka has taken this decision and how the change simplifies its architecture and makes it more powerful to use.
2. Brief Overview of ZooKeeper
ZooKeeper is a service that enables highly reliable distributed coordination. It was originally developed at Yahoo! to streamline processes running on big data clusters. It started as a sub-project of Hadoop but later became a standalone Apache Foundation project in 2008. It’s widely used to serve several use cases in large distributed systems.
2.1. ZooKeeper Architecture
ZooKeeper stores data in a hierarchical namespace, similar to a standard file system. The namespace consists of data registers called znodes. A name is a sequence of path elements separated by a slash.
Every node in the namespace is identified by a path:
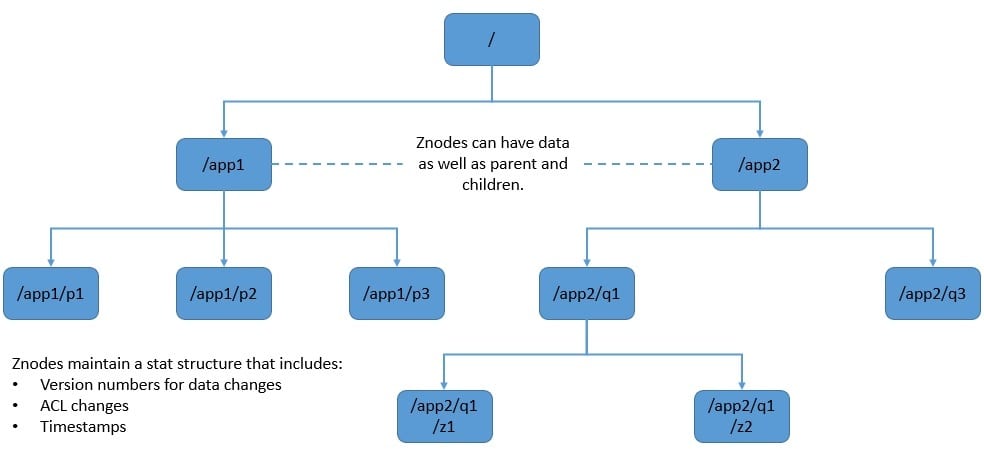
There can be three types of znodes in a ZooKeeper namespace:
- The first is persistent, which is the default type and remains in ZooKeeper until deleted.
- The second is ephemeral, which gets deleted if the session in which the znode was created disconnects. Also, ephemeral znodes can’t have children.
- The third is sequential, which we can use to create sequential numbers like IDs.
Through its simple architecture, ZooKeeper offers a reliable system with fast processing and scalability. It’s intended to be replicated over a set of servers called an ensemble. Each server maintains an in-memory image of the state, along with a transition log and snapshots in a persistent store:
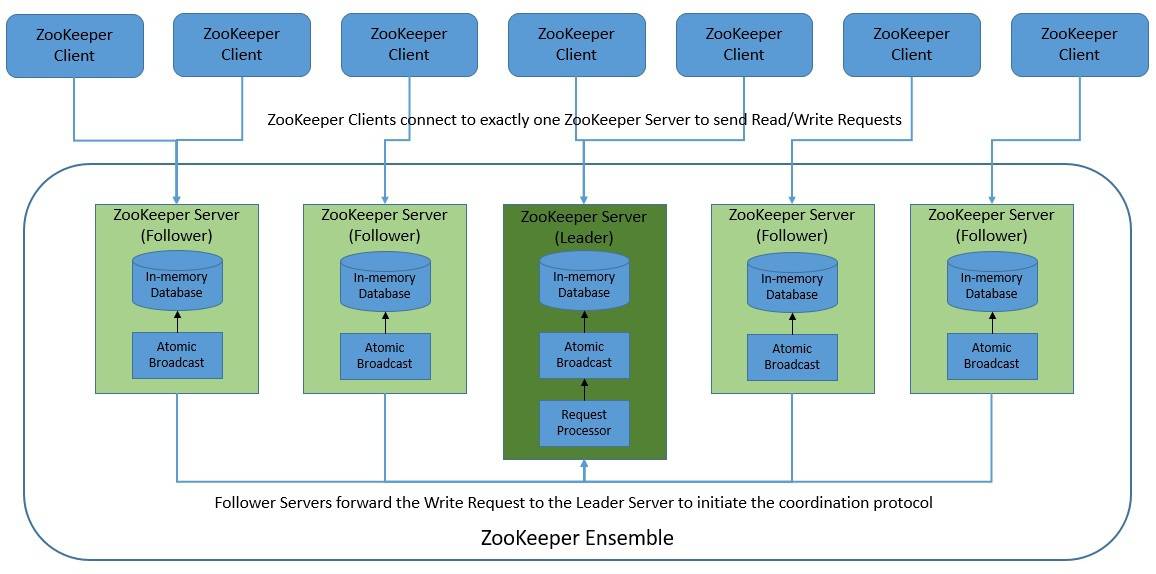
ZooKeeper clients connect to exactly one server but can failover to another if the server becomes unavailable. Read requests are serviced from the local replica of each server database. Write requests are processed by an agreement protocol. This involves forwarding all such requests to the leader server, which coordinates them using the ZooKeeper Atomic Broadcast (ZAB) protocol.
Basically, the atomic messaging is at the heart of ZooKeeper, which keeps all of the servers in sync. It ensures the reliable delivery of messages. It also ensures that the messages are delivered in total and causal order. The messaging system basically establishes point-to-point FIFO channels between servers leveraging TCP for communication.
2.2. ZooKeeper Usage
ZooKeeper provides sequential consistency and atomicity for all updates from a client. Also, it doesn’t allow concurrent writes. Moreover, a client always sees the same view of the service regardless of the server it connects to. Overall, ZooKeeper provides excellent guarantees for high performance, high availability, and strictly ordered access.
ZooKeeper has also achieved very high throughput and low latency numbers. These attributes make it a good fit for solving several coordination problems in large distributed systems. These include use cases like naming service, configuration management, data synchronization, leader election, message queue, and notification system.
3. ZooKeeper in Kafka
Kafka is a distributed event store and stream processing platform. It was originally developed at LinkedIn and was subsequently open-sourced under the Apache Software Foundation in 2011. Kafka provides a high-throughput and low-latency platform for handling real-time data feeds. It’s widely used for high-performance use cases like streaming analytics and data integration.
3.1. Kafka Architecture
Kafka is a distributed system consisting of servers and clients that communicate using a binary TCP-based protocol. It’s meant to run as a cluster of one or more servers, also known as brokers. The brokers also act as the storage layer for events.
Kafka organizes events durably in topics. Topics can have zero, one, or many producers and consumers. Topics are also partitioned and spread across different brokers for high scalability. Further, every topic can also be replicated across the cluster:
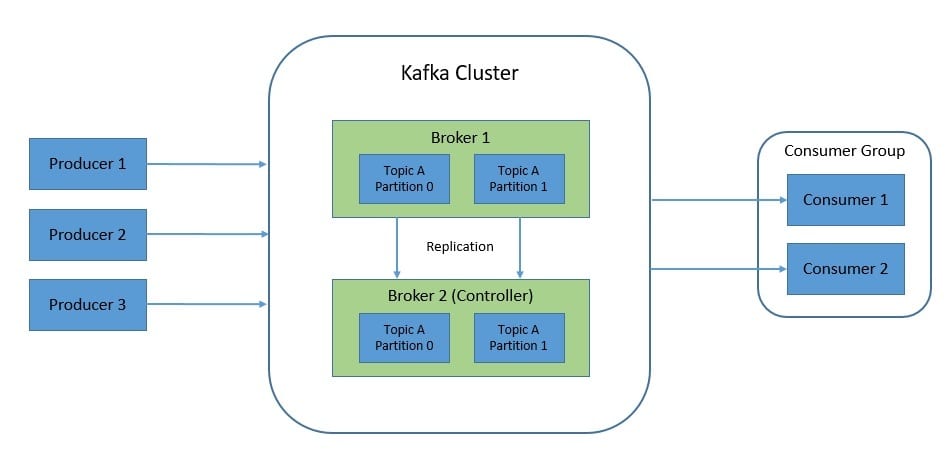
In the Kafka cluster, one of the brokers serves as the controller. The controller is responsible for managing the states of partitions and replicas and for performing administrative tasks like reassigning partitions. At any point in time, there can only be one controller in the cluster.
The clients enable applications to read, write, and process streams of events in parallel, at scale, and in a fault-tolerant manner. Producers are the client applications that publish events to Kafka. At the same time, consumers are those that subscribe to these events from Kafka.
3.2. The Role of ZooKeeper
The design attributes of Kafka make it highly available and fault-tolerant. But, being a distributed system, Kafka requires a mechanism for coordinating multiple decisions between all the active brokers. It also requires maintaining a consistent view of the cluster and its configurations. Kafka has been using ZooKeeper to achieve this for a long time now.
Basically, until the recent change to Kraft, ZooKeeper has been serving as the metadata management tool for Kafka to accomplish several key functions: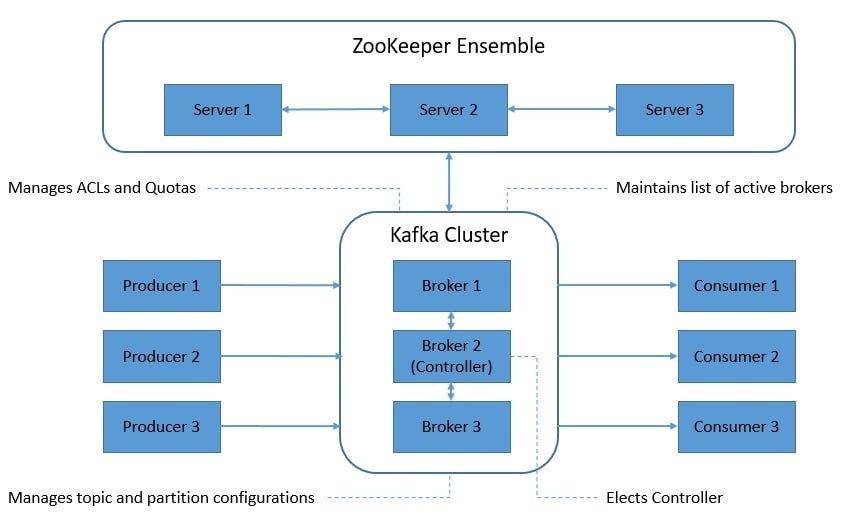
- Controller Election: The controller election relies heavily on ZooKeeper. To elect the controller, each broker attempts to create an ephemeral node in ZooKeeper. The first broker to create this ephemeral node assumes the controller role and is assigned a controller epoch.
- Cluster Membership: ZooKeeper plays an important role in managing the membership of brokers in a cluster. When a broker connects to ZooKeeper instances, an ephemeral znode is created under a group znode. This ephemeral znode gets deleted if the broker fails.
- Topic Configuration: Kafka maintains a set of configurations for each topic in ZooKeeper. These configurations can be per-topic or global. It also stores details like the list of existing topics, the number of partitions for each topic, and the location of replicas.
- Access Control Lists (ACLs): Kafka also maintains the ACLs for all topics in ZooKeeper. This helps decide who or what is allowed to read or write on each topic. It also holds information like the list of consumer groups and members of each consumer group.
- Quotas: Kafka brokers can control broker resources that a client can utilize. This is stored in ZooKeeper as quotas. There are two types of quotas: network bandwidth quota defined by byte-rate threshold and request rate quota defined by CPU utilization threshold.
3.3. Problems with ZooKeeper
As we’ve seen so far, ZooKeeper has played an important role quite successfully in the Kafka architecture for a long time. So, why did they decide to change it? To put it in plain and simple words, ZooKeeper adds an extra management layer for Kafka. Managing distributed systems is a complex task, even if it’s as simple and robust as ZooKeeper.
Kafka isn’t the only distributed system that requires a mechanism to coordinate tasks across its members. There are several others, like MongoDB, Cassandra, and Elasticsearch, all of which solve this problem in their own ways. However, they don’t depend on an external tool like ZooKeeper for metadata management. Basically, they depend on internal mechanisms for this purpose.
Apart from other benefits, it makes deployment and operations management much simpler. Imagine if we had to manage just one distributed system instead of two! Moreover, this also improves the scalability due to the more efficient metadata handling. Storing metadata internally within Kafka instead of ZooKeeper makes managing it easier and provides better guarantees.
4. Kafka Raft (Kraft) Protocol
Inspired by the complexity of Kafka with ZooKeeper, a Kafka Improvement Proposal (KIP) was submitted to replace ZooKeeper with a self-managed metadata quorum. While the base KIP 500 defined the vision, it was followed by several KIPs to hash out the details. The self-managed mode was first made available as the early access release as part of Kafka 2.8.
The self-managed mode consolidates the responsibility of metadata management within Kafka. This mode makes use of a new quorum controller service in Kafka. The quorum controller uses an event-sourced storage model. Further, it uses Kafka Raft (Kraft) as the consensus protocol to ensure that the metadata is accurately replicated across the quorum.
Kraft is basically an event-based variant of the Raft consensus protocol. It’s also similar to the ZAB protocol, with a notable difference being that it uses an event-driven architecture. The quorum controller uses an event log to store the state, which is periodically abridged to snapshots to prevent it from growing indefinitely:
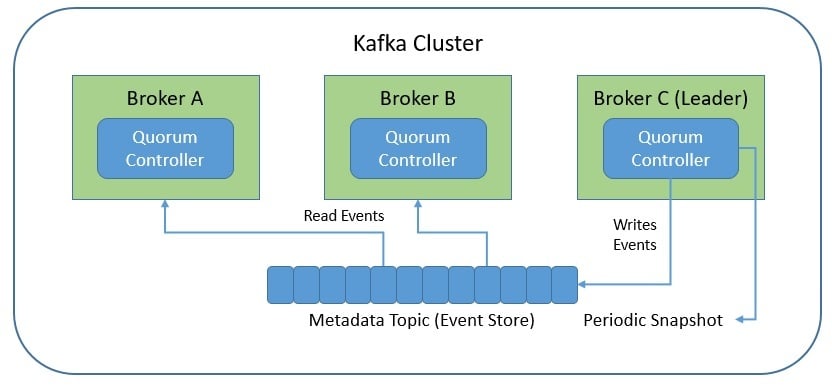
One of the quorum controllers acts as the leader and creates events in the metadata topic within Kafka. The other controllers within the quorum follow the leader controller by responding to these events. When one of the brokers fails due to partitioning, it can catch up on the missed events from the log upon rejoining. This reduces the unavailability window.
Unlike the ZooKeeper-based controller, the quorum controller doesn’t need to load the state from ZooKeeper. When the leadership changes, the new active controller already has all the committed metadata records in memory. Moreover, the same event-driven mechanism is also used to track all metadata across the cluster.
5. A Simplified and Better Kafka!
Change to the quorum-based controller is supposed to bring significant relief to the Kafka community. To begin with, system administrators will find it easier to monitor, administer, and support Kafka. Developers will have to deal with a single security model for the whole system. Moreover, we have a lightweight single-process deployment to get started with Kafka.
The new metadata management also significantly improves the control plane performance of Kafka. To begin with, it allows the controller to failover much faster. The ZooKeeper-based metadata management has been a bottleneck for cluster-wide partition limits. The new quorum controller is designed to handle a much larger number of partitions per cluster.
Since Kafka version 2.8, the self-managed (Kraft) mode is available alongside ZooKeeper. It was released as a preview feature in version 3.0. Finally, with several improvements, it has been declared production ready in version 3.3.1. Kafka may possibly deprecate ZooKeeper in version 3.4. However, it’s safe to say that the experience of using Kafka has significantly improved!
6. Conclusion
In this article, we discussed the details of ZooKeeper and the role it plays in Kafka. Further, we went through the complexities of this architecture and why Kafka has chosen to replace ZooKeeper with a quorum-based controller.
Finally, we covered the benefits this change brings to Kafka in terms of simplified architecture and better scalability.

















