

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In a fast-paced world like ours, building fast and scalable analytics feels harder than it should be. While traditional databases struggle with large-scale queries, many modern data stacks require us to integrate multiple systems to achieve real-time performance. The result? Complex, brittle, and expensive to maintain.
With Apache Doris, we now have a comprehensive solution as a high-performance analytical database. In this tutorial, we’ll explore what makes Doris different, how it works, the ecosystem and tooling, and whether it deserves a place in your data stack.
Apache Doris is an open-source, distributed analytical database designed to deliver sub-second query performance on large datasets with relatively high concurrency.
Importantly, it supports standard SQL and is MySQL-compatible. It also enables real-time reporting and dashboards, and supports analytics-heavy applications.
Unlike general-purpose databases or heavyweight data warehouses, Doris is purpose-built for Online Analytical Processing (OLAP), specifically for scenarios where speed, simplicity, and scale all matter at once.
In traditional analytics setups, we subscribe to stitching together multiple tools: a data warehouse (e.g., Snowflake), a batch ETL pipeline, a cache layer, and a serving layer.
Following this, we experience a lag between ingestion and gaining insights, resulting in significant engineering overhead requirements to manage schema synchronizations, address latency issues, and optimize query performance.
Apache Doris collapses that stack by providing:
As a result, we have a system that enables us to ingest and serve data quickly, without the need for complex data pipelines or caching layers.
Additionally, while alternatives like Clickhouse and Druid offer excellent performance, they feature steep learning curves, operational complexities, or specific tradeoffs around ingestion, indexing, or join support.
Apache Doris is best used in scenarios where low-latency analytics on high-volume data is a core requirement.
For organizations that require dashboards to reflect the most recent activity, from sales data and application metrics to operational KPIs, Doris supports real-time data ingestion from sources like Kafka and Flink.
Also, materialized views help optimize query performance for frequent patterns, such as aggregations over sliding time windows.
Logs and events are known to generate massive volumes of semi-structured data. As we already established, traditional databases struggle to process them efficiently, especially when filtered and grouped by time, status codes, user IDs, or paths.
Moreover, due to Doris’s columnar storage and vectorized engine, we can experience fast queries across billions of records, making it ideal for applications such as web and app telemetry analysis, security event monitoring, and API usage tracking.
Because SaaS platforms provide analytics to hundreds or thousands of customers, each with their data segments, Doris handles multi-tenancy querying at scale. It offers sufficient support for:
Furthermore, features like embedded analytics, exportable reports, and drill-down dashboards can be enabled all from the same engine.
In most cases where internal teams in organizations rely on tools like Superset, Tableau, or Metabase, Doris acts as a performant SQL backend that doesn’t require heavy tuning.
Therefore, analysts can now run complex joins, filter down large datasets, or explore metrics interactively without writing custom pipelines or waiting on data engineering teams.
Apache Doris boasts its speed, scalability, and simplicity due to its foundation on a distributed architecture, columnar storage engine, and vectorized model.
The Doris system consists of two main components: Frontend (FE) nodes and Backend (BE) nodes. Due to this separation, Doris can distribute responsibilities and enable horizontal scaling as workloads increase.
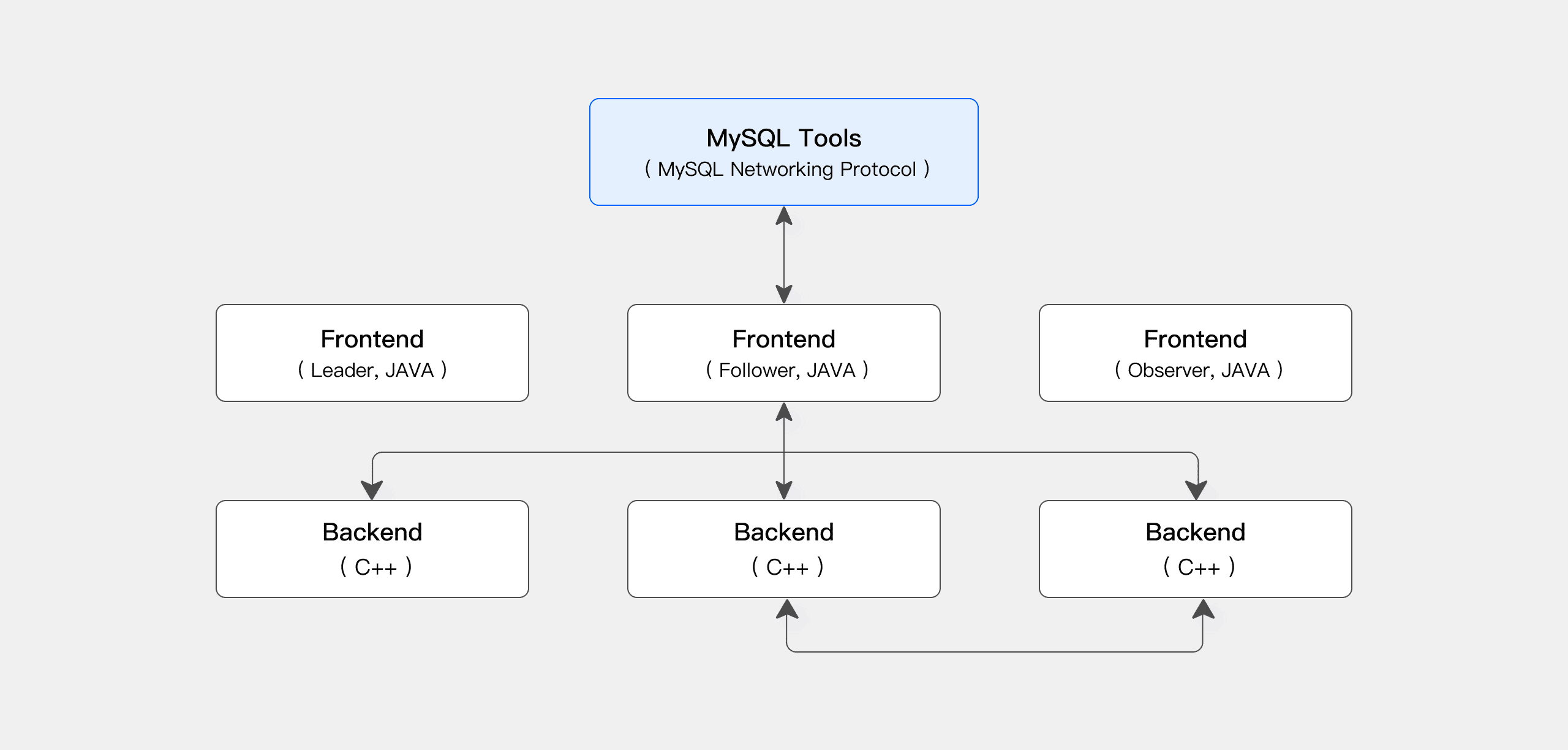
Frontend nodes handle all client interaction and coordinate with other frontend nodes to ensure consistency in the cluster. Essentially, they are responsible for parsing SQL, generating optimized execution plans, managing metadata, and orchestrating query execution.
Conversely, at the backend node, the actual work takes place. Here, they store data, execute query fragments, perform aggregation, and return results. Each BE is designed to operate independently on its local data, allowing for parallelism across nodes and directly contributing to Doris’s performance.
The interesting part? As our system grows, we can scale FEs to handle more concurrent users and BEs to handle more data and compute, all without changing the application layer.
Doris uses a columnar storage format optimized for OLAP workloads:
Each segment is built to be immutable, which simplifies consistency and enables faster reads. Therefore, updates are written as new segments using techniques similar to LSM-trees (Log-Structured Merge trees).
A major feature of Doris is its vectorized execution engine. Moving far away from obsolete concepts of processing data one row at a time, Doris operates on batches of columnar data called vectors or blocks. As a result, CPU efficiency and cache locality are improved, reducing the overhead of query execution.
Vectorized execution allows:
In addition, vectorized execution, when combined with Doris’s columnar format, enables the processing of wide analytical queries with impressive speed.
Deploying Apache Doris in a production environment involves a combination of efforts in monitoring performance, managing storage efficiently, and ensuring high availability of both FE and BE nodes.
To ensure high availability and fault tolerance in production clusters, we need to run at least three FEs and three BEs with data replication. With this setup, the system can automatically recover from node failures and supports rolling upgrades without downtime.
Doris stores data locally on disk and continuously runs compaction processes to merge data files and optimize query performance. Due to this structure, these background tasks can temporarily increase resource usage; therefore, it’s important to monitor disk I/O and compaction health.
Consequently, using SSDs is highly recommended for better throughput and lower latency. Additionally, by implementing proper data retention policies, such as a time-to-live (TTL) for old data, we can maintain cluster hygiene and prevent storage from growing uncontrollably.
To aid monitoring, Doris exposes metrics compatible with Prometheus and Grafana, which makes it easy to track key indicators:
Similarly, logs from FE and BE nodes provide valuable information for diagnosing failures or configuration issues. Additionally, with the built-in Web UI, we have a more convenient overview of cluster health and tablet statuses, enabling us to spot problems early.
Through basic controls provided in Doris, we can manage memory usage and query concurrency, including admission control and resource tagging.
While Doris may not provide fine-grained multi-tenant isolation like some systems, these features help prevent any single user or workload from overwhelming cluster resources, especially for shared environments with diverse analytics workloads.
In this article, we explored how Apache Doris addresses the challenges of real-time, high-performance analytics. We examined its architecture, columnar storage engine, and vectorized execution, which are all key features that enable fast, scalable query performance.
Finally, we looked at practical considerations for operating Doris in production, from cluster setup to monitoring.