Using Transactions for Read-Only Operations
Last updated: September 5, 2024


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
In this article, we’ll discuss read-only transactions. We’ll talk about their purpose and how to use them, as well as check some of their nuances related to performance and optimization. For the sake of simplicity, we’ll focus on MySQL’s InnoDB engine. But, keep in mind that some of the information described can change depending on the database/storage engine.
2. What Is a Transaction?
A transaction is an atomic operation that consists of one or more statements. It’s atomic because all statements within this operation either succeed (are committed) or fail (are rolled back), which means all or nothing. The letter ‘A’ of the ACID properties represents the atomicity of transactions.
Another critical thing to understand is that all statements in the InnoDB engine become a transaction, if not explicitly, then implicitly. Such a concept gets a lot harder to understand when we add concurrency to the equation. Then, we need to clarify another ACID property, the ‘I’ of Isolation.
Understanding the isolation level property is essential for us to be able to reason about trade-offs of performance vs. consistency guarantees. However, before going into details about isolation level, remember that as all the statements in InnoDB are transactions, they can be committed or rolled back. If no transaction is specified, the database creates one, and based on the autocommit property, it may be committed or not.
2.1. Isolation Levels
For the article, we’ll assume the default one from MySQL — repeatable read. It provides a consistent read within the same transaction, which means that the first read will establish a snapshot (point in time), and all subsequent reads will be consistent with respect to each other. We can refer to the MySQL official documentation for more information about it. Of course, keeping such snapshots has its consequences but guarantees a good consistency level.
Different databases may have other names or isolation level options, but most likely, they’ll be similar.
3. Why and Where to Use a Transaction?
Now that we understand better what a transaction is and its different properties let’s talk about read-only transactions. As explained earlier, in the InnoDB engine, all statements are transactions, and therefore, they may involve things like locking and snapshots. However, we can see that some of the overhead related to transaction coordination, such as marking rows with transaction IDs and other internal structures, may not be necessary for plain queries. That’s where read-only transactions come into play.
We can explicitly define a read-only transaction using the syntax START TRANSACTION READ ONLY. MySQL also tries to detect read-only transitions automatically. But further optimizations can be applied when declaring one explicitly. Read intense applications can leverage those optimizations and save resource utilization on our database cluster.
3.1. Application vs. Database
We need to know that dealing with persistence layers in our application may involve many layers of abstractions. Each of those layers has a different responsibility. However, to simplify, let’s say that in the end, those layers impact either how our application deals with the database or how the database deals with the data manipulation.
Of course, not all applications have all those layers, but it represents a good generalization. Assuming we have a Spring application, in short, these layers serve the purpose of:
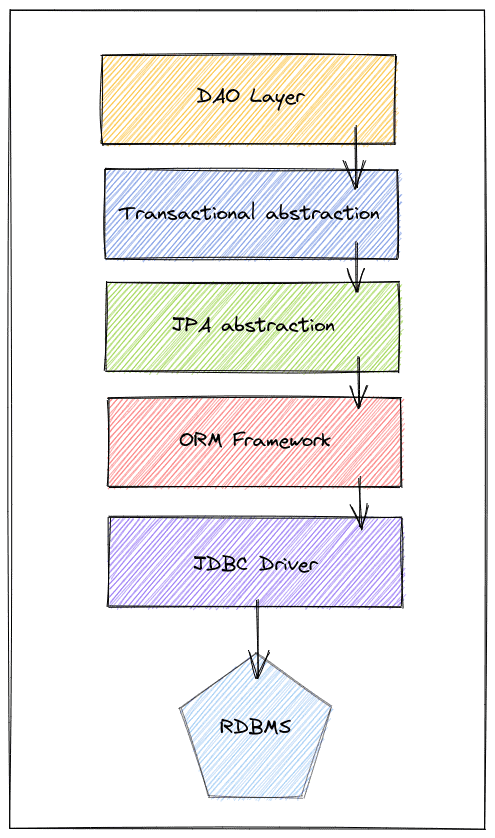
- DAO: Acts as a bridge between business logic and persistence nuances
- Transactional abstraction: Takes care of the application level complexity of transactions (Begin, Commit, Rollback)
- JPA Abstraction: Java specification that offers a standard API between vendors
- ORM Framework: The actual implementation behind JPA (for example, Hibernate)
- JDBC: Responsible for actually communicating with the database
The main takeaway is that many of those factors may affect how our transactions behave. Nonetheless, let’s focus on a particular property group that directly impacts this behavior. Usually, clients can define those properties at the global or session level. The list of all properties is extensive, so we’ll only discuss two of them that are crucial. However, we should be familiar with them already.
3.2. Transaction Management
The way the JDBC driver starts a transaction from the application side is by turning off the autocommit property. It’s the equivalent of a BEGIN TRANSACTION statement, and from that moment on, all the following statements must be committed or rolled back in order to finish the transaction.
Defined at the global level, this property tells the database to treat all the incoming requests as manual transactions and requires the user to commit or roll back. However, this is no longer valid if the user overrides this definition at the session-level. As a result, many drivers turn this property off by default to guarantee consistent behavior and ensure the application has control over it.
Next, we can use the transaction property to define if write operations are allowed or not. But there’s a caveat: Even in a read-only transaction, it’s possible to manipulate tables created using the TEMPORARY keyword. This property also has global and session scope, though we normally deal with this and other properties at the session level in our applications.
A caveat is that when using connection pools, due to the nature of opening connections and reusing them. The frameworks or libraries dealing with transactions and connections, have to ensure that the sessions are in a clean state before starting a new transaction.
For this reason, a few statements may be executed to discard any remaining pending changes and make the session set up properly.
We already saw that read-heavy applications could leverage read-only transactions to optimize and save resources in our database cluster. But, many developers also forget that switching between setups also causes round-trips to the database, affecting the throughput of the connections.
In MySQL, we can define those properties at the global level as:
SET GLOBAL TRANSACTION READ WRITE;
SET autocommit = 0;
/* transaction */
commit;
Or, we can set the properties at the session level:
SET SESSION TRANSACTION READ ONLY;
SET autocommit = 1;
/* transaction */
3.3. Hints
In the case of transactions that only execute one query, enabling the autocommit property may save us round-trips. If that’s the most common cause in our application, using a separate data source set as read-only and having autocommit enabled by default will work even better.
Now, if transactions have more queries, we should use an explicit read-only transaction. Creating a read-only data source can also help save round trips by avoiding the switch between write and read-only transactions. But, if we have mixed workloads, the complexity of managing a new data source may not justify itself.
Another important point when dealing with a transaction with multiple statements is to consider the behavior determined by the isolation level, as it can change our transaction’s result and maybe impact performance. For the sake of simplicity, we’ll only consider the default one (repeatable read) during our examples.
4. Putting It Into Practice
Now, from the application side, we’ll try to understand how to deal with those properties and which layers can access such behavior. But, again, it’s clear that there are many different ways of doing it, and depending on the framework, this may change. Therefore, taking JPA and Spring as an example, we can have a good understanding of what it would look like in other situations as well.
4.1. JPA
Let’s see how we can effectively define a read-only transaction in our application using JPA/Hibernate:
EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("jpa-unit");
EntityManager entityManager = entityManagerFactory.createEntityManager();
entityManager.unwrap(Session.class).setDefaultReadOnly(true);
entityManager.getTransaction().begin();
entityManager.find(Book.class, id);
entityManager.getTransaction().commit();
It’s important noticing that there’s no standard way to define a read-only transaction in JPA. For that reason, we needed to get the actual Hibernate session to define it as read-only.
4.2. JPA+Spring
When using the Spring transaction management system, it gets even more straightforward as we see next:
@Transactional(readOnly = true)
public Book getBookById(long id) {
return entityManagerFactory.createEntityManager().find(Book.class, id);
}By doing this, Spring takes on the responsibility of opening, closing, and defining the transaction mode. However, even this is sometimes unnecessary as when using Spring Data JPA, we already have such configuration ready.
The Spring JPA repository base class marks all the methods as read-only transactions. By adding this annotation at the class level, the behavior of the methods can change by just adding the @Transactional at the method level.
Last, it’s also possible to define the read-only connection and change the autcommit property when configuring our data source. As we saw, this can further improve the application’s performance if we only need reads. The data source holds those configurations:
@Bean
public DataSource readOnlyDataSource() {
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost/baeldung?useUnicode=true&characterEncoding=UTF-8");
config.setUsername("baeldung");
config.setPassword("baeldung");
config.setReadOnly(true);
config.setAutoCommit(true);
return new HikariDataSource(config);
}However, this only makes sense in scenarios where the predominant characteristic of our application is single query resources. Also, if using Spring Data JPA, it’s necessary to disable the default transactions created by Spring. Therefore, we only need to configure the enableDefaultTransactions property to false:
@Configuration
@EnableJpaRepositories(enableDefaultTransactions = false)
@EnableTransactionManagement
public class Config {
//Definition of data sources and other persistence related beans
}From this moment, we have complete control and responsibility to add the @Transactional(readOnly=true) when necessary. Nonetheless, this is not the case for the majority of the application, so we shouldn’t change those configurations unless we’re sure that our application will profit from them.
4.3. Routing Statements
In a more real-life scenario, we could have two data sources, a writer one and a read-only one. Then, we’d have to define which data source to use at the component level. This approach handles the read connections more efficiently and prevents the unnecessary commands used to ensure the session is clean and has the appropriate setup.
There are multiple ways to reach this outcome, but we’ll first create a router data source class:
public class RoutingDS extends AbstractRoutingDataSource {
public RoutingDS(DataSource writer, DataSource reader) {
Map<Object, Object> dataSources = new HashMap<>();
dataSources.put("writer", writer);
dataSources.put("reader", reader);
setTargetDataSources(dataSources);
}
@Override
protected Object determineCurrentLookupKey() {
return ReadOnlyContext.isReadOnly() ? "reader" : "writer";
}
}
There’s a lot more to know about routing data sources. However, to sum up, in our case, this class will return the appropriate data source when the application requests it. To do that, we use the ReadOnlyContent class that will hold the data source context at runtime:
public class ReadOnlyContext {
private static final ThreadLocal<AtomicInteger> READ_ONLY_LEVEL = ThreadLocal.withInitial(() -> new AtomicInteger(0));
//default constructor
public static boolean isReadOnly() {
return READ_ONLY_LEVEL.get()
.get() > 0;
}
public static void enter() {
READ_ONLY_LEVEL.get()
.incrementAndGet();
}
public static void exit() {
READ_ONLY_LEVEL.get()
.decrementAndGet();
}
}Next, we need to define those data sources and register them in the Spring context. For this, we only need to use the RoutingDS class created previously:
//annotations mentioned previously
public Config {
//other beans...
@Bean
public DataSource routingDataSource() {
return new RoutingDS(
dataSource(false, false),
dataSource(true, true)
);
}
private DataSource dataSource(boolean readOnly, boolean isAutoCommit) {
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost/baeldung?useUnicode=true&characterEncoding=UTF-8");
config.setUsername("baeldung");
config.setPassword("baeldung");
config.setReadOnly(readOnly);
config.setAutoCommit(isAutoCommit);
return new HikariDataSource(config);
}
// other beans...
}Almost there — now, let’s create an annotation to tell Spring when to wrap a component in a read-only context. For this, we’ll use the @ReaderDS annotation:
@Inherited
@Retention(RetentionPolicy.RUNTIME)
public @interface ReaderDS {
}Last, we use AOP to wrap the component execution within the context:
@Aspect
@Component
public class ReadOnlyInterception {
@Around("@annotation(com.baeldung.readonlytransactions.mysql.spring.ReaderDS)")
public Object aroundMethod(ProceedingJoinPoint joinPoint) throws Throwable {
try {
ReadOnlyContext.enter();
return joinPoint.proceed();
} finally {
ReadOnlyContext.exit();
}
}
}
Usually, we want to add the annotation at the highest point level possible. Still, to make it simple, we’ll add the repository layer, and there’s only a single query in the component:
public interface BookRepository extends JpaRepository<BookEntity, Long> {
@ReaderDS
@Query("Select t from BookEntity t where t.id = ?1")
BookEntity get(Long id);
}As we can observe, this setup allows us to more efficiently deal with read-only operations by leveraging entire read-only transactions and avoiding the session context switch. As a result, this can considerably increase our application’s throughput and responsiveness.
5. Conclusion
In this article, we looked at read-only transactions and their benefits. We also understood how the MySQL InnoDB engine deals with them and how to configure the main properties that affect our application’s transactions. Furthermore, we discussed the possibilities of additional improvements by using dedicated resources like dedicated data sources.

















