When to Use the getReferenceById() and findById() Methods in Spring Data JPA
Last updated: June 3, 2026


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
All Access is finally out, with all of my Spring courses. Learn JUnit is out as well, and Learn Maven is coming fast. And, of course, quite a bit more affordable. Finally.
>> GET THE COURSESpring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
JpaRepository provides us with basic methods for CRUD operations. However, some of them are not so straightforward, and sometimes, it’s hard to identify which method would be the best for a given situation.
getReferenceById(ID) and findById(ID) are the methods that often create such confusion. These methods are new API names for getOne(ID), findOne(ID), and getById(ID).
In this tutorial, we’ll learn the difference between them and find the situation when each might be more suitable.
2. findById()
Let’s start with the simplest one out of these two methods. This method does what it says, and usually, developers don’t have any issues with it. It simply finds an entity in a repository given a specific ID:
@Override
Optional<T> findById(ID id);
The method returns an Optional. Thus, assuming it would be empty if we passed a non-existent ID is correct.
The method uses eager loading under the hood, so we’ll send a request to our database whenever we call this method. Let’s check an example:
public User findUser(long id) {
log.info("Before requesting a user in a findUser method");
Optional<User> optionalUser = repository.findById(id);
log.info("After requesting a user in a findUser method");
User user = optionalUser.orElse(null);
log.info("After unwrapping an optional in a findUser method");
return user;
}This method will generate the following logs:
[2023-12-27 12:56:32,506]-[main] INFO com.baeldung.spring.data.persistence.findvsget.service.SimpleUserService - Before requesting a user in a findUser method
[2023-12-27 12:56:32,508]-[main] DEBUG org.hibernate.SQL -
select
user0_."id" as id1_0_0_,
user0_."first_name" as first_na2_0_0_,
user0_."second_name" as second_n3_0_0_
from
"users" user0_
where
user0_."id"=?
[2023-12-27 12:56:32,508]-[main] TRACE org.hibernate.type.descriptor.sql.BasicBinder - binding parameter [1] as [BIGINT] - [1]
[2023-12-27 12:56:32,510]-[main] INFO com.baeldung.spring.data.persistence.findvsget.service.SimpleUserService - After requesting a user in a findUser method
[2023-12-27 12:56:32,510]-[main] INFO com.baeldung.spring.data.persistence.findvsget.service.SimpleUserService - After unwrapping an optional in a findUser methodSpring might batch requests in a transaction but will always execute them. Overall, findById(ID) doesn’t try to surprise us and does what we expect from it. However, the confusion arises because it has a counterpart that does something similar.
3. getReferenceById()
This method has a similar signature to findById(ID):
@Override
T getReferenceById(ID id);
Judging by the signature alone, we can assume that this method would throw an exception if the entity doesn’t exist. It’s true, but it’s not the only difference we have. The main difference between these methods is that getReferenceById(ID) is lazy. Spring won’t send a database request until we explicitly try to use the entity within a transaction.
3.1. Transactions
Each transaction has a dedicated persistence context it works with. Sometimes, we can expand the persistence context outside the transaction scope, but it’s not common and useful only for specific scenarios. Let’s check how the persistence context behaves regarding the transactions:
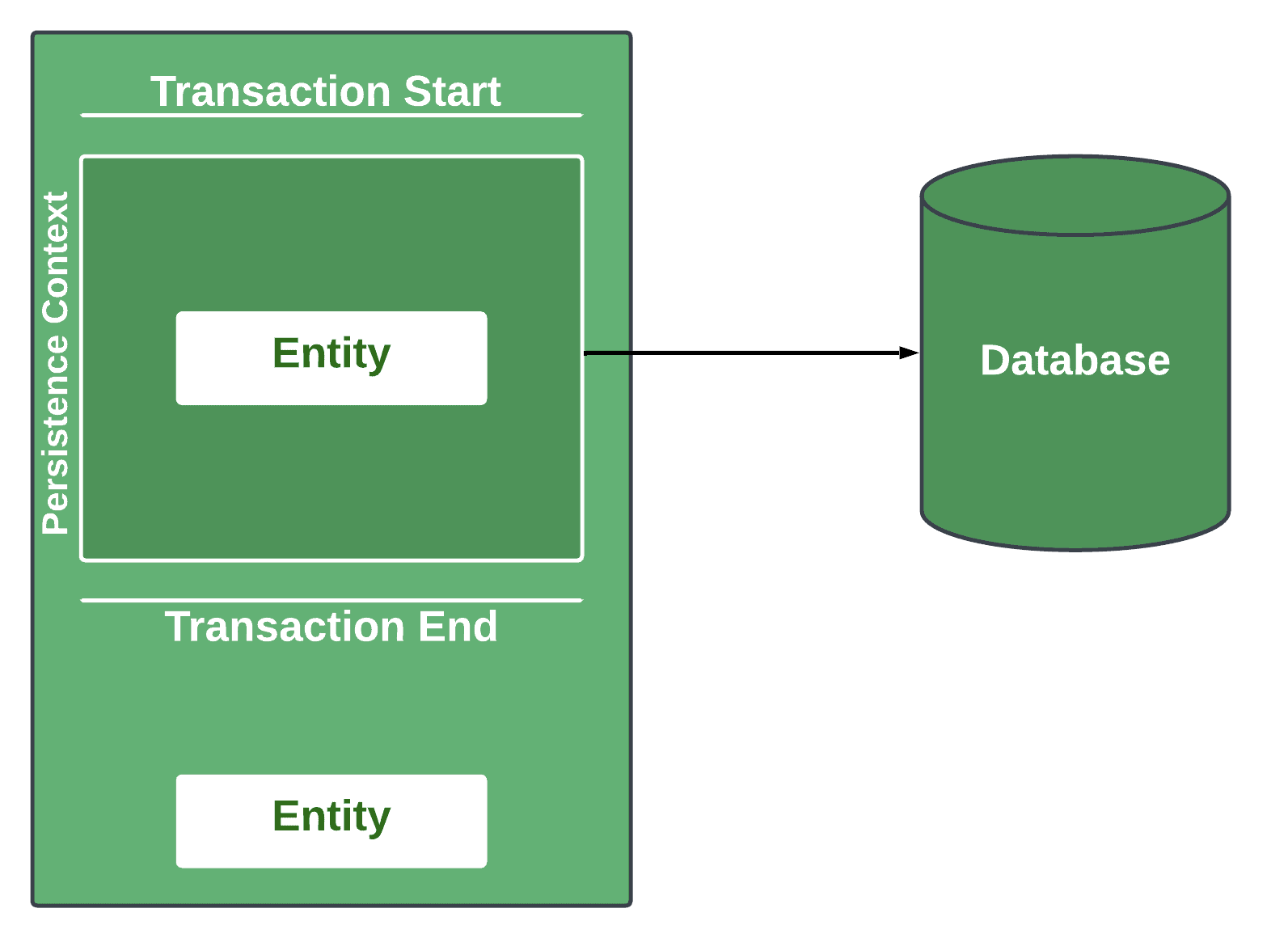
Within a transaction, all the entities inside the persistence context have a direct representation in the database. This is a managed state. Thus, all the changes to the entity will be reflected in the database. Outside the transaction, the entity moved to a detached state, and changes won’t be reflected until the entity is moved back to the managed state.
Lazy-loaded entities behave slightly differently. Spring won’t load them until we explicitly use them in the persistence context:
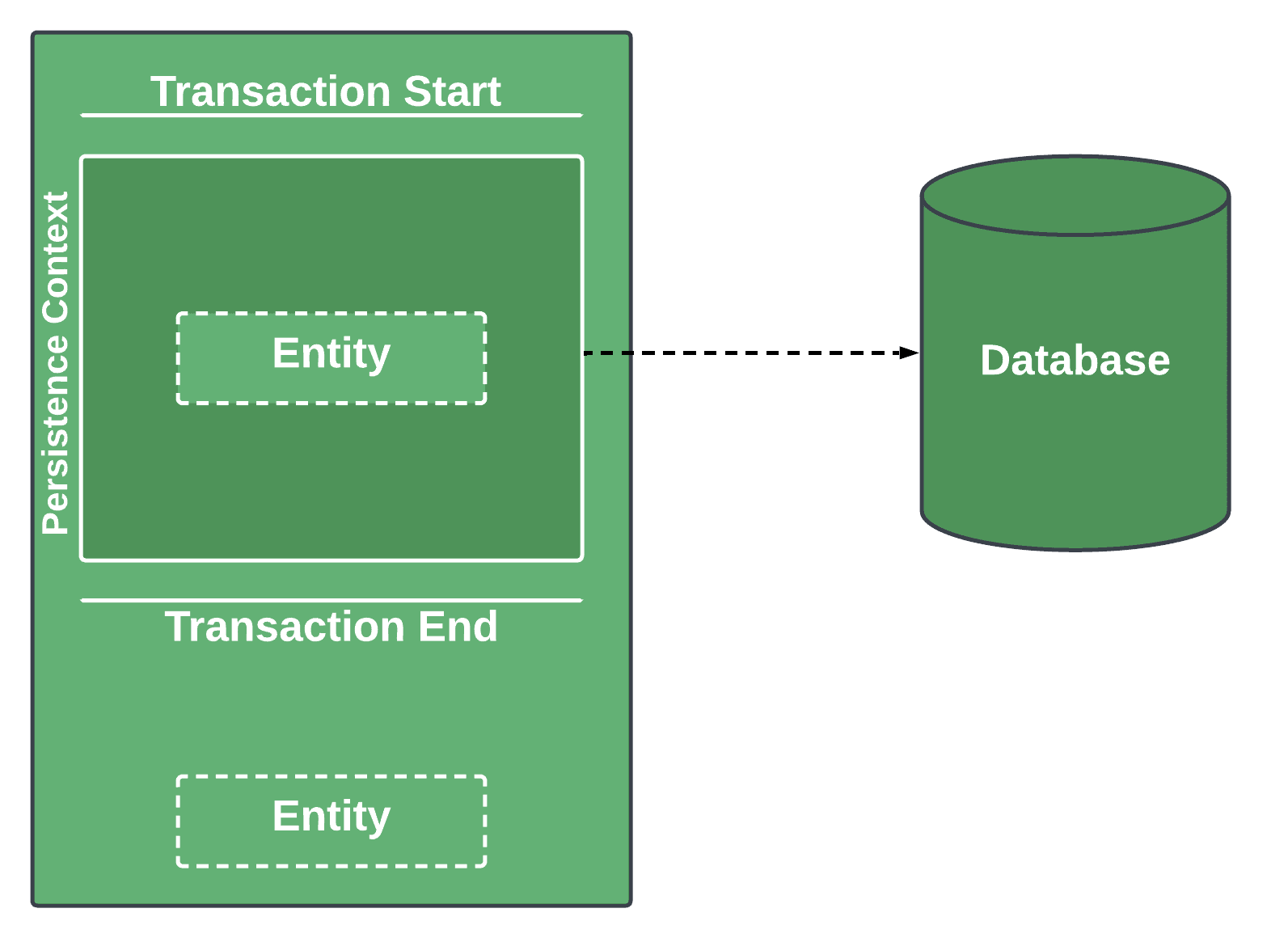 Spring will allocate an empty proxy placeholder to fetch the entity from the database lazily. However, if we don’t do this, the entity will remain an empty proxy outside the transaction, and any call to it will result in a LazyInitializationException. However, if we do call or interact with the entity in the way it will require the internal information, the actual request to the database will be made:
Spring will allocate an empty proxy placeholder to fetch the entity from the database lazily. However, if we don’t do this, the entity will remain an empty proxy outside the transaction, and any call to it will result in a LazyInitializationException. However, if we do call or interact with the entity in the way it will require the internal information, the actual request to the database will be made:
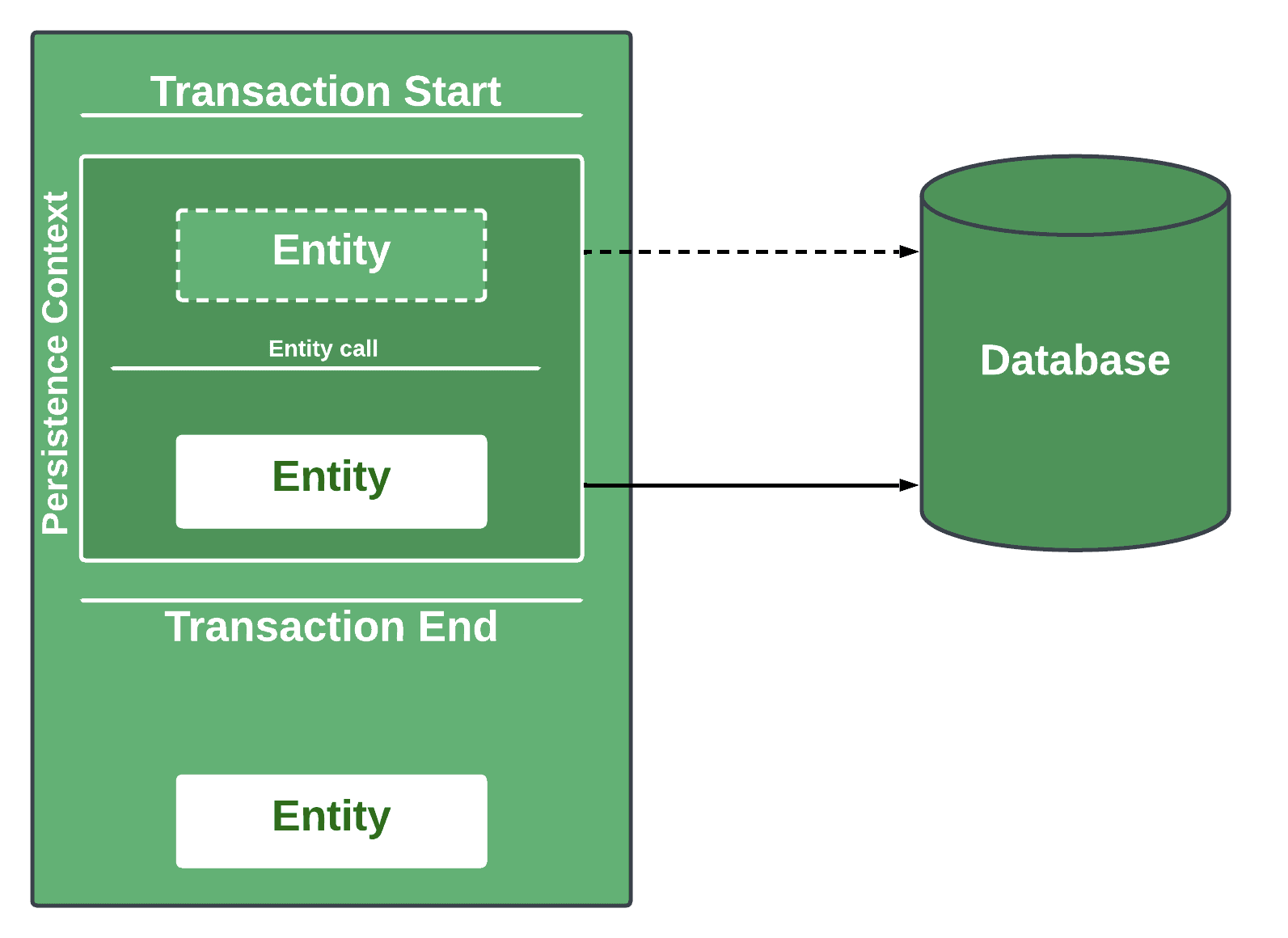
3.2. Non-transactional Services
Knowing the behavior of transactions and the persistence context, let’s check the following non-transactional service, which calls the repository. The findUserReference doesn’t have a persistence context connected to it, and getReferenceById will be executed in a separate transaction:
public User findUserReference(long id) {
log.info("Before requesting a user");
User user = repository.getReferenceById(id);
log.info("After requesting a user");
return user;
}This code will generate the following log output:
[2023-12-27 13:21:27,590]-[main] INFO com.baeldung.spring.data.persistence.findvsget.service.TransactionalUserReferenceService - Before requesting a user
[2023-12-27 13:21:27,590]-[main] INFO com.baeldung.spring.data.persistence.findvsget.service.TransactionalUserReferenceService - After requesting a userAs we can see, there’s no database request. After understanding the lazy loading, Spring assumes that we might not need it if we don’t use the entity within. Technically, we cannot use it because our only transaction is one inside the getReferenceById method. Thus, the user we returned will be an empty proxy, which will result in an exception if we access its internals:
public User findAndUseUserReference(long id) {
User user = repository.getReferenceById(id);
log.info("Before accessing a username");
String firstName = user.getFirstName();
log.info("This message shouldn't be displayed because of the thrown exception: {}", firstName);
return user;
}3.3. Transactional Service
Let’s check the behavior if we’re using a @Transactional service:
@Transactional
public User findUserReference(long id) {
log.info("Before requesting a user");
User user = repository.getReferenceById(id);
log.info("After requesting a user");
return user;
}This will give us a similar result for the same reason as in the previous example, as we don’t use the entity inside our transaction:
[2023-12-27 13:32:44,486]-[main] INFO com.baeldung.spring.data.persistence.findvsget.service.TransactionalUserReferenceService - Before requesting a user
[2023-12-27 13:32:44,486]-[main] INFO com.baeldung.spring.data.persistence.findvsget.service.TransactionalUserReferenceService - After requesting a userAlso, any attempts to interact with this user outside of this transactional service method would cause an exception:
@Test
void whenFindUserReferenceUsingOutsideServiceThenThrowsException() {
User user = transactionalService.findUserReference(EXISTING_ID);
assertThatExceptionOfType(LazyInitializationException.class)
.isThrownBy(user::getFirstName);
}However, now, the findUserReference method defines the scope of our transaction. This means that we can try to access the user in our service method, and it should cause the call to the database:
@Transactional
public User findAndUseUserReference(long id) {
User user = repository.getReferenceById(id);
log.info("Before accessing a username");
String firstName = user.getFirstName();
log.info("After accessing a username: {}", firstName);
return user;
}The code above would output the messages in the following order:
[2023-12-27 13:32:44,331]-[main] INFO com.baeldung.spring.data.persistence.findvsget.service.TransactionalUserReferenceService - Before accessing a username
[2023-12-27 13:32:44,331]-[main] DEBUG org.hibernate.SQL -
select
user0_."id" as id1_0_0_,
user0_."first_name" as first_na2_0_0_,
user0_."second_name" as second_n3_0_0_
from
"users" user0_
where
user0_."id"=?
[2023-12-27 13:32:44,331]-[main] TRACE org.hibernate.type.descriptor.sql.BasicBinder - binding parameter [1] as [BIGINT] - [1]
[2023-12-27 13:32:44,331]-[main] INFO com.baeldung.spring.data.persistence.findvsget.service.TransactionalUserReferenceService - After accessing a username: SaundraThe request to the database wasn’t made when we called getReferenceById(), but when we called user.getFirstName().
3.3. Transactional Service With a New Repository Transaction
Let’s check a bit more complex example. Imagine we have a repository method that creates a separate transaction whenever we call it:
@Override
@Transactional(propagation = Propagation.REQUIRES_NEW)
User getReferenceById(Long id);Propagation.REQUIRES_NEW means the outer transaction won’t propagate, and the repository method will create its persistence context. In this case, even if we use a transactional service, Spring will create two separate persistence contexts that won’t interact, and any attempts to use the user will cause an exception:
@Test
void whenFindUserReferenceUsingInsideServiceThenThrowsExceptionDueToSeparateTransactions() {
assertThatExceptionOfType(LazyInitializationException.class)
.isThrownBy(() -> transactionalServiceWithNewTransactionRepository.findAndUseUserReference(EXISTING_ID));
}We can use a couple of different propagation configurations to create more complex interactions between transactions, and they can yield different results.
3.4. Accessing Entities Without Fetching
Let’s consider a real-life scenario. Imagine that we have a Group class:
@Entity
@Table(name = "group")
public class Group {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToOne
private User administrator;
@OneToMany(mappedBy = "id")
private Set<User> users = new HashSet<>();
// getters, setters and other methods
}We want to add a user as an administrator to a group, and we can use either findById() or getReferenceById(). In this test, we get a user and make it an administrator of a new group using findById():
@Test
void givenEmptyGroup_whenAssigningAdministratorWithFindBy_thenAdditionalLookupHappens() {
Optional<User> optionalUser = userRepository.findById(1L);
assertThat(optionalUser).isPresent();
User user = optionalUser.get();
Group group = new Group();
group.setAdministrator(user);
groupRepository.save(group);
assertSelectCount(2);
assertInsertCount(1);
}It would be reasonable to assume that we should have one SELECT query, but we’re getting two. This happens because of additional ORM checks. Let’s do a similar operation but use getReferenceById() instead:
@Test
void givenEmptyGroup_whenAssigningAdministratorWithGetByReference_thenNoAdditionalLookupHappens() {
User user = userRepository.getReferenceById(1L);
Group group = new Group();
group.setAdministrator(user);
groupRepository.save(group);
assertSelectCount(0);
assertInsertCount(1);
}In this scenario, we don’t need additional information about a user; we only need an ID. Thus, we can use a placeholder that getReferenceById() conveniently provides us, and we have a single INSERT without additional SELECTs.
This way, the database takes care of the correctness of the data while mapping. For example, we get an exception while using an incorrect ID:
@Test
void givenEmptyGroup_whenAssigningIncorrectAdministratorWithGetByReference_thenErrorIsThrown() {
User user = userRepository.getReferenceById(-1L);
Group group = new Group();
group.setAdministrator(user);
assertThatExceptionOfType(DataIntegrityViolationException.class)
.isThrownBy(() -> {
groupRepository.save(group);
});
assertSelectCount(0);
assertInsertCount(1);
}At the same time, we still have a single INSERT without any SELECTs.
However, we cannot use the same approach for adding users as group members. Because we use Set, the equals(T) and hashCode() methods will be called. Hibernate throws an exception as getReferenceById() doesn’t fetch a real object:
@Test
void givenEmptyGroup_whenAddingUserWithGetByReference_thenTryToAccessInternalsAndThrowError() {
User user = userRepository.getReferenceById(1L);
Group group = new Group();
assertThatExceptionOfType(LazyInitializationException.class)
.isThrownBy(() -> {
group.addUser(user);
});
}Thus, the decision about an approach should consider the data types and the context where we use the entity.
4. Conclusion
The main difference between findById() and getReferenceById() is when they load the entities into the persistence context. Understanding this might help to implement optimizations and avoid unnecessary database lookups. This process is tightly connected to the transactions and their propagation. That’s why the relationships between transactions should be observed.

















