

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
All Access is finally out, with all of my Spring courses. Learn JUnit is out as well, and Learn Maven is coming fast. And, of course, quite a bit more affordable. Finally.
>> GET THE COURSESpring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Introduction
Standard advisors in Spring AI follow a single-pass model. A request flows through the advisor chain, reaches the LLM, and the response flows back. This works well for straightforward interactions, but falls short when we need iterative behavior — such as retrying a failed structured output or executing multiple tool calls in sequence.
Spring AI 1.1 introduces Recursive Advisors to solve this problem. A recursive advisor can loop through the downstream advisor chain multiple times, repeatedly calling the LLM until a specific condition is met.
In this tutorial, we’ll explore how recursive advisors work, examine the two built-in implementations, and build a custom recursive advisor.
2. Maven Dependencies
We use Spring Boot 3.5 with Spring AI 1.1.2. Spring AI 1.1 requires Spring Boot 3.4 or 3.5. For Spring Boot 4 support, Spring AI 2.0 is in development but currently only available as a milestone release (2.0.0-M2).
Our pom.xml includes the Spring AI BOM and the OpenAI Starter:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.1.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
</dependencies>We can swap the OpenAI starter for any supported provider without changing the advisor code.
3. How Recursive Advisors Work
A regular advisor processes a request exactly once. It hands the request down the chain, waits for the response, and passes it back. The flow is linear.
A recursive advisor breaks this single-pass model. It can evaluate the response and, if the result doesn’t meet a condition, loop back through the downstream part of the chain for another attempt. Each iteration triggers a fresh pass through all advisors below the recursive one — including another call to the LLM.
Two properties make this pattern work. First, only the advisors downstream of the recursive advisor re-execute on each loop. Advisors that sit upstream in the chain run only once, during the initial request. Second, downstream advisors still observe every iteration. A logging advisor placed after the recursive one, for example, captures each retry — preserving full observability.
Every recursive advisor must define a termination condition. Without a maximum attempt limit or an explicit exit criterion, the loop could run indefinitely, consuming tokens and incurring costs with every pass.
The following image shows how multiple recursive advisors work together in the chain: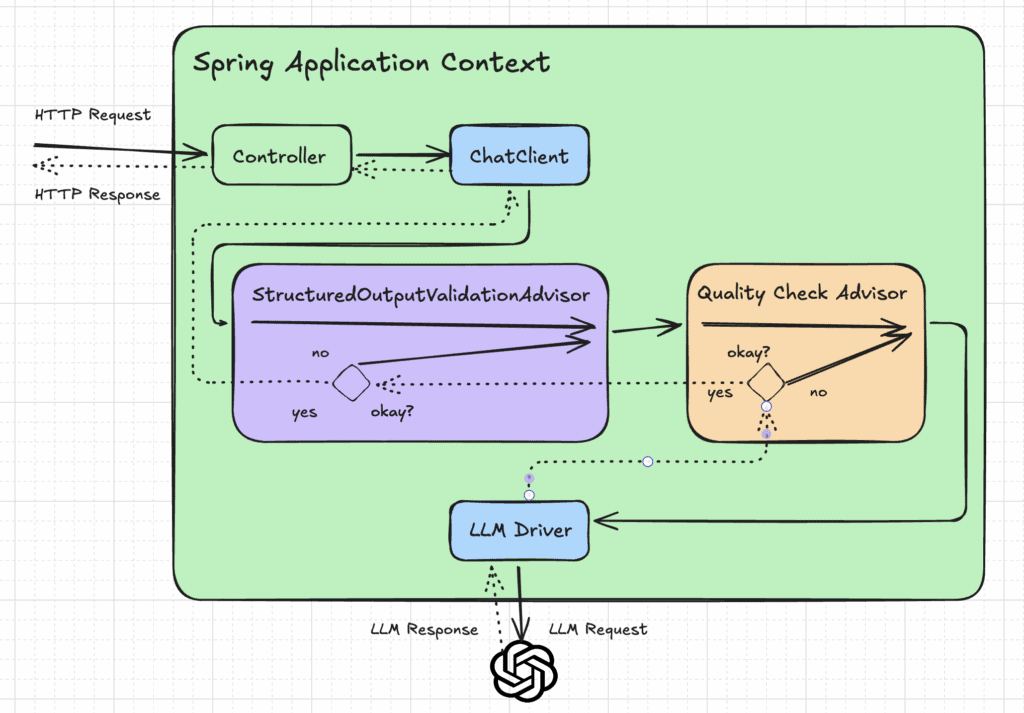
We could also implement iterative logic with an explicit while loop around ChatClient calls in application code. Recursive advisors keep this concern inside the chain, preserving observability and allowing other advisors to intercept each iteration.
4. Built-in Recursive Advisors
Spring AI ships two recursive advisors that cover the most common use cases.
4.1. ToolCallAdvisor
By default, Spring AI handles tool calling inside the ChatModel implementation. The ToolCallAdvisor moves this loop into the advisor chain, giving other advisors full visibility into each tool call round-trip.
Let’s say we have a currency conversion tool that accepts a CurrencyRequest record and returns the current exchange rate, like shown in this sample:
public record CurrencyRequest(String fromCurrency, String toCurrency) {}
var exchangeRateTool = FunctionToolCallback
.builder(
"getExchangeRate",
(CurrencyRequest req) -> "1 " + req.fromCurrency() + " = 0.91 " + req.toCurrency())
.description("Gets the current exchange rate between two currencies")
.inputType(CurrencyRequest.class)
.build();We can wire this tool together with the advisor into the ChatClient:
var toolCallAdvisor = ToolCallAdvisor
.builder()
.toolCallingManager(toolCallingManager)
.advisorOrder(BaseAdvisor.HIGHEST_PRECEDENCE + 300)
.build();
var chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(toolCallAdvisor)
.defaultToolCallbacks(exchangeRateTool)
.build();When the LLM’s response contains a tool call, the advisor executes it, feeds the result back into the prompt, and loops. This continues until the LLM returns a final text response with no further tool calls.
A following prompt may trigger the tool twice — once per currency pair:
String answer = chatClient
.prompt()
.user("Convert 500 USD to EUR and then to GBP")
.call()
.content();The advisor handles both iterations transparently. It also supports a “return direct” mode — when a tool sets returnDirect=true, the advisor skips the final LLM call and returns the tool output directly to the client.
4.2. StructuredOutputValidationAdvisor
This advisor ensures the LLM’s JSON output matches a schema derived from a Java record. If validation fails, it appends the error details to the prompt and retries.
Suppose we have a BookSummary record with title, author, and a list of themes:
public record BookSummary(String title, String author, List<String> themes) {}We configure the advisor with a maximum retry count of 5:
var validationAdvisor = StructuredOutputValidationAdvisor
.builder()
.outputType(BookSummary.class)
.maxRepeatAttempts(5)
.build();var chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(validationAdvisor)
.build()BookSummary result = chatClient
.prompt()
.user("Summarize '1984' by George Orwell with its main themes")
.call()
.entity(BookSummary.class);The configuration for maxRepeatAttempts is necessary to prevent infinite retry loops. The default value is 3.
5. Building a Custom Recursive Advisor
Let’s build a QualityCheckAdvisor that evaluates the LLM’s answer length and retries with feedback if it falls below a threshold. Our advisor implements the CallAdvisor interface:
public class QualityCheckAdvisor implements CallAdvisor {
private static final int MAX_RETRIES = 3;
// ...
}We define a hard retry limit. Every recursive advisor must include a termination condition to prevent runaway loops.
The core logic lives in the adviseCall method. We start by forwarding the request through the chain as usual:
@Override public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
ChatClientResponse response = chain.nextCall(request);
int attempts = 0;
while (attempts < MAX_RETRIES && !isHighQuality(response)) {
// ...
attempts++;
}
return response;
}As long as the response doesn’t meet our quality threshold, we augment the prompt with feedback and re-execute the downstream chain. The key call here is chain.copy(this).nextCall() — it creates a fresh sub-chain starting after this advisor:
String feedback = "Your previous answer was incomplete. " + "Please provide a more thorough response.";
var augmentedPrompt = request
.prompt()
.augmentUserMessage(
userMessage -> userMessage.mutate().text(userMessage.getText() + System.lineSeparator() + feedback)
.build());
var augmentedRequest = request
.mutate()
.prompt(augmentedPrompt)
.build();
response = chain
.copy(this)
.nextCall(augmentedRequest);The quality check itself is straightforward — we verify the response exceeds 200 characters:
private boolean isHighQuality(ChatClientResponse response) {
String content = response
.chatResponse()
.getResult()
.getOutput()
.getText();
return content != null && content.length() > 200;
}We register the advisor with the ChatClient:
var chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(new QualityCheckAdvisor())
.build();We should note that recursive advisors currently support only non-streaming mode. The advisor needs the complete response before deciding whether to retry.
6. Testing
Calling a real LLM in a unit test is non-deterministic and slow. We mock the ChatModel instead, controlling exactly what the advisor sees. This lets us verify the retry behavior in isolation.
The strategy is straightforward: we configure the mock to return a short response on the first call — too short to pass the quality check — and a sufficiently long response on the second call. If the advisor works correctly, it retries exactly once.
Here’s the sample test:
@SpringBootTest
class QualityCheckAdvisorTests {
@MockitoBean
ChatModel chatModel;
@Autowired
ChatClient.Builder chatClientBuilder;
@Test
void givenShortFirstResponse_whenAdvised_thenRetriesAndReturnsLongResponse() {
var shortResponse = "Too brief.";
var longResponse = "S".repeat(250);
when(chatModel.call(any(Prompt.class)))
.thenReturn(createChatResponse(shortResponse))
.thenReturn(createChatResponse(longResponse));
var chatClient = chatClientBuilder
.defaultAdvisors(new QualityCheckAdvisor())
.build();
String result = chatClient.prompt()
.user("Explain the SOLID principles.")
.call()
.content();
assertThat(result).hasSize(250);
verify(chatModel, times(2)).call(any(Prompt.class));
}
private ChatResponse createChatResponse(String content) {
return new ChatResponse(
List.of(new Generation(new AssistantMessage(content)))
);
}
}The verify() call is the key assertion. It proves the advisor triggered exactly one retry. The first call returned a response below the 200-character threshold, so the advisor looped. The second call satisfied the condition, and the advisor returned.
7. Performance and Ordering Considerations
Recursive advisors multiply the number of LLM calls. Each iteration increases cost, latency, and token consumption. The table below summarizes key trade-offs:
| Concern | Impact | Mitigation |
|---|---|---|
| API cost | Each loop iteration incurs an additional LLM call | Set strict retry limits |
| Latency | Multiple round-trips add up | Cache intermediate results where possible |
| Token usage | Full prompts are re-sent each iteration | Keep augmented prompts concise |
| Advisor ordering | Determines which advisors observe each iteration | Place recursive advisors early or late based on observability needs |
We should place recursive advisors intentionally in the chain. The ToolCallAdvisor is typically ordered near HIGHEST_PRECEDENCE so that inner advisors observe tool execution. The StructuredOutputValidationAdvisor sits near LOWEST_PRECEDENCE, so it runs last before the model call.
8. Conclusion
In this tutorial, we have learned how recursive advisors in Spring AI break the single-pass model to enable iterative retry patterns. They support use cases like tool calling loops, structured output validation, and custom quality checks — all within the familiar advisor abstraction.

















