

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In this tutorial, we’ll give an overview of what SirixDB is and its most important design goals.
Next, we’ll give a walk through a low level cursor-based transactional API.
2. SirixDB Features
SirixDB is a log-structured, temporal NoSQL document store, which stores evolutionary data. It never overwrites any data on-disk. Thus, we’re able to restore and query the full revision history of a resource in the database efficiently. SirixDB ensures, that a minimum of storage-overhead is created for each new revision.
Currently, SirixDB offers two built-in native data models, namely a binary XML store as well as a JSON store.
2.1. Design Goals
Some of the most important core principles and design goals are:
- Concurrency – SirixDB contains very few locks and aims to be as suitable for multithreaded systems as possible
- Asynchronous REST API – operations can happen independently; each transaction is bound to a specific revision and only one read-write transaction on a resource is permitted concurrently to N read-only transactions
- Versioning/Revision history – SirixDB stores a revision history of every resource in the database while keeping storage-overhead to a minimum. Read and write performance is tunable. It depends on the versioning type, which we can specify for creating a resource
- Data integrity – SirixDB, like ZFS, stores full checksums of the pages in the parent pages. That means that almost all data corruption can be detected upon reading in the future, as the SirixDB developers aim to partition and replicate databases in the future
- Copy-on-write semantics – similarly to the file systems Btrfs and ZFS, SirixDB uses CoW semantics, meaning that SirixDB never overwrites data. Instead, database page fragments are copied and written to a new location
- Per revision and per record versioning – SirixDB does not only version on a per-page, but also on a per-record basis. Thus, whenever we change a potentially small fraction
of records in a data page, it does not have to copy the whole page and write it to a new location on a disk or flash drive. Instead, we can specify one of several versioning strategies known from backup systems or a sliding snapshot algorithm during the creation of a database resource. The versioning type we specify is used by SirixDB to version data pages - Guaranteed atomicity (without a WAL) – the system will never enter an inconsistent state (unless there is hardware failure), meaning that unexpected power-off won’t ever damage the system. This is accomplished without the overhead of a write-ahead-log (WAL)
- Log-structured and SSD friendly – SirixDB batches writes and syncs everything sequentially to a flash drive during commits. It never overwrites committed data
We first want to introduce the low-level API exemplified with JSON data before switching our focus to higher levels in future articles. For instance an XQuery-API for querying both XML and JSON databases or an asynchronous, temporal RESTful API. We can basically use the same low-level API with subtle differences to store, traverse and compare XML resources as well.
In order to use SirixDB, we at least have to use Java 11.
3. Maven Dependency to Embed SirixDB
To follow the examples, we first have to include the sirix-core dependency, for instance, via Maven:
<dependency>
<groupId>io.sirix</groupId>
<artifactId>sirix-core</artifactId>
<version>0.9.3</version>
</dependency>Or via Gradle:
dependencies {
compile 'io.sirix:sirix-core:0.9.3'
}
4. Tree-Encoding in SirixDB
A node in SirixDB references other nodes by a firstChild/leftSibling/rightSibling/parentNodeKey/nodeKey encoding:
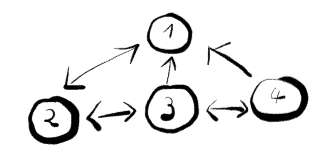
The numbers in the figure are auto-generated unique, stable node IDs generated with a simple sequential number generator.
Every node may have a first child, a left sibling, a right sibling, and a parent node. Furthermore, SirixDB is able to store the number of children, the number of descendants and hashes of each node.
In the following sections, we’ll introduce the core low-level JSON API of SirixDB.
5. Create a Database With a Single Resource
First, we want to show how to create a database with a single resource. The resource is going to be imported from a JSON file and stored persistently in the internal, binary format of SirixDB:
var pathToJsonFile = Paths.get("jsonFile");
var databaseFile = Paths.get("database");
Databases.createJsonDatabase(new DatabaseConfiguration(databaseFile));
try (var database = Databases.openJsonDatabase(databaseFile)) {
database.createResource(ResourceConfiguration.newBuilder("resource").build());
try (var manager = database.openResourceManager("resource");
var wtx = manager.beginNodeTrx()) {
wtx.insertSubtreeAsFirstChild(JsonShredder.createFileReader(pathToJsonFile));
wtx.commit();
}
}We first create a database. Then we open the database and create the first resource. Various options for creating a resource exist (see the official documentation).
We then open a single read-write transaction on the resource to import the JSON file. The transaction provides a cursor for navigation through moveToX methods. Furthermore, the transaction provides methods to insert, delete or modify nodes. Note that the XML API even provides methods for moving nodes in a resource and copying nodes from other XML resources.
To properly close the opened read-write transaction, the resource manager and the database we use Java’s try-with-resources statement.
We exemplified the creation of a database and resource on JSON data, but creating an XML database and resource is almost identical.
In the next section, we’ll open a resource in a database and show navigational axes and methods.
6. Open a Resource in a Database and Navigate
6.1. Preorder Navigation in a JSON Resource
To navigate through the tree structure, we’re able to reuse the read-write transaction after committing. In the following code we’ll, however, open the resource again and begin a read-only transaction on the most recent revision:
try (var database = Databases.openJsonDatabase(databaseFile);
var manager = database.openResourceManager("resource");
var rtx = manager.beginNodeReadOnlyTrx()) {
new DescendantAxis(rtx, IncludeSelf.YES).forEach((unused) -> {
switch (rtx.getKind()) {
case OBJECT:
case ARRAY:
LOG.info(rtx.getDescendantCount());
LOG.info(rtx.getChildCount());
LOG.info(rtx.getHash());
break;
case OBJECT_KEY:
LOG.info(rtx.getName());
break;
case STRING_VALUE:
case BOOLEAN_VALUE:
case NUMBER_VALUE:
case NULL_VALUE:
LOG.info(rtx.getValue());
break;
default:
}
});
}We use the descendant axis to iterate over all nodes in preorder (depth-first). Hashes of nodes are built bottom-up for all nodes per default depending on the resource configuration.
Array nodes and Object nodes have no name and no value. We can use the same axis to iterate through XML resources, only the node types differ.
SirixDB offers a bunch of axes as for instance all XPath-axes to navigate through XML and JSON resources. Furthermore, it provides a LevelOrderAxis, a PostOrderAxis, a NestedAxis to chain axis and several ConcurrentAxis variants to fetch nodes concurrently and in parallel.
In the next section, we’ll show how to use the VisitorDescendantAxis, which iterates in preorder, guided by return types of a node visitor.
6.2. Visitor Descendant Axis
As it’s very common to define behavior based on the different node-types SirixDB uses the visitor pattern.
We can specify a visitor as a builder argument for a special axis called VisitorDescendantAxis. For each type of node, there’s an equivalent visit-method. For instance, for object key nodes it is the method VisitResult visit(ImmutableObjectKeyNode node).
Each method returns a value of type VisitResult. The only implementation of the VisitResult interface is the following enum:
public enum VisitResultType implements VisitResult {
SKIPSIBLINGS,
SKIPSUBTREE,
CONTINUE,
TERMINATE
}The VisitorDescendantAxis iterates through the tree structure in preorder. It uses the VisitResultTypes to guide the traversal:
- SKIPSIBLINGS means that the traversal should continue without visiting the right siblings of the current node the cursor points to
- SKIPSUBTREE means to continue without visiting the descendants of this node
- We use CONTINUE if the traversal should continue in preorder
- We can also use TERMINATE to terminate the traversal immediately
The default implementation of each method in the Visitor interface returns VisitResultType.CONTINUE for each node type. Thus, we only have to implement the methods for the nodes, which we’re interested in. If we’ve implemented a class which implements the Visitor interface called MyVisitor we can use the VisitorDescendantAxis in the following way:
var axis = VisitorDescendantAxis.newBuilder(rtx)
.includeSelf()
.visitor(new MyVisitor())
.build();
while (axis.hasNext()) axis.next();The methods in MyVisitor are called for each node in the traversal. The parameter rtx is a read-only transaction. The traversal begins with the node the cursor currently points to.
6.3. Time Travel Axis
One of the most distinctive features of SirixDB is thorough versioning. Thus, SirixDB not only offers all kinds of axes to iterate through the tree structure within one revision. We’re also able to use one of the following axes to navigate in time:
- FirstAxis
- LastAxis
- PreviousAxis
- NextAxis
- AllTimeAxis
- FutureAxis
- PastAxis
The constructors take a resource manager as well as a transactional cursor as parameters. The cursor navigates to the same node in each revision.
If another revision in the axis – as well as the node in the respective revision – exists, then the axis returns a new transaction. The return values are read-only transactions opened on the respective revisions, whereas the cursor points to the same node in the different revisions.
We’ll show a simple example for the PastAxis:
var axis = new PastAxis(resourceManager, rtx);
if (axis.hasNext()) {
var trx = axis.next();
// Do something with the transactional cursor.
}6.4. Filtering
SirixDB provides several filters, which we’re able to use in conjunction with a FilterAxis. The following code, for instance, traverses all children of an object node and filters for object key nodes with the key “a” as in {“a”:1, “b”: “foo”}.
new FilterAxis<JsonNodeReadOnlyTrx>(new ChildAxis(rtx), new JsonNameFilter(rtx, "a"))The FilterAxis optionally takes more than one filter as its argument. The filter either is a JsonNameFilter, to filter for names in object keys or one of the node type filters: ObjectFilter, ObjectRecordFilter, ArrayFilter, StringValueFilter, NumberValueFilter, BooleanValueFilter and NullValueFilter.
The axis can be used as follows for JSON resources to filter by object key names with the name “foobar”:
var axis = new VisitorDescendantAxis.Builder(rtx).includeSelf().visitor(myVisitor).build();
var filter = new JsonNameFilter(rtx, "foobar");
for (var filterAxis = new FilterAxis<JsonNodeReadOnlyTrx>(axis, filter); filterAxis.hasNext();) {
filterAxis.next();
}Alternatively, we could simply stream over the axis (without using the FilterAxis at all) and then filter by a predicate.
rtx is of type NodeReadOnlyTrx in the following example:
var axis = new PostOrderAxis(rtx);
var axisStream = StreamSupport.stream(axis.spliterator(), false);
axisStream.filter((unusedNodeKey) -> new JsonNameFilter(rtx, "a"))
.forEach((unused) -> /* Do something with the transactional cursor */);7. Modify a Resource in a Database
Obviously, we want to be able to modify a resource. SirixDB stores a new compact snapshot during each commit.
After opening a resource we have to start the single read-write transaction as we’ve seen before.
7.1. Simple Update Operations
Once we navigated to the node we want to modify, we’re able to update for instance the name or the value, depending on the node type:
if (wtx.isObjectKey()) wtx.setObjectKeyName("foo");
if (wtx.isStringValue()) wtx.setStringValue("foo");We can insert new object records via insertObjectRecordAsFirstChild and insertObjectRecordAsRightSibling. Similar methods exist for all node types. Object records are composed of two nodes: An object key node and an object value node.
SirixDB checks for consistency and as such it throws an unchecked SirixUsageException if a method call is not permitted on a specific node type.
Object records, that is key/value pairs, for instance, can only be inserted as a first child if the cursor is located on an object node. We insert both an object key node as well as one of the other node types as the value with the insertObjectRecordAsX methods.
We can also chain the update methods – for this example, wtx is located on an object node:
wtx.insertObjectRecordAsFirstChild("foo", new StringValue("bar"))
.moveToParent().trx()
.insertObjectRecordAsRightSibling("baz", new NullValue());First, we insert an object key node with the name “foo” as the first child of an object node. Then, a StringValueNode is created as the first child of the newly created object record node.
The cursor is moved to the value node after the method call. Thus we first have to move the cursor to the object key node, the parent again. Then, we’re able to insert the next object key node and its child, a NullValueNode as a right sibling.
7.2. Bulk Insertions
More sophisticated bulk insertion methods exist, too, as we’ve already seen when we imported JSON data. SirixDB provides a method to insert JSON data as a first child (insertSubtreeAsFirstChild) and as a right sibling (insertSubtreeAsRightSibling).
To insert a new subtree based on a String we can use:
var json = "{\"foo\": \"bar\",\"baz\": [0, \"bla\", true, null]}";
wtx.insertSubtreeAsFirstChild(JsonShredder.createStringReader(json));The JSON API currently doesn’t offer the possibility to copy subtrees. However, the XML API does. We’re able to copy a subtree from another XML resource in SirixDB:
wtx.copySubtreeAsRightSibling(rtx);Here, the node the read-only transaction (rtx) currently points to is copied with its subtree as a new right sibling of the node that the read-write transaction (wtx) points to.
SirixDB always applies changes in-memory and then flushes them to a disk or the flash drive during a transaction commit. The only exception is if the in-memory cache has to evict some entries into a temporary file due to memory constraints.
We can either commit() or rollback() the transaction. Note that we can reuse the transaction after one of the two method calls.
SirixDB also applies some optimizations under the hood when invoking bulk insertions.
In the next section, we’ll see other possibilities on how to start a read-write transaction.
7.3. Start a Read-Write Transaction
As we’ve seen we can begin a read-write transaction and create a new snapshot by calling the commit method. However, we can also start an auto-committing transactional cursor:
resourceManager.beginNodeTrx(TimeUnit.SECONDS, 30);
resourceManager.beginNodeTrx(1000);
resourceManager.beginNodeTrx(1000, TimeUnit.SECONDS, 30);Either we auto-commit every 30 seconds, after every 1000th modification or every 30 seconds and every 1000th modification.
We’re also able to start a read-write transaction and then revert to a former revision, which we can commit as a new revision:
resourceManager.beginNodeTrx().revertTo(2).commit();All revisions in between are still available. Once we have committed more than one revision we can open a specific revision either by specifying the exact revision number or by a timestamp:
var rtxOpenedByRevisionNumber = resourceManager.beginNodeReadOnlyTrx(2);
var dateTime = LocalDateTime.of(2019, Month.JUNE, 15, 13, 39);
var instant = dateTime.atZone(ZoneId.of("Europe/Berlin")).toInstant();
var rtxOpenedByTimestamp = resourceManager.beginNodeReadOnlyTrx(instant);8. Compare Revisions
To compute the differences between any two revisions of a resource, once stored in SirixDB, we can invoke a diff-algorithm:
DiffFactory.invokeJsonDiff(
new DiffFactory.Builder(
resourceManager,
2,
1,
DiffOptimized.HASHED,
ImmutableSet.of(observer)));The first argument to the builder is the resource manager, which we already used several times. The next two parameters are the revisions to compare. The fourth parameter is an enum, which we use to determine if SirixDB should take hashes into account to speed up the diff-computation or not.
If a node changes due to update operations in SirixDB, all ancestor nodes adapt their hash values, too. If the hashes and the node keys in the two revisions are identical, SirixDB skips the subtree during the traversal of the two revisions, because there are no changes in the subtree when we specify DiffOptimized.HASHED.
An immutable set of observers is the last argument. An observer has to implement the following interface:
public interface DiffObserver {
void diffListener(DiffType diffType, long newNodeKey, long oldNodeKey, DiffDepth depth);
void diffDone();
}The diffListener method as the first parameter specifies the type of diff encountered between two nodes in each revision. The next two arguments are the stable unique node identifiers of the compared nodes in the two revisions. The last argument depth specifies the depth of the two nodes, which SirixDB just compared.
9. Serialize to JSON
At some point in time we want to serialize a JSON resource in SirixDBs binary encoding back to JSON:
var writer = new StringWriter();
var serializer = new JsonSerializer.Builder(resourceManager, writer).build();
serializer.call();To serialize revision 1 and 2:
var serializer = new
JsonSerializer.Builder(resourceManager, writer, 1, 2).build();
serializer.call();And all stored revisions:
var serializer = new
JsonSerializer.Builder(resourceManager, writer, -1).build();
serializer.call();
10. Conclusion
We’ve seen how to use the low-level transactional cursor API to manage JSON databases and resources in SirixDB. Higher level-APIs hide some of the complexity.


















