Better Retries with Exponential Backoff and Jitter
Last updated: August 6, 2025


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In this tutorial, we’ll explore how we can improve client retries with two different strategies: exponential backoff and jitter.
2. Retry
In a distributed system, network communication among the numerous components can fail anytime. Client applications deal with these failures by implementing retries.
Let’s assume that we have a client application that invokes a remote service – the PingPongService.
interface PingPongService {
String call(String ping) throws PingPongServiceException;
}The client application must retry if the PingPongService returns a PingPongServiceException. In the following sections, we’ll look at ways to implement client retries.
3. Resilience4j Retry
For our example, we’ll be using the Resilience4j library, particularly its retry module. We’ll need to add the resilience4j-retry module to our pom.xml:
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-retry</artifactId>
</dependency>For a refresher on using retries, don’t forget to check out our Guide to Resilience4j.
4. Exponential Backoff
Client applications must implement retries responsibly. When clients retry failed calls without waiting, they may overwhelm the system, and contribute to further degradation of the service that is already under distress.
Exponential backoff is a common strategy for handling retries of failed network calls. In simple terms, the clients wait progressively longer intervals between consecutive retries:
wait_interval = base * multiplier^n
where,
- base is the initial interval, ie, wait for the first retry
- n is the number of failures that have occurred
- multiplier is an arbitrary multiplier that can be replaced with any suitable value
With this approach, we provide a breathing space to the system to recover from intermittent failures, or even more severe problems.
We can use the exponential backoff algorithm in Resilience4j retry by configuring its IntervalFunction that accepts an initialInterval and a multiplier.
The IntervalFunction is used by the retry mechanism as a sleep function:
IntervalFunction intervalFn =
IntervalFunction.ofExponentialBackoff(INITIAL_INTERVAL, MULTIPLIER);
RetryConfig retryConfig = RetryConfig.custom()
.maxAttempts(MAX_RETRIES)
.intervalFunction(intervalFn)
.build();
Retry retry = Retry.of("pingpong", retryConfig);
Function<String, String> pingPongFn = Retry
.decorateFunction(retry, ping -> service.call(ping));
pingPongFn.apply("Hello");
Let’s simulate a real-world scenario, and assume that we have several clients invoking the PingPongService concurrently:
ExecutorService executors = newFixedThreadPool(NUM_CONCURRENT_CLIENTS);
List<Callable> tasks = nCopies(NUM_CONCURRENT_CLIENTS, () -> pingPongFn.apply("Hello"));
executors.invokeAll(tasks);
Let’s look at the remote invocation logs for NUM_CONCURRENT_CLIENTS equal to 4:
[thread-1] At 00:37:42.756
[thread-2] At 00:37:42.756
[thread-3] At 00:37:42.756
[thread-4] At 00:37:42.756
[thread-2] At 00:37:43.802
[thread-4] At 00:37:43.802
[thread-1] At 00:37:43.802
[thread-3] At 00:37:43.802
[thread-2] At 00:37:45.803
[thread-1] At 00:37:45.803
[thread-4] At 00:37:45.803
[thread-3] At 00:37:45.803
[thread-2] At 00:37:49.808
[thread-3] At 00:37:49.808
[thread-4] At 00:37:49.808
[thread-1] At 00:37:49.808
We can see a clear pattern here – the clients wait for exponentially growing intervals, but all of them call the remote service at precisely the same time on each retry (collisions).
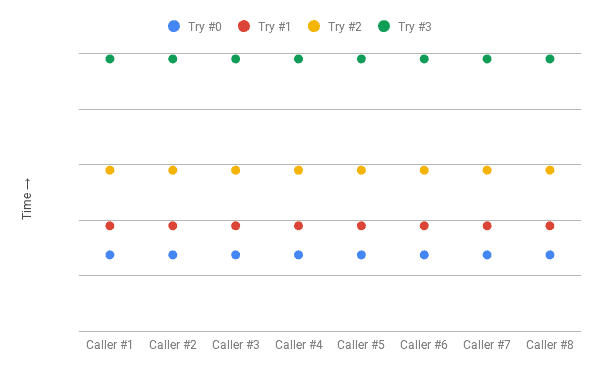
We have addressed only a part of the problem – we do not hammer the remote service with retries anymore, but instead of spreading the workload over time, we have interspersed periods of work with more idle time. This behavior is akin to the Thundering Herd Problem.
5. Introducing Jitter
In our previous approach, the client waits are progressively longer but still synchronized. Adding jitter provides a way to break the synchronization across the clients thereby avoiding collisions. In this approach, we add randomness to the wait intervals.
wait_interval = (base * 2^n) +/- (random_interval)
where, random_interval is added (or subtracted) to break the synchronization across clients.
We’ll not go into the mechanics of computing the random interval, but randomization must space out the spikes to a much smoother distribution of client calls.
We can use the exponential backoff with jitter in Resilience4j retry by configuring an exponential random backoff IntervalFunction that also accepts a randomizationFactor:
IntervalFunction intervalFn =
IntervalFunction.ofExponentialRandomBackoff(INITIAL_INTERVAL, MULTIPLIER, RANDOMIZATION_FACTOR);
Let’s return to our real-world scenario, and look at the remote invocation logs with jitter:
[thread-2] At 39:21.297
[thread-4] At 39:21.297
[thread-3] At 39:21.297
[thread-1] At 39:21.297
[thread-2] At 39:21.918
[thread-3] At 39:21.868
[thread-4] At 39:22.011
[thread-1] At 39:22.184
[thread-1] At 39:23.086
[thread-5] At 39:23.939
[thread-3] At 39:24.152
[thread-4] At 39:24.977
[thread-3] At 39:26.861
[thread-1] At 39:28.617
[thread-4] At 39:28.942
[thread-2] At 39:31.039Now we have a much better spread. We have eliminated both collisions and idle time, and end up with an almost constant rate of client calls, barring the initial surge.
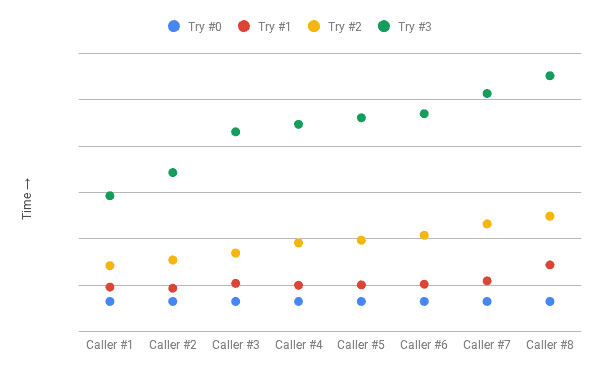
Note: We’ve overstated the interval for illustration, and in real-world scenarios, we would have smaller gaps.
6. Conclusion
In this tutorial, we’ve explored how we can improve how client applications retry failed calls by augmenting exponential backoff with jitter.


















