

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
In this tutorial, we’ll talk about Redis and, more importantly, its two different deployment strategies, Redis Sentinel and Redis Cluster. Then, we’ll discuss the differences between those strategies and their nuances.
At the end of it, we hope to understand enough about Redis to judge which deployment strategy better fulfils our needs.
2. Introduction to Redis
Redis is an open-source in-memory data structure store that can be used as a key-value database, cache, and for many other use cases. It aims to provide high-speed access to data.
Our goal is to analyze and compare the two different strategies, Redis Sentinel and Redis Cluster.
Redis Sentinel is a separate process that Redis provides. Its goal is to monitor the Redis instances, offer notification capabilities, master discovery, automatic failover in case of failure, and master election via majority voting. In other words, Sentinel is a distributed system that provides extra capabilities to Redis, such as high availability and failover. Redis Sentinel combines forces with the standard Redis deployment.
Redis Cluster is a deployment strategy that scales even further. Similar to Sentinel, it provides failover, configuration management, etc. The difference is the sharding capabilities, which allow us to scale out capacity almost linearly up to 1000 nodes.
3. Basic Concepts
To help us understand the nuances of both strategies, let’s first try to internalize some of the basic concepts and building blocks.
Some concepts may not be strictly related to Redis Cluster or Sentinel. However, others may apply to both, but knowing them will help us understand Redis.
3.1. Databases
Redis has support for multiple logical databases. Although still persisted in the same file, they allow the user to have the same key with different values in each database. They’re like different database schemas.
By default, Redis provides 16 logical databases, but the user can change this number. Such databases are identified by their index, starting from zero.
Another essential thing to reinforce is that Redis is a single-threaded data store. Therefore, all database operations go to the same pipeline of execution.
3.2. Hash Slots
Redis Cluster works a bit differently from the standard one. For example, to automatically shard the data and distribute it across the various nodes of the cluster, Redis Cluster uses the so-called hash slots.
Redis Cluster doesn’t use consistent hashing to do the distribution job. Instead, it uses the hash slots.
Each cluster has 16384 hash slots that can be distributed across all the nodes, and during all operations, the Redis client uses the key to calculate the hash by taking the CRC16 of the key modulo 16384. Then, it uses it to route the command to the correct node.
Each node has a subset of hash slots assigned to it, and it’s possible to move slots between nodes using resharding or rebalance operations. Also, given the particularities of this approach, the Redis Cluster doesn’t allow multiple logical databases per node. Therefore, only the database zero is available in each node.
Last, due to the distribution of the keys in hash slots, Redis Cluster has a caveat when it comes to multiple key operations. Those operations are still available, although all the keys involved have to belong to the same hash slot. Otherwise, Redis rejects the request.
3.3. Hash Tags
This mechanism helps users guarantee a group of keys go to the same hash slot. To define a hash tag, the user has to add a substring between brackets in a key. For instance, the keys app1{user:123}.mykey1 and app1{user:123}.mykey2 would go to the same hash lot.
By doing this, Redis only uses the substring to generate the hash of the key and, consequently, for routing all keys to the same hash slot.
3.4. Asynchronous Replication
Both Redis Cluster and the standard one use asynchronous replication. That means Redis doesn’t wait for replicas to acknowledge writes.
Moreover, there will always be a tiny window of time where a failure may cause an acknowledged write to be lost. However, there are ways to mitigate this risk by limiting this window of time as much as possible. But once again, the risk is always there, so Redis doesn’t guarantee strong consistency.
3.5. Failover
Redis offers different mechanisms to deal with failures and guarantee some level of fault tolerance. Both Redis Cluster and the standard one using Sentinel have such tools. Such systems come with a failure detector based on health checks and timeouts.
In the case of Redis Cluster, it uses heartbeat and gossip protocol. For the purpose of this article, we’ll not go deeper into those. But to sum up, each one talks to the other nodes, exchanges packets with metadata, and calculates some timeouts in case a particular node doesn’t respond.
Regarding Sentinel, each Sentinel instance monitors a Redis instance. The Sentinel instances also communicate between themselves and, based on the configuration, may execute failovers due to problems with communication and timeouts.
3.6. Master Election
Again, both implementations have strategies for voting, and the process has different phases. But the main goal’s to decide if the failover should happen and which to promote.
Sentinel works with the concept of quorum. The quorum is the minimum number of Sentinel instances that need to find the consensus about whether a master node is reachable or not.
Once this happens, the master is marked as failing, and eventually, a failover process will start if possible. After that, at least a majority of Sentinels must authorize the failover and elect the Sentinel instance responsible for the failover. Then, this instance selects the best read replica to promote and executes the failover. Finally, the instance starts broadcasting the new setup to the other Sentinel instances.
The process changes a bit when it comes to Redis Cluster. This time, the replica nodes are in charge. As we mentioned before, in this case, all nodes communicate between them, so once one or more replicas detect the failure, they can start the election. The next step is to request the vote of the masters. Once the voting happens, a replica receives the failover rights.
Given the nature of those vote mechanisms, Redis recommends always using an odd number of nodes in the cluster, which applies to both implementations.
3.7. Network Partition
Redis can survive many different failures, and its design is robust enough to provide continuous operation even when nodes go down. However, one of the critical problem scenarios we can face is the so-called network partition. Due to its topology, Redis faces challenging situations when dealing with such problems.
The so-called split brain’s one of the most straightforward problems in this category. Let’s use the following example:
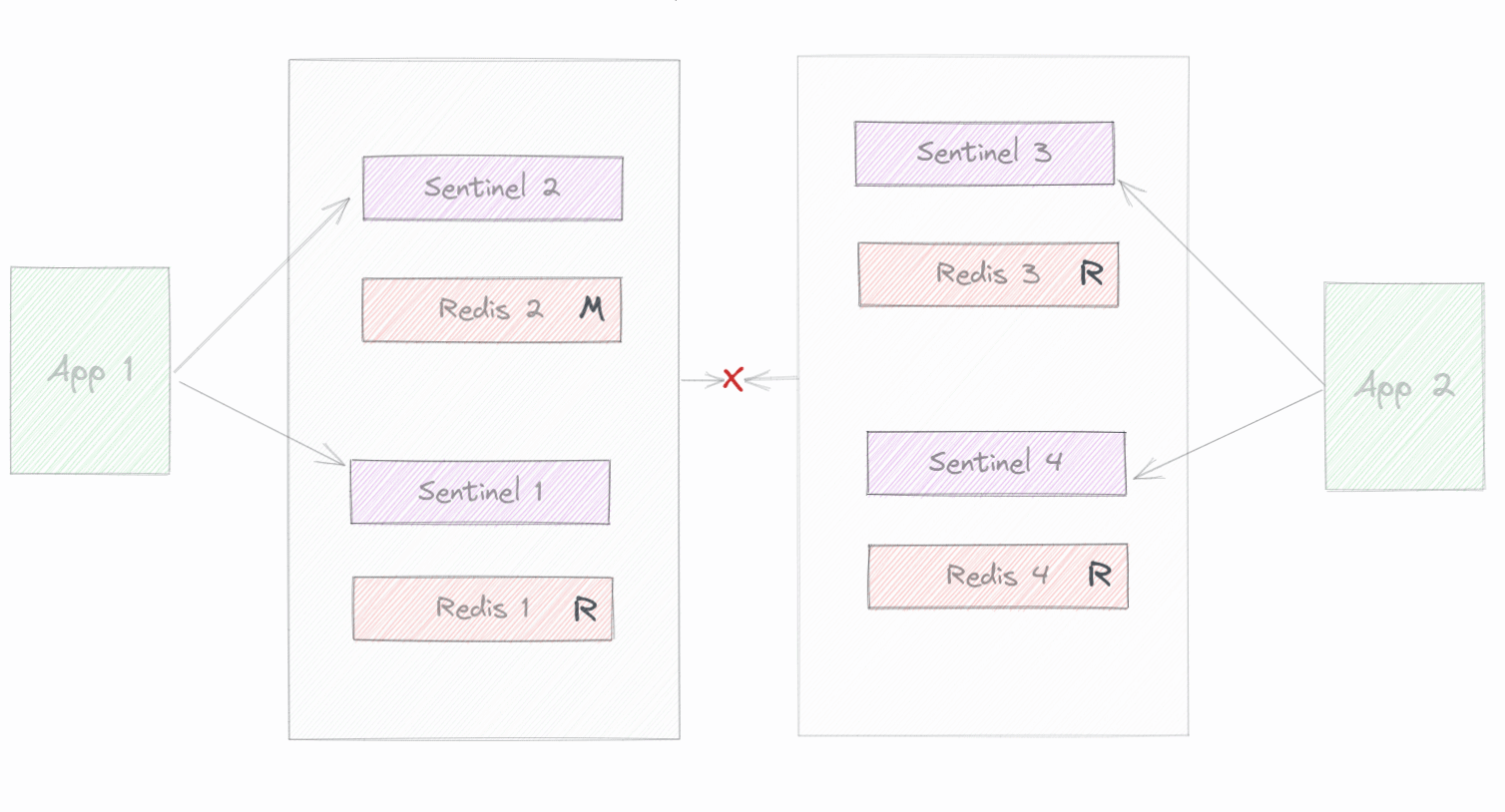
Here we can observe that we have a network partition, and from one side, a client is communicating with our cluster that now only can reach two instances, 1 and 2.
On the other side, another client communicates with the other partition where only 3 and 4 are reachable in the partition. Imagining our quorum is 2, at some point, the failover will happen on the right side, and we’ll reach the outcome:
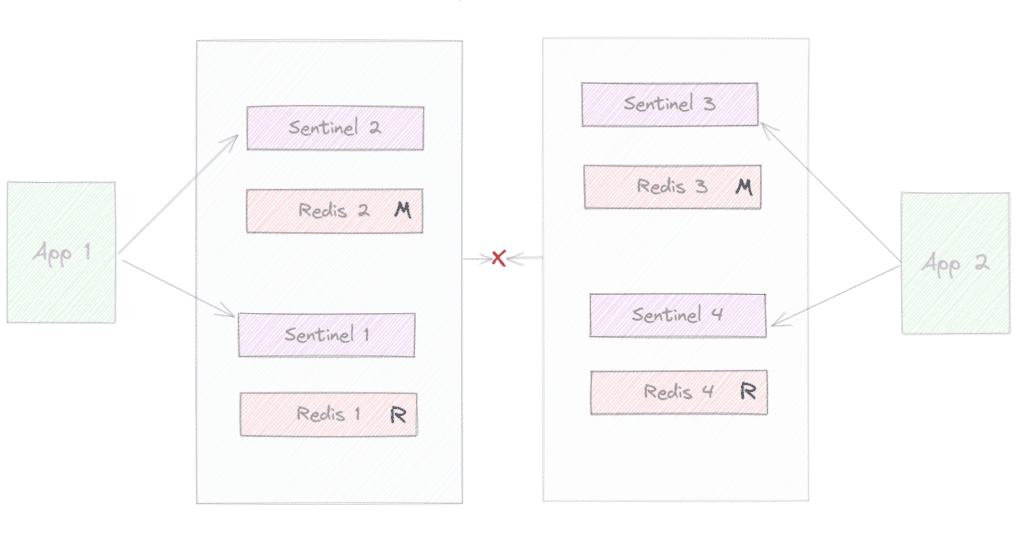
Now, we’ve two clusters (Redis 3 has been promoted to master). At some point, when the network partition goes away, the cluster may have a problem in case the same key was written on both sides with different values during the separation.
We can apply the same principles to a Redis Cluster, and the outcome would be similar. This illustrates why odd numbers are recommended and configurations such as min-replicas-to-write are used. The idea is always to have majority and minority partitions where only the majority would be able to perform the failover.
As we may imagine, there are many other possible scenarios during network partitions. For that reason, it’s essential to understand and have it in mind when designing our cluster, no matter which option we choose.
4. Redis Sentinel vs Clustering
The table below compares some of their main features:
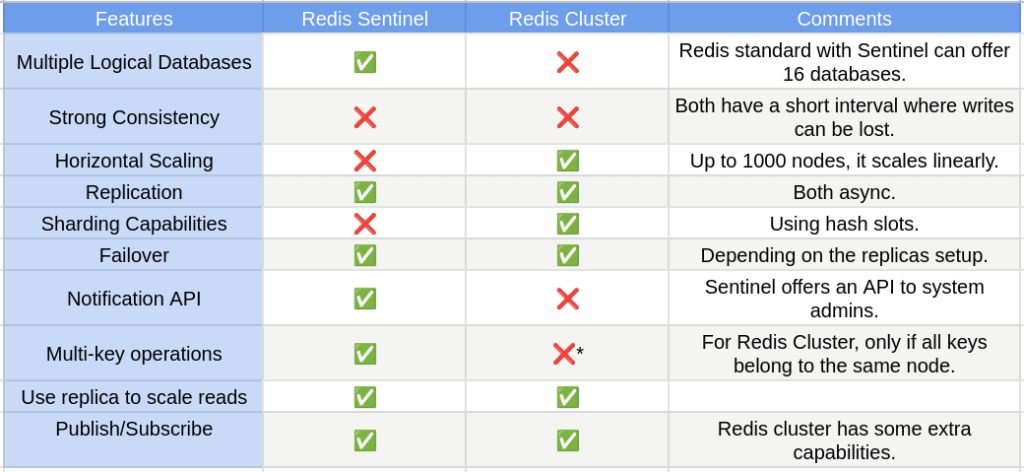
We can connect the dots by using all the details and nuances of Redis Cluster and the standard implementation combined with Redis Sentinel.
We can conclude that Sentinel provides monitoring, fault tolerance, and notifications. It’s also a configuration provider. Moreover, it can provide authentication capabilities and client service discovery. It can provide 16 logical databases, async replication and high availability for your cluster.
Nonetheless, the single-threaded nature of Redis and the barriers of vertical scaling are limiting factors to Sentinel’s scaling capabilities. However, for small and medium projects, it may be ideal.
It’s also true that deployment with Sentinel requires fewer nodes. Therefore, it’s more cost-effective.
A point worth mentioning is that we can also scale read-only operations further by using read replicas.
Redis Cluster is a fully distributed implementation with automated sharding capabilities (horizontal scaling capabilities), designed for high performance and linear scaling up to 1000 nodes. In addition, it provides a reasonable degree of writing safety and means to survive disasters as long as all the data of masters are reachable from the majority side (by the master or replicas cable to do the failover).
Another point is that during a network partition, the minority part of the cluster will stop accepting requests. On the other hand, a Sentinel deployment may continue working partially, depending on the configuration. As mentioned previously, the availability of the cluster and the fault tolerance depends on the cluster configuration and composition.
The Cluster version also offers the ability to reconfigure the mapping between masters and replicas to rebalance in case of multiple independent failures of a single node occur. However, once again, more nodes are necessary for a more robust cluster and, therefore, more cost. Besides, managing more nodes and balancing shards is extra complexity that can’t be overlooked.
To sum up, Redis Cluster shines when it comes to large deployment with big data sets that require high throughput and scaling capabilities.
5. Conclusion
In this article, we discussed Redis and its different implementations, Redis Cluster and Redis standard using Sentinel.
We also understood all the basic building blocks of the solution and how to use them to extract the most out of it. We hope to have the tools to decide which option to use based on the use case.

















