

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Service Level Agreements (SLAs) play a foundational role in cloud computing by defining measurable expectations for service availability, performance, and support responsiveness. These agreements set clear benchmarks, helping customers and providers to align on what constitutes acceptable service quality and accountability. Understanding how to calculate SLA metrics becomes especially important when assessing or negotiating cloud services, as it offers a reliable way to quantify service performance and guide sound decision-making.
In this tutorial, we’ll explore the key concepts behind SLAs in cloud environments and walk through how to calculate SLA availability step by step. This also includes availability metrics, SLA tiers, downtime calculations, and the role of response and resolution times. By the end, we’ll know how to interpret SLAs and assess their implications in day-to-day operations.
SLAs in cloud computing formalize commitments from service providers such as AWS, Microsoft, and Google regarding service delivery. A typical SLA defines the percentage of time a service is accessible and performing at an agreed standard within a measurement period. This percentage is most often referred to as availability or uptime.
Availability serves as a key indicator of service reliability. Additionally, it allows customers to determine how consistently their applications remain functional and accessible within a given timeframe. In most SLAs, availability is the primary focus.
Beyond availability, SLAs can also outline other performance metrics such as response times for support, latency, and throughput. These help paint a broader picture of service quality but are typically secondary to availability in terms of visibility and impact.
SLAs play a vital role in setting expectations, establishing accountability, and providing measurable criteria for evaluating service performance. For businesses dependent on the cloud, SLAs are a crucial part of managing operational risk and meeting compliance needs.
To understand how SLAs are measured, let’s define a few foundational terms. These help standardize reporting and remove ambiguity when tracking performance:
Uptime: The total time a service is running without issues. If users can access it and everything works as expected, that counts as uptime.
Downtime: Any period when the service is either unavailable or not performing as expected. This could result from outages, system failures, or events defined as service interruptions in the SLA.
Measurement Period: The time window over which uptime and downtime are recorded. This could be a calendar month, a quarter, or a year window.
Availability Percentage: A metric expressing service reliability during the measurement period, usually calculated as the percentage of time the service remains up.
Accurate SLA measurement depends on consistent definitions. If different teams interpret these terms differently, reported availability figures can become misleading or incorrect.
In this section, we’ll focus on calculating SLA availability, from defining the measurement period to tracking downtime, applying the formula, and understanding related metrics like response and resolution times.
Calculating SLA availability starts with specifying the measurement period. The measurement period standardizes the calculation over a fixed timeframe, commonly a calendar month or year. Having clear start and end points for this interval enables precise tracking of uptime and downtime.
Downtime consists of any period during the measurement interval when the cloud service fails to meet its availability or performance threshold. Scheduled maintenance, if communicated in advance, is typically excluded.
Accurate logging of downtime requires timestamps marking the beginning and end of each outage. Although some SLAs distinguish between full outages and degraded performance, such distinctions only affect calculations if the SLA explicitly applies different weights or penalties, which is often not the case. Therefore, we must track all service-impacting incidents consistently.
The availability percentage quantifies the portion of time the service remains operational. We can calculate the availability percentage as follows:

For instance, if a cloud service has 43,200 minutes in a 30-day month and experiences 60 minutes of downtime, we can calculate the availability percentage:
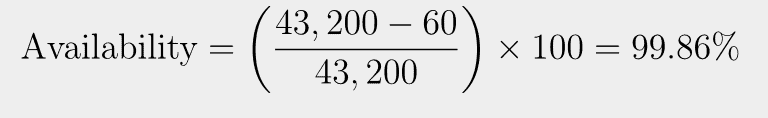
We can present availability in predefined tiers such as 99.9%, 99.99%, and 99.999%. These tiers indicate the maximum allowable downtime within a measurement period. This helps organizations assess the level of reliability that aligns with their workload requirements.
The table below provides a reference for how much downtime is permitted under each tier:
| SLA Tier | Max Downtime per Month | Max Downtime per Year |
| 99.9% | ~43.2 minutes | ~8.76 hours |
| 99.99% | ~4.32 minutes | ~52.6 minutes |
| 99.999% | ~26 seconds | ~5.26 minutes |
These figures offer a practical view of what each availability level means in real terms. Choosing the right tier depends on the impact of downtime on business operations and the level of tolerance for interruptions.
After defining the SLA percentage, we must determine the amount of downtime allowed during the measurement period. This sets a clear boundary to know the amount of downtime before breaching the SLA.
To calculate the allowed downtime, let’s use this simple formula:
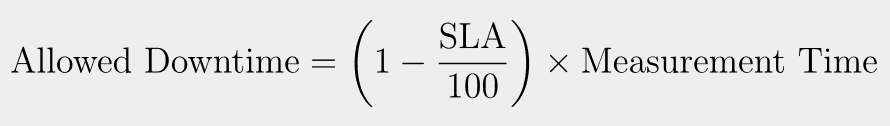
Assuming a cloud service provider offers an SLA of 99.99% for a 30-day month, and the measurement period is calculated in minutes, and knowing 30 days equal 43,200 minutes, the calculation becomes:
Therefore, to provide 99.99% availability for the month, we’re only allowed 4.32 minutes of downtime.
SLAs often extend beyond availability to define how providers handle incidents, particularly response and resolution times. These two metrics give deeper insight into the provider’s operational maturity and support efficiency.
| Severity | Description | Max Response Time | Max Resolution Time |
| Critical (P1) | Complete outage or major service failure impacting all users | 15 minutes | 1 hour |
| High (P2) | Significant functionality broken, affecting many users | 1 hour | 4 hours |
| Medium (P3) |
Partial service disruption or degraded performance affecting specific features or a small set of users |
4 hours | 1 business day |
| Low (P4) | Minor issues with minimal impact | 8 hours | 3 business days |
This approach allows the provider to prioritize high-impact issues while setting realistic timelines for lower-priority items for the customer.
Even if availability targets are met, delays in response or resolution cause business disruption. These metrics provide a greater picture of operational reliability.
Here, let’s take a look at the common challenges in SLA tracking and explore practical ways to improve accuracy and reliability.
Calculating SLAs precisely involves several challenges. Defining what qualifies as downtime can be complex, especially when service performance is degraded rather than completely failing. Maintaining accurate monitoring data is critical to avoid disputes and misinterpretations. The frequency of data sampling impacts calculation granularity and precision. Furthermore, integrating multiple metrics such as latency, throughput, and support responsiveness adds complexity.
To overcome these outlined challenges, these best practices help improve the accuracy and consistency of SLA measurement:
Finally, these practices enable transparent and effective SLA management, promoting trust between providers and customers.
In this article, we explored how SLAs work in cloud services, with a focus on calculating availability as a key performance indicator. Effective SLA calculation depends on clearly defined measurement windows, accurate tracking of downtime, and the consistent use of formulas to determine uptime. Understanding the range of SLA tiers also helps organizations choose service levels that align with their business priorities.
While availability is key, adding metrics such as response and resolution times provides a comprehensive picture of service performance. Challenges such as inconsistent definitions of downtime or gaps in monitoring can complicate SLA enforcement. However, adopting good practices, like automated tracking, clear communication, and regularly reviewing SLAs, can improve their reliability and relevance.
SLAs create a shared, measurable framework that helps cloud providers and customers stay accountable and deliver dependable services in dynamic cloud environments.