

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In the world of document processing, the ability to seamlessly convert PDF files to ODT (Open Document Text) format is a valuable skill. Linux users often seek reliable tools and methods to accomplish this task efficiently.
PDF files often present a challenge when we seek to extract or modify content, making the need for conversion to ODT essential. Fortunately, Linux has many tools such as pdf2odt that we can use to accomplish this task, as well as some OCR tools we can use to extract text from an image-based PDF file and save it as an ODT file.
In this tutorial, we’ll cover some of the command-line tools for converting PDF files to ODT format on Linux. Moreover, we’ll also touch on some of the online tools available to us.
pdf2odt is an open-source command-line tool that converts PDF files to ODT format. The PDF pages are converted as images, and the tool makes use of pdftoppm from the poppler-utils package to perform the conversion.
Let’s explore how to convert PDF files to ODT format using pdf2odt.
pdf2odt is available for installation on most Linux distros and we can install it using Python’s pip package manager:
$ pip install pdf2odtWe can also install Tesseract OCR and use it with pdf2odt to extract text from image-based PDF files. Tesseract OCR is an open-source optical character recognition engine available for various operating systems.
To install it on Debian, we can use the APT package manager:
$ sudo apt-get install tesseract-ocrAlternatively, on Arch Linux, we can use Pacman:
$ sudo pacman -S tesseractFinally, on Fedora Linux, we can employ DNF:
$ sudo dnf install tesseractNow that our installation is complete, let’s look at how to use pdf2odt to convert PDF files. We’ll also use it with Tesseract OCR to extract editable text from PDF files.
Assuming we had a PDF file named test.pdf in our working directory, let’s convert it to ODT format:
$ pdf2odt --pdf test.pdf test.odtWe’re using the –pdf option since the input file is a PDF file. This command creates an output file named test.odt and works best with text-based PDF files.
Alternatively, we can use pdf2odt with the Tesseract OCR to extract text from image-based PDF files:
$ pdf2odt --pdf test.pdf --tesseract test.odtWe’re passing the –tesseract option to extract text from the PDF file. This command preserves the original image-based pages and creates a duplicate, editable version of each.
The output ODT file may not be identical to the input PDF file, especially with complex PDF layouts.
pdftotext is an open-source command-line utility that converts PDF files to plain text. It has several options that we can use to handle PDF files with complex layouts.
Let’s look at how to install and use pdftotext to convert PDF files to ODT format.
To install pdftotext, we need to ensure we have Python installed on our system.
Let’s start with installing the dependencies. On Debian, we can use the APT package manager:
$ sudo apt install build-essential libpoppler-cpp-dev pkg-config python3-devAlternatively, on Fedora or Red Hat, we can employ YUM:
$ sudo yum install gcc-c++ pkgconfig poppler-cpp-devel python3-develFinally, on Arch Linux, we can use Pacman:
$ sudo pacman -S gcc-c++ pkgconfig poppler-cpp-devel python3-develOnce we have the dependencies installed, we can proceed with installing pdftotext from pip:
$ pip install pdftotextWith our installation complete, let’s find out how to use pdftotext to convert PDF files with simple or complex layouts.
Let’s use pdftotext to convert our test.pdf file to ODT format:
$ pdftotext test.pdf test.odtThe command above outputs a file named test.odt that we can open with any ODT file reader.
We can also use the -layout option to maintain the original physical layout of the input PDF file:
$ pdftotext -layout test.pdf test.odtAlternatively, we can use the -f option or -l to specify the first or last page, respectively, to convert:
$ pdftotext -f 1 -l 3 test.pdf test.odtThe command above will only convert the first, second, and third pages of the input PDF file.
We should note that pdftotext does not work with image-based PDF files.
We can also use popular online services such as online2pdf.com to convert PDF files to ODT format. These offer a quick and simple way of converting PDF files to different formats. Furthermore, most have an OCR tool integrated, which means they can handle both text-based and image-based PDF files.
Online services take away the extra work of installing the conversion tools on our system. However, they may not be the best option when converting sensitive documents.
Let’s find out how to convert PDF files to ODT format using online2pdf.com. We can start by navigating to https://online2pdf.com/convert-pdf-to-odt on a browser of choice:
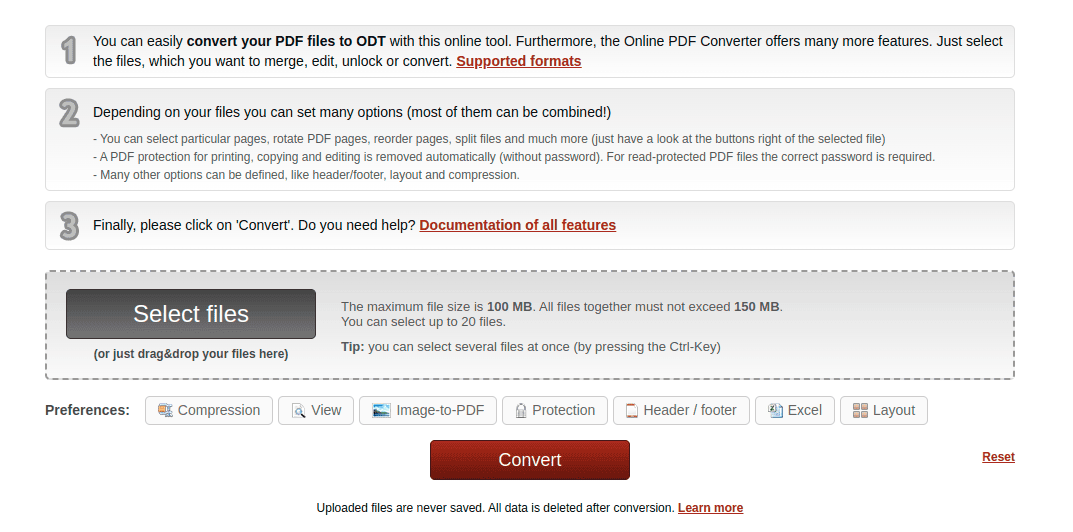
We can start the conversion process by clicking on the “Select files” button, or by dragging and dropping files. Once we’ve uploaded a file, we have the option to use an OCR tool or not depending on whether the PDF file is image-based or text-based:
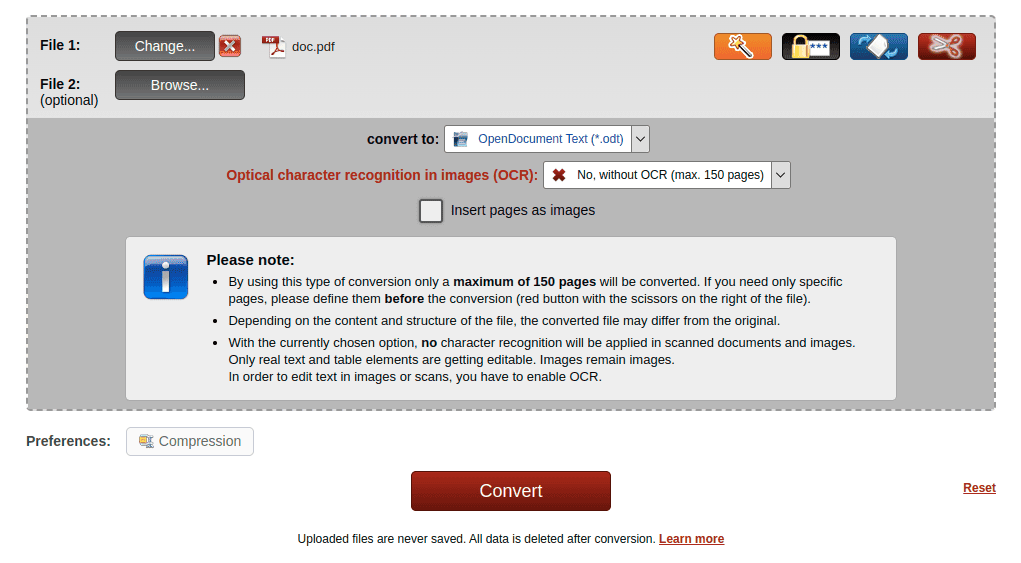
When we click on the “Convert” button, the uploaded files will be converted, and the converted files will be automatically downloaded. This tool also supports exporting the input PDF file in other formats such as docx, xlsx, epub, and more.
The diversity of tools and methods available on Linux for converting PDF to ODT caters to various user preferences and requirements. From command-line utilities like pdftotext and pdf2odt, as well as the convenience of online services like online2pdf.com, Linux users have different options to tackle the task of document conversion efficiently.
Choosing the right tool often depends on the user’s proficiency with command-line interfaces, preference for graphical user interfaces, or the need for occasional or frequent conversions. Nevertheless, the rich selection of tools available in the Linux ecosystem ensures that converting PDF to ODT is a manageable and accessible task. We also need to be aware that the output ODT file may not have an identical layout to the input PDF file, especially if it has a complex layout.