

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Get a Browser-Like Web Page HTML From the Command Line
Last updated: January 15, 2026
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’ll talk about downloading web pages from the command line interface (CLI).
We can certainly inspect the HTML elements of a web page from a browser. In most browsers, pressing Ctrl+S will save the web page as an HTML. Moreover, some browsers allow for the individual inspection of HTML elements and their manipulation.
We’ll try to get an HTML file that looks (and behaves) similarly to the web page that we see in the browser but from the command line. This can be useful for automation purposes, for example.
2. Basic Downloading With wget
wget is the first tool we think about when trying to download network data from a command line (together with curl). Getting a web page (such as the Linux Wikipedia entry) is rather simple:
$ wget https://en.wikipedia.org/wiki/LinuxHowever, the resulting downloaded file will not look like what we see when accessing the web page directly from the browser:

To download a web page with the same layout as in the browser with wget, we need to specify some extra flags:
$ wget -p \
--user-agent="Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)\
Ubuntu Chromium/83.0.4103.61 Chrome/83.0.4103.61 Safari/537.36"\
https://en.wikipedia.org/wiki/LinuxWe’ve added two useful options to wget. The -p flag (equivalent to –page-requisites) is used to get images and other files needed to display an HTML page.
The –user-agent flag specifies the user-agent header, which gives information about the browser, operating system, and other device settings. Providing a user agent is key: Even if it’s a simple text string sent when requesting something to the server, the answer returned by the server may depend on it. The one given here is a generic user-agent. However, some sites help us determine the user agent of our browser.
With these two options, we already have an HTML file version more similar to the web page available online:
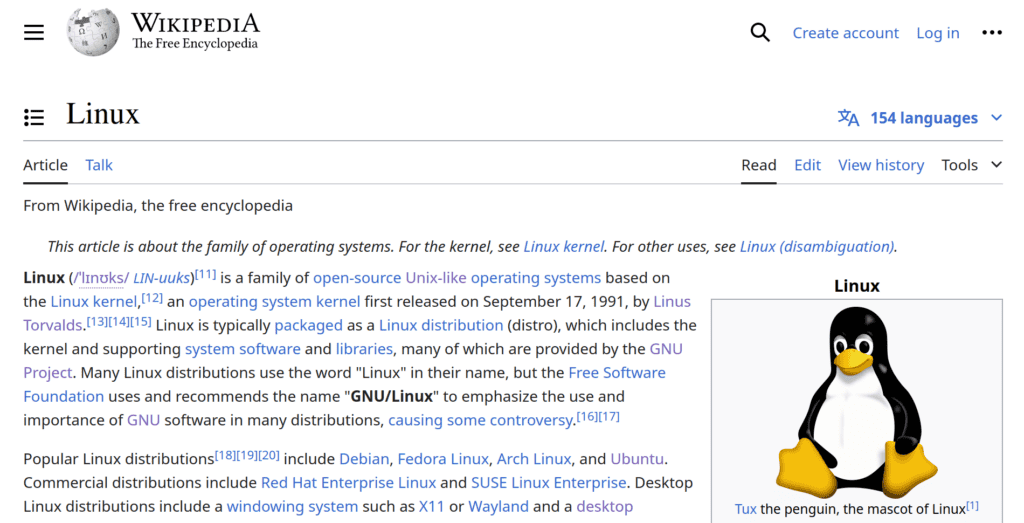
However, there will always be an inherent limitation in downloading web pages with wget: Interactive content will not work. To prove that, let’s download the Wikipedia page with a comparison of Linux distributions with the same options as before:
$ wget -p \
--user-agent="Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)\
Ubuntu Chromium/83.0.4103.61 Chrome/83.0.4103.61 Safari/537.36"\
https://en.wikipedia.org/wiki/Comparison_of_Linux_distributionsThe web page we get feels like the one online:
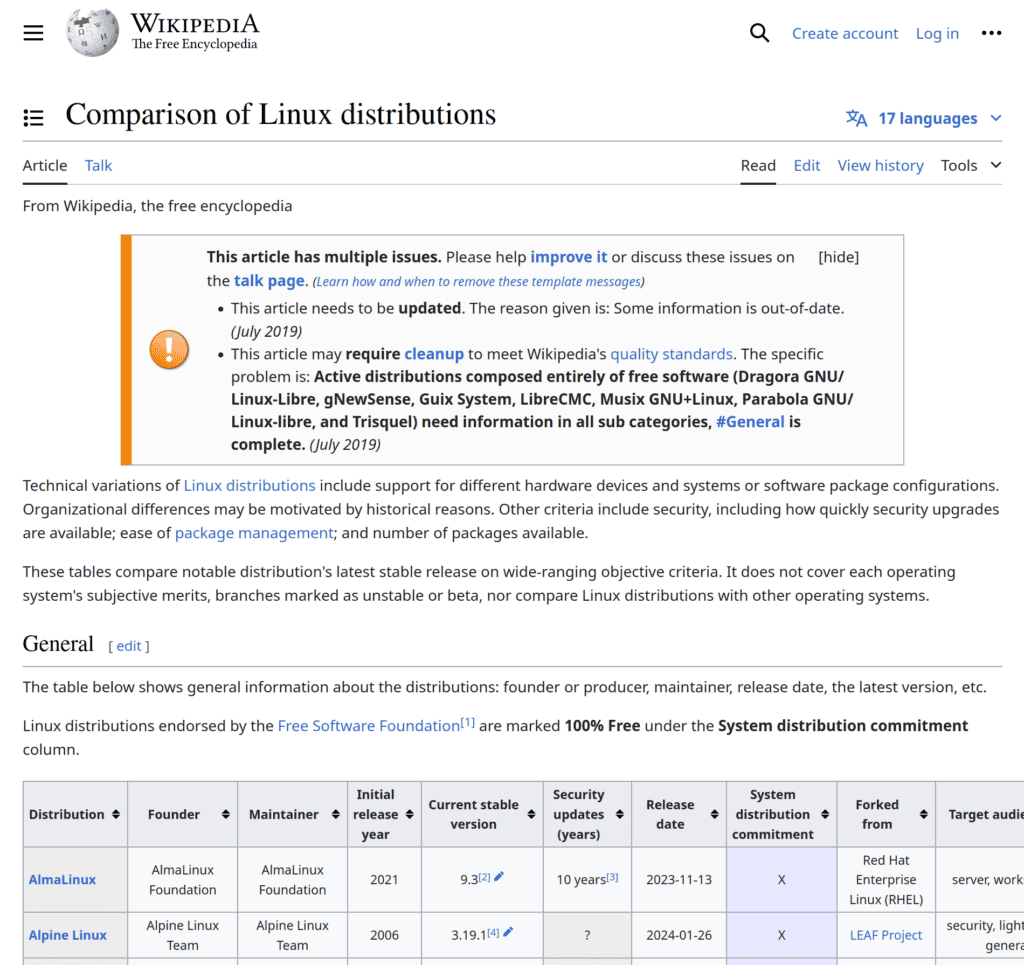
Even so, clicking on the arrows to order the content of the table will not work. There’s a difference between the initial web page response from a server to the browser (which is what wget downloads) and the web page returned after running some scripts on the client side. This may include JavaScript but also other scripting languages.
In this case, the visual differences are not that significant, but the functional differences are. On the other hand, there are websites built around JavaScript whose content will be different from what we get from wget and the browser version.
3. Headless Mode of chromium
Without leaving the command-line interface, we can also use the headless mode of a browser like chromium to download a web page. To be more exact, we’ll download the HTML DOM, which stands for Document Object Model. This is a tree of the objects that make up a web page, and JavaScript will get everything it needs to generate a dynamic HTML.
We can dump the HTML DOM of the same web page as before:
$ chromium --headless --dump-dom --virtual-time-budget=10000 --timeout=10000\
--user-agent="Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)\
Ubuntu Chromium/83.0.4103.61 Chrome/96.0.4664.93 Safari/537.36"\
https://en.wikipedia.org/wiki/Comparison_of_Linux_distributions > file.htmlFirst, we specify the headless mode and that we want to dump the HTML DOM.
Then, we add some flags to get a fully loaded web page. The –virtual-time-budget option instructs to wait for the page to load (which doesn’t mean waiting that long if the requested page is available before). This will ensure that we get the final result after all the scripts have loaded. However, in the case of interactive pages or AJAX requests, the –virtual-time-budget option may cause an unsuccessful execution of the dump. The –timeout option is also given to ensure that the process doesn’t hang forever if something goes wrong.
Finally, we also provide the same user agent as before, together with the web address of the web page. We need to pipe the output to a file that will store the HTML DOM.
In this case, the resulting web page is similar to before, but the sorting of the table is still not working. However, the results between wget and chromium in headless mode may vary depending on the web page we’re trying to download.
Similar commands for headless mode are available for other browsers such as firefox and chrome-browser.
4. Using Other Dedicated Tools
There are a bunch of other tools that we can use to download web pages from the command line. Some of these tools have been envisioned to extend wget and improve on some of its drawbacks.
4.1. httrack Utility
The first of these tools worth mentioning is httrack, which is a web crawler and offline browser. We can invoke it from the CLI directly:
$ httrack -r0 https://en.wikipedia.org/wiki/Comparison_of_Linux_distributionsSince httrack is a web crawler, it will try to download all the web pages whose links are contained in the link we provide, and recursively until it gets everything. Thus, we need to specify the recursion depth to 0 with -r0.
However, the main limitation of httrack is the same as wget: httrack doesn’t support JavaScript. Thus, the results obtained with it will be rather similar to those of wget.
4.2. Python Tool: hlspy
Another useful tool is hlspy, whose main objective is to support features such as heavy JavaScript usage in a tool like wget. It runs on Python, and we can even install it with pip.
Let’s download the same web page from the CLI with this tool:
$ hlspy https://en.wikipedia.org/wiki/Comparison_of_Linux_distributions --print-request --output=file.htmlWe specify the –print-request flag to get the resource requested by the web page and –output to store it in a file.
According to its developers, hlspy supports JavaScript. However, in this case, the sorting of the table is still not working. In general, hlspy is more powerful than wget to retrieve complex web pages, but setting it up might be more tricky in some systems.
4.3. JavaScript-Built phantomjs
Finally, we can also turn to phantomjs — a headless browser whose target is the automation of web page interaction. As its name suggests, phantomjs supports JavaScript. We need a script to load the content of the web page that we’ll provide as an argument in the command line:
$ cat download_web_page.js
var page = require('webpage').create();
page.open(require('system').args[1], function()
{
console.log(page.content);
phantom.exit();
});
With this, we can call phantomjs to download the web page:
$ phantomjs download_web_page.js https://en.wikipedia.org/wiki/Comparison_of_Linux_distributions > file.html
This tool has several drawbacks: phantomjs is a discontinued project, links generated with JavaScript will still not work, and it only downloads one site at a time (without support for web crawling).
5. Conclusion
In this article, we’ve reviewed several ways to download a web page so that we get the same view and content as in a browser. We’ve considered the ubiquitous wget tool as a first resort to attempt this download. The headless mode of browsers such as chromium also provides a potential solution to the problem.
Finally, if we need the highest accuracy and most functionalities, we can always rely on dedicated tools such as httrack, hlspy, or phantomjs.