

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Parallelization is the practice of running multiple processes simultaneously to reduce execution time and improve efficiency.
In this tutorial, we’ll discuss the basics of parallelization within Bash scripting, from simple methods to more sophisticated tools. We’ll also discuss when it’s beneficial to parallelize within a for loop.
Here, we’ll look at the syntax and commands that are essential to achieving parallelization in Bash scripting.
When a command is appended with the & symbol in Bash, it runs in the background. This means that the shell doesn’t wait for the command to complete and immediately returns control to the user. However, we can use the wait command to pause the execution of the script until all background jobs have finished.
For example, let’s consider a scenario where we need to download several files at once:
#!/bin/bash
# Start multiple downloads in the background using a for loop
for id in 237 238 239; do
wget -q https://picsum.photos/id/$id/1000 -O img$id.jpg &
done
# Wait for all background jobs to finish
wait
echo "All downloads completed:"
ls *.jpgIn this example, three wget commands run in the background to download files simultaneously. The wait command instead halts the progress of the script until all downloads are complete:
$ ./test.sh
All downloads completed:
img237.jpg img238.jpg img239.jpgThis approach is particularly useful when running tasks in parallel reduces the overall execution time.
The xargs command reads items from standard input and executes the specified command once for each item. Its -P option specifies the maximum number of processes to run simultaneously. If we set -P to 0, xargs will run as many processes simultaneously as possible.
For example, let’s use gzip to compress *.txt files in parallel:
#!/bin/bash
echo "Before: "; ls *.txt
find . -type f -name '*.txt' -print0 | xargs -0 -P 4 -I {} gzip "{}"
echo "After: "; ls *.gzLet’s break down the syntax:
The final echo runs after all processes started by xargs have finished. Here is the result:
$ ./test.sh
Before:
example1.txt example2.txt example3.txt
After:
example1.txt.gz example2.txt.gz example3.txt.gz
It’s worth noting that limiting the number of parallel processes, as in this case with -P 4, prevents system overload.
Combining a for loop with xargs makes sense when we need to preprocess or filter data before running some tasks in parallel. For example, a for loop can iterate over each file, check a condition such as file size, and then use xargs to parallelize a job on only the eligible files:
#!/bin/bash
echo "File sizes before image resizing:"
find . -name '*.jpg' -exec du -h --apparent-size {} + | sort -h
for file in *.jpg; do
if [[ $(stat -c %s "$file") -gt 102400 ]]; then # Check if file size is greater than 100KB
echo "$file"
fi
done | xargs -P 4 -I {} mogrify -resize 50% "{}"
echo "File sizes after image resizing:"
find . -name '*.jpg' -exec du -h --apparent-size {} + | sort -hWe used du and stat to get the file sizes, sort to order the results by file size, and mogrify to resize the images. Here is the output:
$ ./test.sh
File sizes before image resizing:
103K ./img237.jpg
118K ./img239.jpg
186K ./img238.jpg
File sizes after image resizing::
39K ./img237.jpg
40K ./img239.jpg
68K ./img238.jpg
Also, in this case, we limited the number of parallel processes.
GNU parallel can distribute and execute commands in parallel on our machine or on multiple remote servers.
Let’s install it on our local and remote machines and set up SSH key-based authentication. Then, let’s look at this basic example, assuming we have root access to the servers at the given IPs:
#!/bin/bash
export LC_ALL=en_US.UTF-8 # Optional, helps prevent locale issues
export LANG=en_US.UTF-8 # Optional, helps prevent locale issues
# /usr/bin/time invokes the system's time command instead of the shell's built-in version
/usr/bin/time -f '%e' ssh [email protected] hostname
/usr/bin/time -f '%e' ssh [email protected] hostname
/usr/bin/time -f '%e' parallel --sshlogin [email protected],[email protected] --nonall hostname
In this case, time measures the execution time of hostname on two separate servers, sequentially. Then, it repeats the time measurement by running the two hostname commands in parallel. The –nonall option tells GNU parallel to execute the given command on every specified server:
$ ./test.sh
informatica-libera.net
6.43
galgani.it
7.51
informatica-libera.net
galgani.it
7.34With GNU parallel, the hostname command runs on both servers at the same time. This reduces the total time to approximately the duration of the longer of the two parallel executions.
By comparison, we can do the same thing with xargs, but it’s less straightforward:
$ /usr/bin/time -f '%e' sh -c 'printf "[email protected]\[email protected]\n" \
| xargs -I {} -P 2 ssh {} hostname'
informatica-libera.net
galgani.it
7.66For advanced tasks involving more complex scripting, xargs is cumbersome and difficult to use compared to GNU parallel.
By default, both GNU parallel and xargs -P print the output of the jobs as they finish, so the order of their output may be unpredictable. To overcome this issue, GNU parallel‘s –keep-order / -k option ensures that the output matches the order of the input as if the jobs were running sequentially instead of in parallel.
Let’s compare xargs to GNU parallel‘s –keep-order:
#!/bin/bash
echo "Using GNU Parallel:"
parallel --keep-order 'sleep $((4-{})); echo Arg{}' ::: 1 2 3
echo "-------------------------"
echo "Using xargs:"
echo 1 2 3 | xargs -n1 -P3 sh -c 'sleep $((4-$1)); echo "Arg$1"' _Let’s look at some of the details:
To summarize, both GNU parallel and xargs do parallel printing of Arg1 after a three-second pause, Arg2 after a two-second pause, and Arg3 after a one-second pause. Here is the result:
$ ./test.sh
Using GNU Parallel:
Arg1
Arg2
Arg3
-------------------------
Using xargs:
Arg3
Arg2
Arg1
In conclusion, –keep-order is critical for jobs where the order of output affects subsequent processing or analysis.
Using GNU parallel inside a Bash for loop provides an efficient way to handle tasks that require both sequential and parallel processing. Here’s a self-explanatory example where a for loop goes through a series of iterations, and within each iteration, GNU parallel speeds up a job called process_task:
#!/bin/bash
# Simple parallel task function with variable duration
process_task() {
# Generate a random sleep time between 1 and 5 seconds
local sleep_time=$((RANDOM % 5 + 1))
echo "Processing $1, it requires $sleep_time seconds"
sleep $sleep_time # Represents a task that takes time
echo "$1 done"
}
# This export makes the "process_task()" function available in GNU parallel's subshells
export -f process_task
# For loop with parallel tasks inside
for i in {1..3}; do
echo "Iteration $i starts"
# Execute process_task in parallel with random sleep times
parallel --keep-order process_task ::: "${i}_A" "${i}_B"
echo "Iteration $i ends"
done
echo "All done."
Its output demonstrates an efficient use of resources without disrupting the sequential flow of the loop’s main logic:
$ ./test.sh
Iteration 1 starts
Processing 1_A, it requires 3 seconds
1_A done
Processing 1_B, it requires 2 seconds
1_B done
Iteration 1 ends
Iteration 2 starts
Processing 2_A, it requires 4 seconds
2_A done
Processing 2_B, it requires 5 seconds
2_B done
Iteration 2 ends
[...]
All done.In this case, we used –keep-order to get the output in the same order as the functions are called.
A multi-core CPU can perform multiple operations simultaneously, each on its own core, allowing true parallelization. This is in contrast to concurrency or multitasking, where a core switches between tasks, making simultaneous execution an illusion:
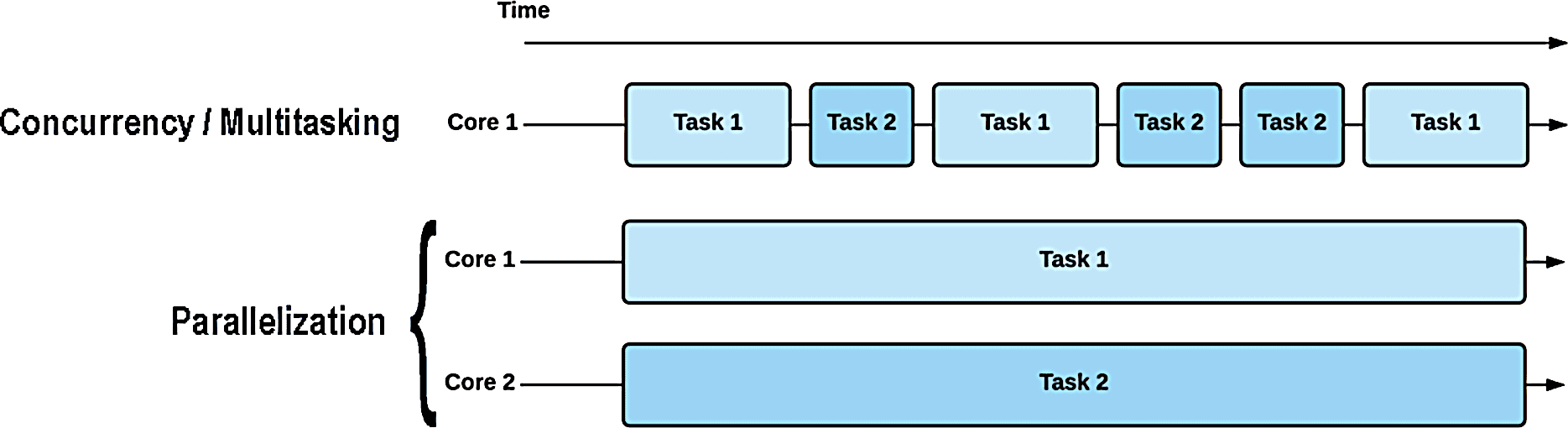
Limiting the number of CPU-intensive parallel processes to the number of available cores can be a strategy for achieving true parallelization, assuming that the operating system actually assigns each process to a different core, a certainty we cannot always rely on. Another strategy is to set processor affinity, which allows us to specify which cores should execute the processes designated for parallelization.
On the other hand, if our parallel processes have low CPU usage and heavily consume other resources, such as Internet bandwidth, RAM, or disk I/O, then we need to do other analyses. In such cases, the use of a semaphore may be the most appropriate solution.
The –jobs / -j option of GNU parallel controls the number of jobs to run in parallel. For example, parallel -j 4 would run 4 jobs in parallel. This approach is straightforward but only works well if we have a clear understanding of our system’s capabilities and the requirements of our jobs.
The -j option also takes a percentage value to allocate a portion of our CPU cores to our jobs. For example, parallel -j 50% will use half of the available CPU cores. This is useful when the exact number of available cores varies or is unknown.
Even better, GNU parallel can automatically adjust the number of jobs based on the current system load, ensuring that we use our system’s resources efficiently without overloading it. We can achieve this by combining the -j and –load options:
$ parallel --load 75% -j -1 <command>In this example, <command> represents the job we want to run in parallel. The –load 75% option causes GNU parallel to monitor the average system load and only start new jobs when the load is below 75% of the maximum. The -j -1 option asks GNU parallel to use all available CPU resources, leaving one core free for system tasks and other applications.
The –semaphore option allows shared resource limits between different GNU parallel invocations, unlike the -j option, which is limited to a single command. This feature is invaluable for ensuring that concurrent tasks, especially those from separate commands, don’t overload shared resources such as network bandwidth.
For example, we can use a semaphore to prevent overloading our network when downloading files:
#!/bin/bash
# Use GNU Parallel with semaphore to limit the 300 images downloads to 4 in parallel
for id in {1..300}; do
parallel --semaphore --id 'network_tasks' -j 4 \
"wget -q https://picsum.photos/id/$id/1000 -O img$id.jpg && echo Download of image $id completed"
done
# Release the semaphore after all downloads are complete
parallel --semaphore --id $semaphoreID --waitThe –semaphore –id ‘network_tasks’ ensures that the -j 4 limit is respected by all jobs using the same semaphore ID, providing a coordinated approach to resource management. Let’s remember to use the –wait option as in the last line to hold the script until all jobs managed by the specified semaphore ID have finished:
$ ./test.sh
Download of image 3 completed
Download of image 2 completed
Download of image 4 completed
Download of image 1 completed
[...]As a final note, the use of semaphore is incompatible with the ::: syntax, and it also limits the ability to pass arguments from a list or file directly to parallelized jobs within the same command, requiring alternative methods of argument distribution. In this case, we needed a for loop to pass the arguments.
To optimize parallel tasks by binding them to specific CPU cores, we can use taskset within GNU parallel. This method reduces the number of times a task switches between different CPU cores and reduces the likelihood that the CPU will need to reload data into its cache. As a result, tasks run more efficiently and faster.
Let’s look at a minimal example:
#!/bin/bash
# Define a function that simulates a CPU-bound task
cpu_task() {
# Get the current process's CPU affinity
core_id=$(taskset -cp $$ | awk '{print $NF}')
echo "Running on core $core_id"
sleep 2 # Simulate a task
}
export -f cpu_task # Make the function available to subshells
# Get the number of available CPU cores
num_cores=$(nproc)
# Use GNU Parallel with taskset to run the function on specific cores
parallel -j $num_cores taskset -c {} bash -c cpu_task ::: $(seq 0 $((num_cores - 1)))The result is as expected:
$ ./test.sh
Running on core 0
Running on core 1
Running on core 2
Running on core 3
Running on core 4
Running on core 5
Running on core 6
Running on core 7This taskset approach is preferable when precise control over CPU core allocation is required to optimize performance for CPU-intensive tasks, ensuring that they run on dedicated cores without interference from other processes.
In this article, we explored parallelization in Bash, starting with background processes using & and wait. Then we looked at xargs and for loops to improve parallel execution.
As we discussed CPU core considerations, GNU parallel emerged as a superior choice for distributing commands not only locally, but also across remote servers. We also saw how to set processor affinity with taskset to optimize CPU-bound tasks.
These techniques can significantly improve the performance of our scripts, making parallelization a key strategy in Bash.