

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll dive into a powerful and well-known process synchronization tool: semaphore.
We’ll look into semaphore operations, types, and its implementation. Then we’ll explore some multi-threaded cases where the use of semaphores helps us with overcoming possible process synchronization problems.
A semaphore is an integer variable, shared among multiple processes. The main aim of using a semaphore is process synchronization and access control for a common resource in a concurrent environment.
The initial value of a semaphore depends on the problem at hand. Usually, we use the number of resources available as the initial value. In the following sections, we’ll give more examples of initializing semaphores in different use cases.
It’s a synchronization tool that does not require busy waiting. Hence, the operating system does not waste the CPU cycles when a process can’t operate due to a lack of access to a resource.
A semaphore has two indivisible (atomic) operations, namely:  and
and  . These operations are sometimes referred to as
. These operations are sometimes referred to as  and
and  , or
, or  and
and  in some contexts.
in some contexts.
In this article, let’s focus on semaphores implemented in the operating system kernel. Therefore, the  and
and  operations are implemented as system calls.
operations are implemented as system calls.
Let  be a semaphore, and its integer value represents the amount of some resource available. Now let’s examine how the
be a semaphore, and its integer value represents the amount of some resource available. Now let’s examine how the  operation works:
operation works:
function wait(S):
// This function represents the 'wait' operation for a semaphore.
if S > 0:
// Do not block the process
S <- S - 1
return
else:
// Block the calling process
sleep
The function simply decrements if it’s greater than zero (there are available resources to allocate). If is already zero (there are no available resources to allocate), the calling process is put to sleep.
Now let’s examine the operation:
function signal(S):
// This function represents the 'signal' or 'release' operation for a semaphore.
if there are processes sleeping on S:
// Wake up a blocked process
select a process to wake up
wake up the selected process
return
else:
// No process is waiting on S
S <- S + 1
returnThe operation increments S, if there are no other processes are waiting for the resource. Otherwise, instead of incrementing its value, a waiting process is selected to be wakened up by the operating system scheduler. As a result, that process gains control of the resource.
There are two types of semaphores:
A binary semaphore can have only two integer values: 0 or 1. It’s simpler to implement and provides mutual exclusion. We can use a binary semaphore to solve the critical section problem.
Some experienced readers might confuse binary semaphores with a mutex. There’s a common misconception that they can be used interchangeably. But in fact, a semaphore is a signaling mechanism where on the other hand, a mutex is a locking mechanism. So, we need to know that binary semaphore is not a mutex.
A counting semaphore is again an integer value, which can range over an unrestricted domain. We can use it to resolve synchronization problems like resource allocation.
As stated above, we focus on semaphores implemented in the operating system kernel.
An implementation with no busy waiting requires an integer value (to hold semaphore value) and a pointer to the next process in the waiting list. The list consists of processes that are put to sleep on the operation. The kernel uses two additional operations:  and
and  , to command the processes.
, to command the processes.
We can think of semaphore implementation as a critical section problem since we don’t want more than one process accessing the semaphore variable concurrently.
Several programming languages have support for concurrency and semaphores. For example, Java supports semaphores, and we can use them in our multi-threaded programs.
In a multi-threaded environment, process synchronization means efficiently sharing of system resources by concurrent processes. Ensuring synchronized execution requires a way to coordinate processes that use shared data. A satisfactory synchronization mechanism provides concurrency on top of avoiding deadlocks and starvation.
With careful use, a semaphore is a powerful synchronization tool that can enable process synchronization. Let’s examine how we can take care of some problems next.
A deadlock occurs when a group of processes is blocked in a state waiting for some other member’s action. To avoid possible deadlocks, we need to be careful about how we implement the semaphores. Let’s examine a case of deadlock:
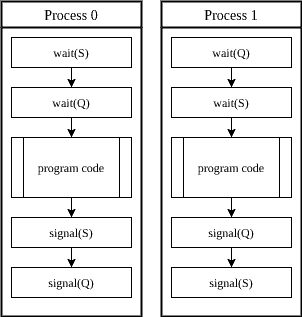
Here,  and
and  have some code that should run separately.
have some code that should run separately.
Consider a case when executes wait() and interrupted immediately after that. Then let’s assume starts running. Initially, waits on semaphore  , and then it is blocked on wait() statement, so it is put to sleep.
, and then it is blocked on wait() statement, so it is put to sleep.
When the kernel runs again, the next operation in line is waiting (). As semaphore is already in use by , now we have a situation where both processes are waiting for each other, hence, a deadlock.
If we were to reverse the order of the lines in any of the processes and used a common ordering, we would omit the deadlock in this example.
The next concept we need to be careful about is starvation. Starvation means indefinite blocking of a process. For instance, a deadlock situation might cause starvation for some processes.
A famous starvation example is the Dining Philosophers problem, which we’ll cover in the following sections. In this problem, five philosophers are sitting around a circular table. They share five chopsticks. Each philosopher either think or eat. To eat, a philosopher needs two chopsticks:
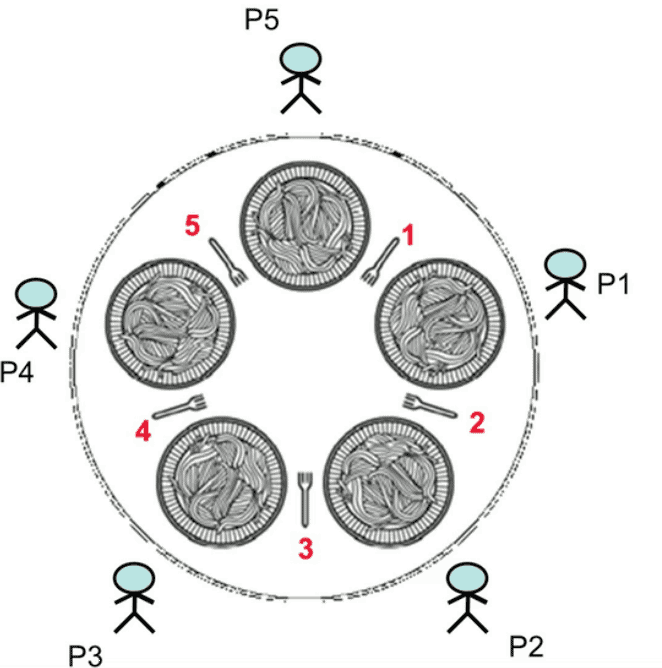
This hypothetical problem symbolizes starvation. If a philosopher’s process is blocked forever due to lack of access to chopsticks, it will starve.
Using process synchronization, we want to make sure that each process will get service sooner or later.
Another possible problem that might be caused by the inefficient use of semaphores is priority inversion. Priority inversion happens when a lower priority job takes precedence over a higher priority job.
Let’s imagine that a low priority process is holding a semaphore, which is needed by a higher priority process. Further, assume that a medium priority process is waiting in the scheduler queue as well:
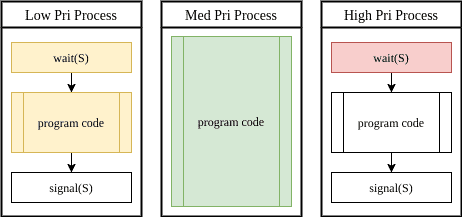
In this case, the kernel would not schedule the low priority process blocking the high priority one. Instead, the kernel proceeds with the medium priority job, causing the high priority job to keep waiting.
A possible solution is using priority inheritance on semaphores.
Now that we have defined what a semaphore is let’s explore some use cases of semaphores.
The critical section is a part of the program code, where we want to avoid concurrent access. We can use a binary semaphore to solve the critical section problem. In this case, the semaphore’s initial value is 1 in the kernel:
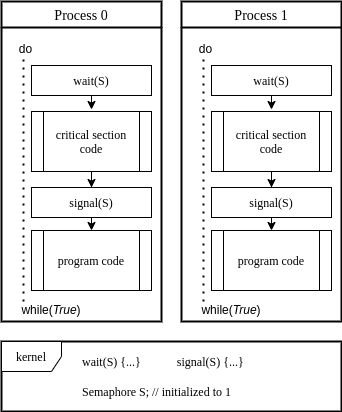
In the above example, we guarantee mutual exclusion in critical section access.
Instead of busy waiting, the waiting process is sleeping as it’s waiting for its turn on the critical section.
Then the signal operation is performed, kernel adds a sleeping process to the ready queue. If the kernel decides to run the process, it will continue into the critical section.
In this way, we ensure that only one process is in the critical section at any time.
Suppose we want to execute code fragment  before
before  . In other words, we want to wait before executing until completes execution of :
. In other words, we want to wait before executing until completes execution of :
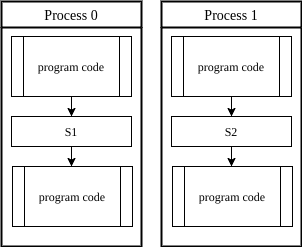
We can easily overcome this problem by using a semaphore, with its initial value set to 0. Let’s modify the code:

By using semaphore  , we guarantee that the waits before executing the section until is done with the execution of .
, we guarantee that the waits before executing the section until is done with the execution of .
Let’s consider the well-known producer-consumer problem next. In this problem, there’s a limited buffer, consisting of  cells. In other words, the buffer can store a maximum of elements. Two processes are accessing the buffer, namely:
cells. In other words, the buffer can store a maximum of elements. Two processes are accessing the buffer, namely:  and
and  .
.
To overcome this problem, we use a counting semaphore representing the number of full cells:
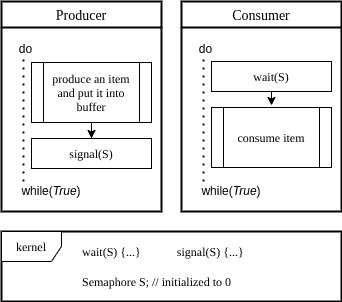
Initially,  . As the producer puts an item into the buffer, it increases the semaphore by a signal operation. On the contrary, when the consumer consumes an item, by wait operation, the semaphore is decreased.
. As the producer puts an item into the buffer, it increases the semaphore by a signal operation. On the contrary, when the consumer consumes an item, by wait operation, the semaphore is decreased.
When a consumer uses the last item in the buffer, it’s put to sleep by the last wait operation.
On top of the solution above, we can force the producer to sleep if the buffer is full by adding two more semaphores. Say we introduce semaphore  representing the number of available cells in the buffer. We also introduce the semaphore
representing the number of available cells in the buffer. We also introduce the semaphore  , representing the number of full cells in the buffer. In this case, we use semaphore on the buffer. Again, the producer and the consumer process run concurrently.
, representing the number of full cells in the buffer. In this case, we use semaphore on the buffer. Again, the producer and the consumer process run concurrently.
We modify the producer and consumer code to include the semaphores:

Here, the counting semaphore represents the number of full cells, while the counting semaphore represents the number of cells available on the bounded buffer. Moreover, the semaphore S protects the buffer against concurrent access.
Let’s first observe the producer’s behavior:
If the semaphore becomes 0, the producer goes to sleep as there are no more empty cells in the buffer.
Further, the producer waits on semaphore before accessing the buffer. If another process is already waiting on , it goes to sleep.
After producing a new item, the producer signals the semaphore, hence triggering waking up any possible consumers any waiting processes.
Similarly, the consumer uses the same semaphores:
If the semaphore is zero, then there are no items waiting in the buffer. The consumer is put to sleep.
The wait operation on ensures that the buffer is accessed by only one process at a given time. So, the signal on wakes up any processes waiting.
Then finally, the signal on the semaphore wakes up any producer that has something to put into the buffer. In the end, the consumer is ready to consume the next item.
This solution ensures that the producer sleeps until there’s a slot available in the buffer. On the contrary, a consumer sleeps until there are items to consume.
This problem has several  and
and  , working on the same data set. The
, working on the same data set. The  processes only read the data set; they do not perform any updates. Whereas the
processes only read the data set; they do not perform any updates. Whereas the  processes can both read and write.
processes can both read and write.
The synchronization problem we have here is to enable only one writer to access the data set at any given time. We can allow multiple readers to read at the same time without any problem.
Assume we have a lock on the data set. The first should lock the data set and then the after that can go ahead and start reading. The last should release the lock when it finishes reading.
When a starts reading or stops reading, it should lock/unlock the data set for other and .
To enable process synchronization in this problem, we can use an integer value and two semaphores.
Let’s initialize the integer  to zero, which represents the number of accessing the file. This isn’t a semaphore, only an integer.
to zero, which represents the number of accessing the file. This isn’t a semaphore, only an integer.
Also, let’s initialize the semaphore to 1, which protects the variable from being updated by multiple processes.
Last of all, let’s assume we initialize the semaphore  to 1, which protects the data set from being accessed at the same time by multiple . So the pseudo-code for and processes:
to 1, which protects the data set from being accessed at the same time by multiple . So the pseudo-code for and processes:
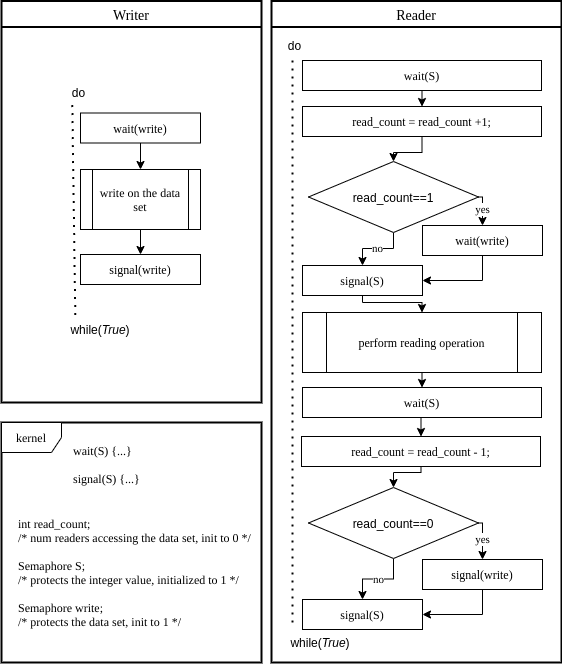
In this case, the only waits and signals on the semaphore . If it can acquire the semaphore, it can go on. Otherwise, the wait operation blocks it.
As soon as the writing operation is complete, the writer signals the semaphore . So, other processes can access the data set.
A ‘s workflow is more complicated. The first thing it does is to increment the  . To do so, the needs to acquire the semaphore to modify the value, to make sure it’s not accessed simultaneously by multiple processes.
. To do so, the needs to acquire the semaphore to modify the value, to make sure it’s not accessed simultaneously by multiple processes.
If no other is accessing the data set at the moment, the becomes one after the increment operation. In this case, the waits on semaphore before accessing the data set, to ensure that no writer is accessing.
After releasing the semaphore , the goes ahead and performs the reading operation.
At last, when the completes working with the data set, it needs to decrement the value. Again, it acquires the semaphore , changes the variable, and finally releases the semaphore .
The Dining Philosophers problem is a well-known thought experiment to test a synchronization tool.
We have five philosophers sitting around a table with five chopsticks. Whenever the philosopher wants to eat, it needs to acquire two chopsticks. In this problem, chopsticks are the resources we want to synchronize among processes.
Let’s implement a solution using semaphores. First of all, we initialize the semaphore, which represents five chopsticks as an array of 5. Then, we implement a  as:
as:
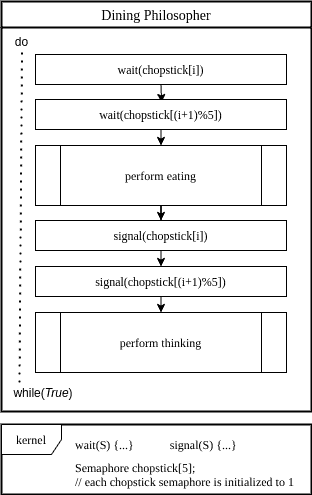
In this solution, when philosopher  decides to eat, it first waits on semaphore . Then after acquiring it, the philosopher waits on semaphore
decides to eat, it first waits on semaphore . Then after acquiring it, the philosopher waits on semaphore  . When both chopsticks are acquired, it can eat.
. When both chopsticks are acquired, it can eat.
When the philosopher is full, it releases the chopsticks in the same order, by calling the signal operation on the respective semaphore.
We need to keep in mind that this example does not guarantee a deadlock-free solution. We can implement a small tweak to guarantees all three conditions.
A semaphore is a very powerful process synchronization tool.
In this tutorial, we’ve summarized the working principle of semaphores first by defining the two atomic operations: wait and signal. After gaining a better understanding of possible process synchronization problems, we’ve covered some examples to better understand how to use a semaphore effectively.