

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
In this tutorial, we’ll explore the concept of searching for neighbors in a two-dimensional space. Then, we’ll walk through its implementation in Java.
2. One-Dimensional Search vs Two-Dimensional Search
We know that binary search is an efficient algorithm for finding an exact match in a list of items using a divide-and-conquer approach.
Let’s now consider a two-dimensional area where each item is represented by XY coordinates (points) in a plane.
However, instead of an exact match, suppose we want to find neighbors of a given point in the plane. It’s clear that if we want the nearest n matches, then the binary search will not work. This is because the binary search can compare two items in one axis only, whereas we need to be able to compare them in two axes.
We’ll look at an alternative to the binary tree data structure in the next section.
3. Quadtree
A quadtree is a spatial tree data structure in which each node has exactly four children. Each child can either be a point or a list containing four sub-quadtrees.
A point stores data — for example, XY coordinates. A region represents a closed boundary within which a point can be stored. It is used to define the area of reach of a quadtree.
Let’s understand this more using an example of 10 coordinates in some arbitrary order:
(21,25), (55,53), (70,318), (98,302), (49,229), (135,229), (224,292), (206,321), (197,258), (245,238)The first three values will be stored as points under the root node as shown in the left-most picture.
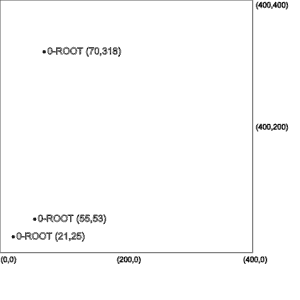
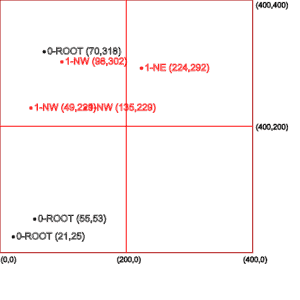
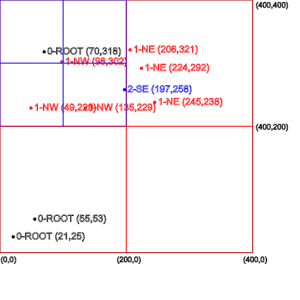
The root node cannot accommodate new points now as it has reached its capacity of three points. Therefore, we’ll divide the region of the root node into four equal quadrants.
Each of these quadrants can store three points and additionally contain four quadrants within its boundary. This can be done recursively, resulting in a tree of quadrants, which is where the quadtree data structure gets its name.
In the middle picture above, we can see the quadrants created from the root node and how the next four points are stored in these quadrants.
Finally, the right-most picture shows how one quadrant is again subdivided to accommodate more points in that region while the other quadrants still can accept the new points.
We’ll now see how to implement this algorithm in Java.
4. Data Structure
Let’s create a quadtree data structure. We’ll need three domain classes.
Firstly, we’ll create a Point class to store the XY coordinates:
public class Point {
private float x;
private float y;
public Point(float x, float y) {
this.x = x;
this.y = y;
}
// getters & toString()
}Secondly, let’s create a Region class to define the boundaries of a quadrant:
public class Region {
private float x1;
private float y1;
private float x2;
private float y2;
public Region(float x1, float y1, float x2, float y2) {
this.x1 = x1;
this.y1 = y1;
this.x2 = x2;
this.y2 = y2;
}
// getters & toString()
}Finally, let’s have a QuadTree class to store data as Point instances and children as QuadTree classes:
public class QuadTree {
private static final int MAX_POINTS = 3;
private Region area;
private List<Point> points = new ArrayList<>();
private List<QuadTree> quadTrees = new ArrayList<>();
public QuadTree(Region area) {
this.area = area;
}
}To instantiate a QuadTree object, we specify its area using the Region class through the constructor.
5. Algorithm
Before we write our core logic to store data, let’s add a few helper methods. These will prove useful later.
5.1. Helper Methods
Let’s modify our Region class.
Firstly, let’s have a method containsPoint to indicate if a given point falls inside or outside of a region’s area:
public boolean containsPoint(Point point) {
return point.getX() >= this.x1
&& point.getX() < this.x2
&& point.getY() >= this.y1
&& point.getY() < this.y2;
}Next, let’s have a method doesOverlap to indicate if a given region overlaps with another region:
public boolean doesOverlap(Region testRegion) {
if (testRegion.getX2() < this.getX1()) {
return false;
}
if (testRegion.getX1() > this.getX2()) {
return false;
}
if (testRegion.getY1() > this.getY2()) {
return false;
}
if (testRegion.getY2() < this.getY1()) {
return false;
}
return true;
}Finally, let’s create a method getQuadrant to divide a range into four equal quadrants and return a specified one:
public Region getQuadrant(int quadrantIndex) {
float quadrantWidth = (this.x2 - this.x1) / 2;
float quadrantHeight = (this.y2 - this.y1) / 2;
// 0=SW, 1=NW, 2=NE, 3=SE
switch (quadrantIndex) {
case 0:
return new Region(x1, y1, x1 + quadrantWidth, y1 + quadrantHeight);
case 1:
return new Region(x1, y1 + quadrantHeight, x1 + quadrantWidth, y2);
case 2:
return new Region(x1 + quadrantWidth, y1 + quadrantHeight, x2, y2);
case 3:
return new Region(x1 + quadrantWidth, y1, x2, y1 + quadrantHeight);
}
return null;
}5.2. Storing Data
We can now write our logic to store data. Let’s start by defining a new method addPoint on the QuadTree class to add a new point. This method will return true if a point was successfully added:
public boolean addPoint(Point point) {
// ...
}Next, let’s write the logic to handle the point. First, we need to check if the point is contained within the boundary of the QuadTree instance. We also need to ensure that the QuadTree instance has not reached the capacity of MAX_POINTS points.
If both the conditions are satisfied, we can add the new point:
if (this.area.containsPoint(point)) {
if (this.points.size() < MAX_POINTS) {
this.points.add(point);
return true;
}
}On the other hand, if we’ve reached the MAX_POINTS value, then we need to add the new point to one of the sub-quadrants. For this, we loop through the child quadTrees list and call the same addPoint method which will return a true value on successful addition. Then we exit the loop immediately as a point needs to be added exactly to one quadrant.
We can encapsulate all this logic inside a helper method:
private boolean addPointToOneQuadrant(Point point) {
boolean isPointAdded;
for (int i = 0; i < 4; i++) {
isPointAdded = this.quadTrees.get(i)
.addPoint(point);
if (isPointAdded)
return true;
}
return false;
}Additionally, let’s have a handy method createQuadrants to subdivide the current quadtree into four quadrants:
private void createQuadrants() {
Region region;
for (int i = 0; i < 4; i++) {
region = this.area.getQuadrant(i);
quadTrees.add(new QuadTree(region));
}
}We’ll call this method to create quadrants only if we’re no longer able to add any new points. This ensures that our data structure uses optimum memory space.
Putting it all together, we’ve got the updated addPoint method:
public boolean addPoint(Point point) {
if (this.area.containsPoint(point)) {
if (this.points.size() < MAX_POINTS) {
this.points.add(point);
return true;
} else {
if (this.quadTrees.size() == 0) {
createQuadrants();
}
return addPointToOneQuadrant(point);
}
}
return false;
}5.3. Searching Data
Having our quadtree structure defined to store data, we can now think of the logic for performing a search.
As we’re looking for finding adjacent items, we can specify a searchRegion as the starting point. Then, we check if it overlaps with the root region. If it does, then we add all its child points that fall inside the searchRegion.
After the root region, we get into each of the quadrants and repeat the process. This goes on until we reach the end of the tree.
Let’s write the above logic as a recursive method in the QuadTree class:
public List<Point> search(Region searchRegion, List<Point> matches) {
if (matches == null) {
matches = new ArrayList<Point>();
}
if (!this.area.doesOverlap(searchRegion)) {
return matches;
} else {
for (Point point : points) {
if (searchRegion.containsPoint(point)) {
matches.add(point);
}
}
if (this.quadTrees.size() > 0) {
for (int i = 0; i < 4; i++) {
quadTrees.get(i)
.search(searchRegion, matches);
}
}
}
return matches;
}6. Testing
Now that we have our algorithm in place, let’s test it.
6.1. Populating the Data
First, let’s populate the quadtree with the same 10 coordinates we used earlier:
Region area = new Region(0, 0, 400, 400);
QuadTree quadTree = new QuadTree(area);
float[][] points = new float[][] { { 21, 25 }, { 55, 53 }, { 70, 318 }, { 98, 302 },
{ 49, 229 }, { 135, 229 }, { 224, 292 }, { 206, 321 }, { 197, 258 }, { 245, 238 } };
for (int i = 0; i < points.length; i++) {
Point point = new Point(points[i][0], points[i][1]);
quadTree.addPoint(point);
}6.2. Range Search
Next, let’s perform a range search in an area enclosed by lower bound coordinate (200, 200) and upper bound coordinate (250, 250):
Region searchArea = new Region(200, 200, 250, 250);
List<Point> result = quadTree.search(searchArea, null);Running the code will give us one nearby coordinate contained within the search area:
[[245.0 , 238.0]]Let’s try a different search area between coordinates (0, 0) and (100, 100):
Region searchArea = new Region(0, 0, 100, 100);
List<Point> result = quadTree.search(searchArea, null);Running the code will give us two nearby coordinates for the specified search area:
[[21.0 , 25.0], [55.0 , 53.0]]We observe that depending on the size of the search area, we get zero, one or many points. So, if we’re given a point and asked to find the nearest n neighbors, we could define a suitable search area where the given point is at the center.
Then, from all the resulting points of the search operation, we can calculate the Euclidean distances between the given points and sort them to get the nearest neighbors.
7. Time Complexity
The time complexity of a range query is simply O(n). The reason is that, in the worst-case scenario, it has to traverse through each item if the search area specified is equal to or bigger than the populated area.
8. Conclusion
In this article, we first understood the concept of a quadtree by comparing it with a binary tree. Next, we saw how it can be used efficiently to store data spread across a two-dimensional space.
We then saw how to store data and perform a range search.

















