

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Introduction
In this quick tutorial, we’ll show how to use RabbitMQ’s APIs related to two core concepts: Connections and Channels.
2. RabbitMQ Quick Recap
RabbitMQ is a popular implementation of the AMQP (Advanced Messaging Queue Protocol), widely used by companies of all sizes to handle their messaging needs.
From an application point of view, we’re usually concerned with AMQP’s main entities: Virtual Hosts, Exchanges, and Queues. As we’ve already covered those concepts in earlier articles, here, we’ll focus on the details of two less-discussed concepts: Connections and Channels.
3. Connections
The first step a client must take to interact with a RabbitMQ broker is to establish a Connection. AMPQ is an application-level protocol, so this connection happens on top of a transport-level one. This can be a regular TCP connection or an encrypted one using TLS. The main role of a Connection is to provide a secure conduit through which a client can interact with a broker.
This means that during connection establishment, a client must supply valid credentials to the server. A server may support different credential types, including regular username/password, SASL, X.509 password, or any supported mechanism.
Besides security, the connection establishment phase is also responsible for negotiating some aspects of the AMPQ protocol. At this point, if the client and/or server cannot agree on the protocol version or a tuning parameter value, the connection won’t be established, and the transport level connection will be closed.
3.1. Creating Connections in Java Applications
When using Java, the standard way to communicate with a RabbitMQ browser is to use the amqp-client Java library. We can add this library to our project using adding the corresponding Maven dependency:
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.16.0</version>
</dependency>
The latest version of this artifact is available on Maven Central.
This library uses the Factory pattern to create new connections. First, we create a new ConnectionFactory instance and set all parameters needed to create connections. At a minimum, this requires informing the address of the RabbitMQ host:
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("amqp.example.com");
Once we’re done setting those parameters, we use the newConnection() factory method to create a new Connection instance:
Connection conn = factory.newConnection();4. Channels
Simply put, an AMQP channel is a mechanism that allows multiplexing multiple logic flows on top of a single connection. This allows better resource usage both on the client and server side since setting up a connection is a relatively expensive operation.
A client creates one or more channels so it can send commands to the broker. This includes commands related to sending and/or receiving messages.
Channels also provide some additional guarantees regarding the protocol logic:
- Commands for a given channel are always executed in the same order they’re sent.
- Given a scenario where a client opens multiple channels over a single connection, implementations can distribute the available bandwidth between them
- Both parties can issue flow control commands, which inform the peer that it should stop sending messages.
A key aspect of a channel is that its lifecycle is bound to the connection used to create it. This means that if we close a connection, all associated channels will also be closed.
4.1. Creating Channels in Java Applications
Java applications using the amqp-client library create a new Channel from an existing Connection using the createChannel() method from the former:
channel = conn.createChannel();Once we have a Channel, we can send commands to the server. For instance, to create a queue, we use the queueDeclare() method:
channel.queueDeclare("example.queue", true, false, true, null);This code “declares” a queue, which is AMQP’s way of saying “create if not already existing”. The additional arguments after the queue name define its additional characteristics:
- durable: this declaration is persistent, meaning it will survive a server’s restart
- exclusive: this queue is restricted to the connection associated with the channel declaring it
- autodelete: the server will delete the queue once no longer in use
- args: optional map with arguments used to tune the queue behavior; for instance, we can use those arguments to define the TTL for messages and dead-letter behavior
Now, to post a message to this queue using the default exchange, we use the basicPublish() method:
channel.basicPublish("", queue, null, payload);This code sends a message to the default exchange using the queue name as its routing key.
5. Channel Allocation Strategies
Let’s consider a scenario where we use messaging systems: CQRS (Command Query Responsibility Segregation) applications. In a nutshell, CQRS-based applications have two independent paths: commands and queries. Commands can change data but never return values. Queries, on the other hand, return values but never modify them.
Since the command path never returns any data, the service can execute them asynchronously. In a typical implementation, we have an HTTP POST endpoint that internally builds a message and sends it to a queue for later processing.
Now, for a service that must handle dozens or even hundreds of concurrent requests, opening connections and channels every time is not a realistic option. Instead, a better approach is to use a channel pool.
Of course, this leads to the next problem: should we create a single connection and create channels from it or use multiple connections?
5.1. Single Connection/Multiple Channels
In this strategy, we’ll use a single connection and just create a channel pool with a capacity equal to the maximum number of concurrent connections the service can manage. For a traditional thread-per-request model, this should be set to the same size as the request handler thread pool.
The downside of this strategy is that, under heavier loads, the fact that we must send commands one at a time through the associated channel implies that we must use a synchronization mechanism. This, in turn, adds extra latency in the command path, which we want to minimize.
5.2. Connection-per-Thread Strategy
Another option is to go to the other extreme and use a Connection pool, so there’s never contention for a channel. For each Connection, we’ll create a single Channel that a handler thread will use to issue commands to the server.
However, the fact that we remove synchronization from the client side comes with a cost. The broker must allocate additional resources for each connection, such as socket descriptors and state information. Moreover, the server must split the available throughput between clients.
6. Benchmarking Strategies
To evaluate those candidate strategies, let’s run a simple benchmark for each one. The benchmark consists of running multiple workers in parallel that send one thousand messages of 4 Kbytes each. Upon construction, the worker receives a Connection from which it will create a Channel to send commands. It also receives the number of iterations, payload size, and a CountDownLatch used to inform the test runner that it has finished sending messages:
public class Worker implements Callable<Worker.WorkerResult> {
// ... field and constructor omitted
@Override
public WorkerResult call() throws Exception {
try {
long start = System.currentTimeMillis();
for (int i = 0; i < iterations; i++) {
channel.basicPublish("", queue, null, payload);
}
long elapsed = System.currentTimeMillis() - start;
channel.queueDelete(queue);
return new WorkerResult(elapsed);
} finally {
counter.countDown();
}
}
public static class WorkerResult {
public final long elapsed;
WorkerResult(long elapsed) {
this.elapsed = elapsed;
}
}
}
Besides indicating that it has finished its job by decrementing the latch, the worker also returns a WorkerResult instance with the elapsed time to send all messages. Although here we just have a long value, we can use extend it to return more details.
The controller creates the connection factory and workers according to the strategy being evaluated. For the single connection, it creates the Connection instance and passes it to every worker:
@Override
public Long call() {
try {
Connection connection = factory.newConnection();
CountDownLatch counter = new CountDownLatch(workerCount);
List<Worker> workers = new ArrayList<>();
for( int i = 0 ; i < workerCount ; i++ ) {
workers.add(new Worker("queue_" + i, connection, iterations, counter,payloadSize));
}
ExecutorService executor = new ThreadPoolExecutor(workerCount, workerCount, 0,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(workerCount, true));
long start = System.currentTimeMillis();
executor.invokeAll(workers);
if( counter.await(5, TimeUnit.MINUTES)) {
long elapsed = System.currentTimeMillis() - start;
return throughput(workerCount,iterations,elapsed);
}
else {
throw new RuntimeException("Timeout waiting workers to complete");
}
}
catch(Exception ex) {
throw new RuntimeException(ex);
}
}
For the multiple connections strategy, we create a new Connection for each worker:
for (int i = 0; i < workerCount; i++) {
Connection conn = factory.newConnection();
workers.add(new Worker("queue_" + i, conn, iterations, counter, payloadSize));
}
The throughput function calculates the benchmark measure will be the total time needed to complete all workers, divided by the number of workers:
private static long throughput(int workerCount, int iterations, long elapsed) {
return (iterations * workerCount * 1000) / elapsed;
}
Notice that we need to multiply the numerator by 1000 so we get the throughput in messages by second.
7. Running the Benchmark
These are the results of our benchmark for both strategies. For each worker count, we’ve run the benchmark 10 times and used the average value as the throughput measure for tar particular worker/strategy. The environment itself is modest by today’s standards:
- CPU: dual-core i7 dell notebook @ 3.0 GHz
- Total RAM: 16 GB
- RabbitMQ: 3.10.7 running on Docker (docker-machine with 4 GBytes RAM)
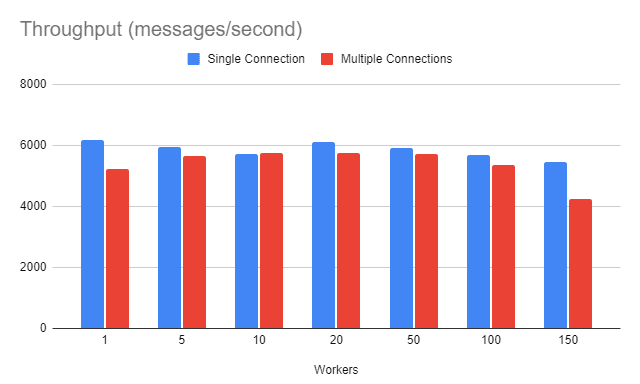
For this specific environment, we see a slight advantage in the single connection strategy. This advantage seems to increase for the 150 workers scenario.
8. Selecting a Strategy
Given the benchmark results, we cannot point to a clear winner. For worker counts between 5 and 100, the results are more or less the same. After that, the overhead associated with multiple connections seems to be higher than handling multiple channels on a single connection.
Also, we must consider that the test workers do only one thing: send fixed messages to a queue. Real-world applications, like the CQRS one we’ve mentioned, usually do some extra work before and/or after sending a message. So, to select the best strategy, the recommended way is to run your own benchmark using a configuration that is as close as possible to the production environment.
9. Conclusion
In this article, we’ve explored the concepts of Channels and Connections in RabbitMQ and how we can use them in different ways.

















