Guide to Choosing Between Protocol Buffers and JSON
Last updated: December 12, 2024


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
All Access is finally out, with all of my Spring courses. Learn JUnit is out as well, and Learn Maven is coming fast. And, of course, quite a bit more affordable. Finally.
>> GET THE COURSESpring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
Protocol Buffers (Protobuf) and JSON are popular data serialization formats but differ significantly in readability, performance, efficiency, and size.
In this tutorial, we’ll compare these formats and explore their trade-offs. This will help us make informed decisions based on the use case when we need to choose one over the other.
2. Readability and Schema Requirements
Protobuf requires a predefined schema to define the structure of the data. It’s a strict requirement without which our application can’t interpret the binary data.
To get a better understanding, let’s see a sample schema.proto file:
syntax = "proto3";
message User {
string name = 1;
int32 age = 2;
string email = 3;
}
message UserList {
repeated User users = 1;
}Further, if we see a sample Protobuf message in base64 encoding, it lacks human readability:
ChwKBUFsaWNlEB4aEWFsaWNlQGV4YW1wbGUuY29tChgKA0JvYhAZGg9ib2JAZXhhbXBsZS5jb20=Our application can only interpret this data in conjunction with the schema file.
On the other hand, if we were to represent the same data in JSON format, we can do it without relying on any strict schema:
{
"users": [
{
"name": "Alice",
"age": 30,
"email": "[email protected]"
},
{
"name": "Bob",
"age": 25,
"email": "[email protected]"
}
]
}
Additionally, the encoded data is perfectly human-readable.
However, if our project requires strict validation of JSON data, we can use JSON Schema, a powerful tool for defining and validating the structure of JSON data. While it offers significant benefits, its use is optional.
3. Schema Evolution
Protobuf enforces a strict schema, ensuring strong data integrity, whereas JSON can facilitate schema-on-read data handling. Let’s learn how both data formats support the evolution of the underlying data schema but in different ways.
3.1. Backward Compatibility for Consumer Parsing
Backward compatibility means new code can still read data written by older code. So, it requires that a newer version correctly deserializes the data serialized using an older schema version.
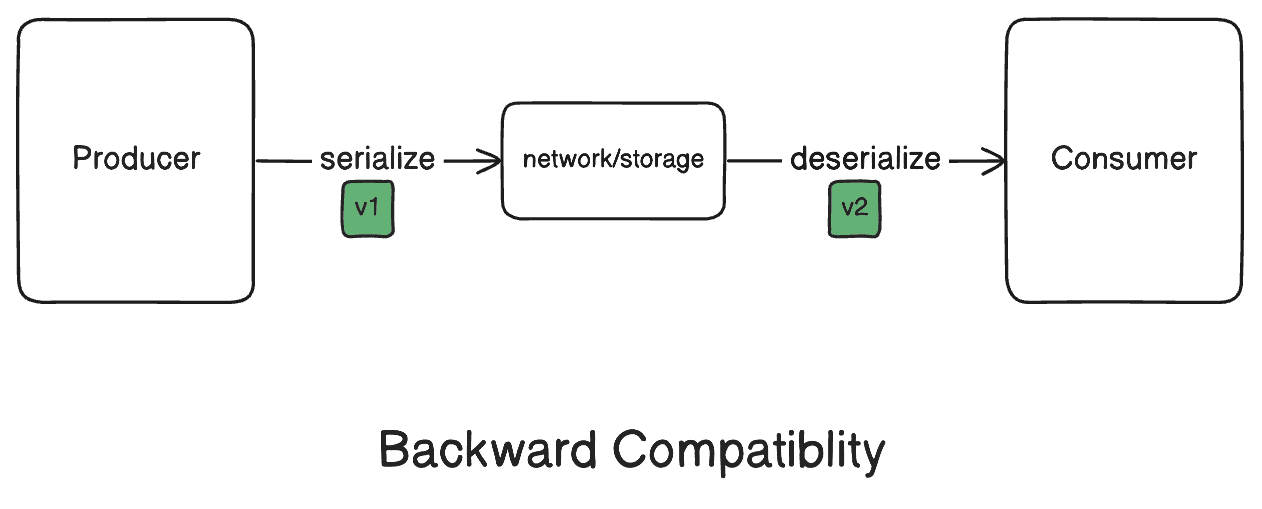
To ensure backward compatibility with JSON, the application should be designed to ignore unrecognized fields during deserialization. In addition, the consumer should provide default values for any unset fields. With Protocol Buffers, we can add default values directly in the schema itself, enhancing compatibility and simplifying data handling.
Further, any schema change for Protobuf must follow best practices to maintain backward compatibility. If we’re adding a new field, we must use a unique field number that wasn’t previously used. Similarly, we need to deprecate unused fields and reserve them to prevent any reuse of field numbers that could break backward compatibility.
Although we can maintain backward compatibility while using both formats, the mechanism for protocol buffers is more formal and strict.
3.2. Forward Compatibility for Consumer Parsing
Forward compatibility means old code can read data written by newer code. It requires that an older version correctly deserialize the data serialized by a newer schema version.

Since the old code cannot anticipate all potential changes to data semantics that may occur, it’s trickier to maintain forward compatibility. For forward compatibility, the old code must ignore unknown properties and depend on the new schema to preserve the original data semantics.
In the case of JSON, the application should be designed to ignore the unknown fields explicitly, which is easily achievable with most JSON parsers. On the contrary, Protocol Buffers has built-in capabilities to ignore unknown fields. So, protobufs can evolve with the assurance that unknown fields will be ignored.
Lastly, it’s important to note that removing mandatory fields would break forward compatibility in both cases. So, the recommended practice involves deprecating the fields and gradually removing them. In the case of JSON, a common practice is to deprecate the fields in documentation and communicate to the consumers. On the other hand, Protocol Buffers allow a more formal mechanism to deprecate the fields within the schema definition.
4. Serialization, Deserialization, and Performance
JSON serialization involves converting an object into a text-based format. On the other hand, Protobuf serialization converts an object into a compact binary format while complying with the definition from the .proto schema file.
Since Protobuf can refer to the schema to identify the field names, it doesn’t need to preserve them with the data while serializing. As a result, the Protobuf format is far more space-efficient than JSON, which preserves the field names.
By design, Protobuf generally outperforms JSON in terms of efficiency and performance. It typically takes up less storage space and generally completes the serialization and deserialization process much faster than the JSON data format.
5. When to Use JSON
JSON is the de facto standard for web APIs, especially RESTful services. This is mainly due to its rich ecosystem of tools, libraries, and inherent compatibility with JavaScript.
Moreover, the text-based nature makes it easy to debug and edit. So, using JSON for configuration data is a natural choice, as configurations should be easy for humans to understand and edit.
Another interesting use case where it’s preferred to use JSON format is logging. Due to its schema-less nature, it provides great flexibility in collecting logs from different applications into a centralized location without maintaining strict schemas.
Lastly, it’s important to note that when working with Protobuf, a special schema-aware client and additional tooling is needed, whereas, for JSON, no special client is needed since JSON is a plain text format. So, we’ll likely benefit from the JSON format while developing a prototype or MVP solution because it allows us to introduce changes with less effort.
6. When to Use Protocol Buffers
Protocol Buffers are pretty efficient for storage and transfer over the network. Additionally, they enforce strict rules for data integrity through schema definition. So, we’re likely to benefit from them for such use cases.
Applications that deal with real-time analytics, gaming, and financial systems are expected to be super-performant. So, we must evaluate the possibility of using Protobuf in such scenarios, especially for internal communications.
Additionally, distributed database systems could benefit from Protobuf’s small memory footprint. So, Protocol Buffers are an excellent choice for encoding data and metadata for efficient data storage and high performance in data access.
7. Conclusion
In this article, we explored the key differences between the JSON and Protocol Buffers data formats to enable informed decision-making while formulating the data encoding strategy for our application.
JSON’s human readability and flexibility make it ideal for use cases such as web APIs, configuration files, and logging. In contrast, Protocol Buffers offer superior performance and efficiency, making them suitable for real-time analytics, gaming, and distributed storage systems.

















