

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
When it comes to collections, the Java standard library provides plenty of options to choose from. Among those options are two famous List implementations known as ArrayList and LinkedList, each with their own properties and use-cases.
In this tutorial, we’re going to see how these two are actually implemented. Then, we’ll evaluate different applications for each one.
2. ArrayList
Internally, ArrayList is using an array to implement the List interface. As arrays are fixed size in Java, ArrayList creates an array with some initial capacity. Along the way, if we need to store more items than that default capacity, it will replace that array with a new and more spacious one.
To better understand its properties, let’s evaluate this data structure with respect to its three main operations: adding items, getting one by index and removing by index.
2.1. Add
When we’re creating an empty ArrayList, it initializes its backing array with a default capacity (currently 10):

Adding a new item while that array it not yet full is as simple as assigning that item to a specific array index. This array index is determined by the current array size since we’re practically appending to the list:
backingArray[size] = newItem;
size++;So, in best and average cases, the time complexity for the add operation is O(1), which is pretty fast. As the backing array becomes full, however, the add implementation becomes less efficient:
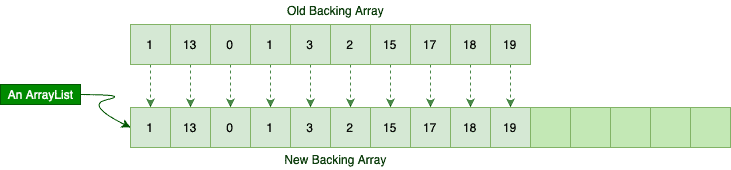
To add a new item, we should first initialize a brand new array with more capacity and copy all existing items to the new array. Only after copying current elements can we add the new item. Hence, the time complexity is O(n) in the worst case since we have to copy n elements first.
Theoretically speaking, adding a new element runs in amortized constant time. That is, adding n elements requires O(n) time. However, some single additions may perform poorly because of the copy overhead.
2.2. Access by Index
Accessing items by their indices is where the ArrayList really shines. To retrieve an item at index i, we just have to return the item residing at the ith index from the backing array. Consequently, the time complexity for access by index operation is always O(1).
2.3. Remove by Index
Suppose we’re going to remove the index 6 from our ArrayList, which corresponds to the element 15 in our backing array:
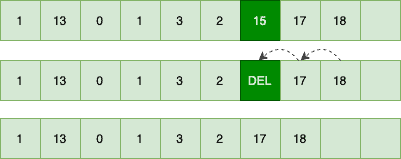
After marking the desired element as deleted, we should move all elements after it back by one index. Obviously, the nearer the element to the start of the array, the more elements we should move. So the time complexity is O(1) at the best-case and O(n) on average and worst-cases.
2.4. Applications and Limitations
Usually, ArrayList is the default choice for many developers when they need a List implementation. As a matter of fact, it’s actually a sensible choice when the number of reads is far more than the number of writes.
Sometimes we need equally frequent reads and writes. If we do have an estimate of the maximum number of possible items, then it still makes sense to use ArrayList. If that’s the case, we can initialize the ArrayList with an initial capacity:
int possibleUpperBound = 10_000;
List<String> items = new ArrayList<>(possibleUpperBound);This estimation may prevent lots of unnecessary copying and array allocations.
Moreover, arrays are indexed by int values in Java. So, it’s not possible to store more than 232 elements in a Java array and, consequently, in ArrayList.
3. LinkedList
LinkedList, as its name suggests, uses a collection of linked nodes to store and retrieve elements. For instance, here’s how the Java implementation looks after adding four elements:

Each node maintains two pointers: one pointing to the next element and another referring to the previous one. Expanding on this, the doubly linked list has two pointers pointing to the first and last items.
Again, let’s evaluate this implementation with respect to the same fundamental operations.
3.1. Add
In order to add a new node, first, we should link the current last node to the new node:

And then update the last pointer:

As both of these operations are trivial, the time complexity for the add operation is always O(1).
3.2. Access by Index
LinkedList, as opposed to ArrayList, does not support fast random access. So, in order to find an element by index, we should traverse some portion of the list manually.
In the best case, when the requested item is near the start or end of the list, the time complexity would be as fast as O(1). However, in the average and worst-case scenarios, we may end up with an O(n) access time since we have to examine many nodes one after another.
3.3. Remove by Index
In order to remove an item, we should first find the requested item and then un-link it from the list. Consequently, the access time determines the time complexity — that is, O(1) at best-case and O(n) on average and in worst-case scenarios.
3.4. Applications
LinkedLists are more suitable when the addition rate is much higher than the read rate.
Also, it can be used in read-heavy scenarios when most of the time we want the first or last element. It’s worth mentioning that LinkedList also implements the Deque interface – supporting efficient access to both ends of the collection.
Generally, if we know their implementation differences, then we could easily choose one for a particular use-case.
For instance, let’s say that we’re going store a lot of time-series events in a list-like data structure. We know that we would receive bursts of events each second.
Also, we need to examine all events one after another periodically and provide some stats. For this use-case, LinkedList is a better choice because the addition rate is much higher than the read rate.
Also, we would read all the items, so we can’t beat the O(n) upper bound.
4. Conclusion
In this tutorial, first, we took a dive into how ArrayList and LinkLists are implemented in Java.
We also evaluated different use-cases for each one of these.

















