Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: May 24, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll show how to find the central nodes of a tree.
The graph theory defines a tree center as the node with minimal eccentricity (the length of the longest path to any other node):
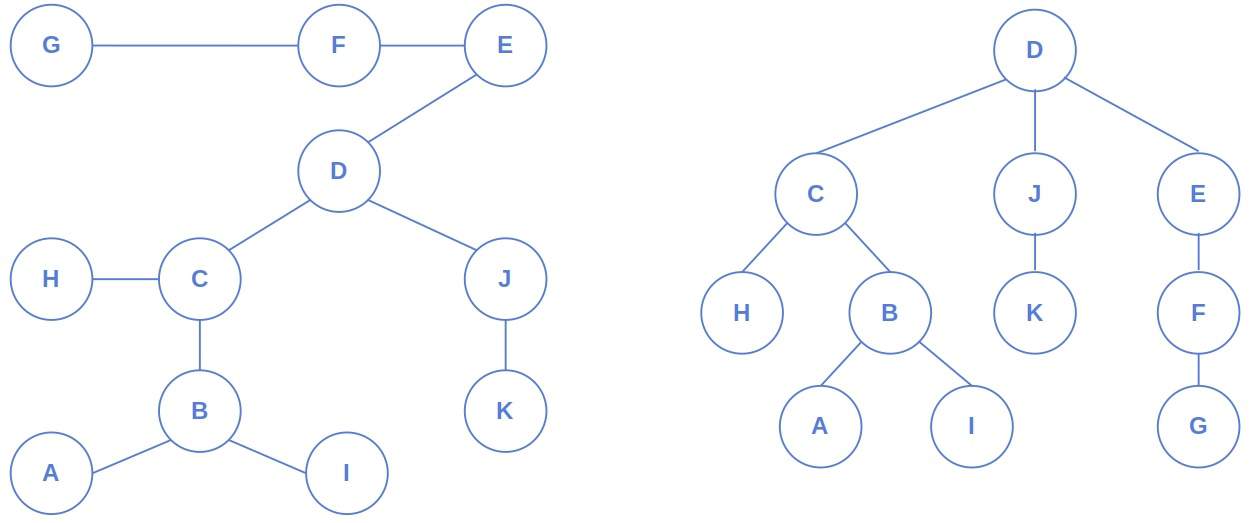
On the left, we have an undirected and unrooted tree. On the right, we see the same tree rooted at its center.
That’s why we care about tree centers. Sometimes, we are given a tree as a regular graph, so no node is marked as the root. Our job is to root the tree, and doing so at the central node pays off in many applications.
We’ll assume that the trees we’re working with are unweighted, undirected, and unrooted.
The diameters of a tree are the longest paths in it. As we saw, there can be more than one. We can prove that the center of a tree must lie in the middle of its diameter(s).
Let  and
and  be the endpoints of a diameter containing an odd number of nodes, and let
be the endpoints of a diameter containing an odd number of nodes, and let  be its middle node.
be its middle node.
Let another node  be the tree’s center and
be the tree’s center and  the diameter node closest to
the diameter node closest to  :
: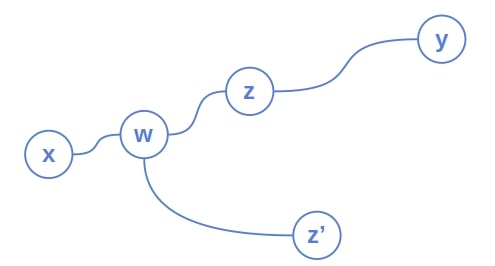
Depending on whether is between and or and , either the path  is longer than
is longer than  or
or  than
than  . That’s impossible since, by our assumption, has the minimum eccentricity. So, can’t be the center, which means that must be.
. That’s impossible since, by our assumption, has the minimum eccentricity. So, can’t be the center, which means that must be.
If the diameter contains an even number of nodes, there are two middle nodes, and both will be the tree’s centers.
That gives us an idea of how to find the center(s) in unweighted trees.
Since central nodes are in the middle of a diameter, we can start by removing the endpoint nodes one layer at a time until we reach the middle nodes.
Each node in the outmost layer has only one neighbor, which we can call its parent. If we remove the surface nodes, their parents will have only one neighbor. As we move toward the center, the eccentricity decreases by one since all the edges have the same cost (1). So, we repeat this process by moving inward until we get one or two central nodes:
algorithm FindingCenterOfUnweightedTree(T):
// INPUT
// T = an undirected, unrooted, and unweighted tree
// OUTPUT
// The center of T if T is not empty, an empty set otherwise
if T is empty:
return empty set
degrees <- the nodes degrees
surface <- find the nodes with only 1 neighbor
while |surface| > 2:
inner <- empty set
for node in surface:
parent <- the only neighbor of node
degrees[parent] <- degrees[parent] - 1
if degrees[parent] = 1:
inner <- inner union {parent}
surface <- inner
return surfaceAlthough we assume the tree is unrooted, this algorithm implicitly defines its structure. The nodes it processes in the same iteration belong to the same level. Those processed in iteration  are the parents of the nodes handled in iteration
are the parents of the nodes handled in iteration  , and the tree’s center becomes its root.
, and the tree’s center becomes its root.
Let’s run an example. In the first iteration, the surface nodes are  ,
,  ,
,  ,
,  , and
, and  :
:
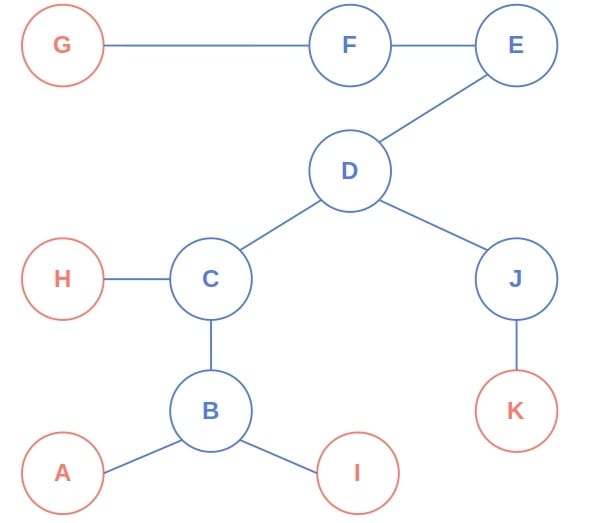
In the second one, those are  ,
,  , and
, and  :
:
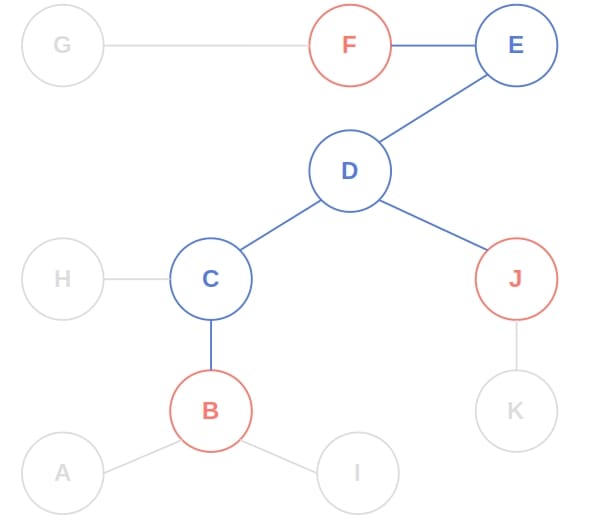
We process  and
and  in the third iteration and leave the loop with
in the third iteration and leave the loop with  as the found center.
as the found center.
Let  be the tree we get by removing the th iteration’s surface layer from
be the tree we get by removing the th iteration’s surface layer from  . Those trees are implicit: we don’t construct them but can derive them during the algorithm’s execution.
. Those trees are implicit: we don’t construct them but can derive them during the algorithm’s execution.
Our loop invariant is that  has the same center nodes as the input tree
has the same center nodes as the input tree  . Let’s prove it by induction.
. Let’s prove it by induction.
The base case is  , i.e., the situation before the main loop, which trivially holds:
, i.e., the situation before the main loop, which trivially holds:  has the same centers as itself.
has the same centers as itself.
Let’s assume that the invariant is true at the end of the th iteration. Does it hold at the end of the iteration ? In other words, do  and have the same centers?
and have the same centers?
We can show that’s the case by noting that a diameter’s endpoints have the degree one. If we remove such nodes from , all the diameters will shrink by a node from both sides. So, those in the middle will stay the same. As a result, and have the same centers.
Consequently, the nodes we end up with are ‘s central nodes. There can be two centers at most because each diameter has either one or two middle nodes. Furthermore, we’ve shown that the diameters intersect at the centers!
No node in an  -ary tree has more than
-ary tree has more than  neighbors. In the worst case, a node’s edges are in a linked list, so we need to traverse it to find its degree. In such a tree with
neighbors. In the worst case, a node’s edges are in a linked list, so we need to traverse it to find its degree. In such a tree with  nodes, computing the degrees takes
nodes, computing the degrees takes  time. If is a constant, that will reduce to
time. If is a constant, that will reduce to  . Similarly, if we store neighbors in an array, we can read its length in
. Similarly, if we store neighbors in an array, we can read its length in  time, which gives the overall complexity of .
time, which gives the overall complexity of .
Further, each edge is processed in the main loop only once. Since a tree with nodes has  edges, the loop’s time complexity is .
edges, the loop’s time complexity is .
So, this algorithm runs in linear time.
In this article, we showed how to find an unweighted tree’s central nodes in linear time. They are in the middle of the longest path(s), and there are at most two centers in each tree.